PrometheusとCNCF、Observability
PrometheusとCNCF
PrometheusはCNCF(Cloud Native Computing Foundation)という組織のプロジェクトの一つとしてホストされている。Linux Foundationを知っている人も多いと思うが、CNCFはこのLinux Foundationの組織の一つであり、クラウドネイティブなオープンソースプロジェクトを推進する組織である。クラウドネイティブに必要なさまざまなソフトウェアをもっと使っていき、それらが成長していくように推進し、支援していくコミュニティがCNCFである。
CNCF Webサイト
実はPrometheusは、このCNCFの2番目のGraduated Projectである。Graduated Projectとは何かというと、いわゆる「卒業プロジェクト」とよく言われるものである。
CNCFのプロジェクトには主に3段階があり、下からSandbox、Incubating、Graduatedの3つがある。Sandboxが最も若く、出てきたばかりで、将来性はあるもののまだバグも多く、メンテナーも少ないなど、まだ成熟していないと判断される、いわば利用者が限定されるプロジェクトである。Incubating Projectは、ある程度認知度も上がり、ソフトウェアとしても完成してきたが、コミュニティの状態やソフトウェアの成熟度がまだ十分ではない段階だといえる。
最後に、これらをある程度満たした状態、単にソフトウェアそのものの成熟度だけでなく、それを取り巻くコミュニティやメンテナンスの継続性など、さまざまな観点から、このソフトウェアは今後独立して十分にやっていける、CNCFが支援しなくても十分に成立するプロジェクトになったと判断された状態がGraduatedである。Prometheusは、このGraduated Projectの2番目のプロジェクトとして認められた。したがって、Prometheusは登場してからすでにかなり時間が経っており、卒業プロジェクトの一つでもあるため、多くの場所で使われ始めている。
また、CNCFプロジェクトの3段階は、イノベーション理論と非常によく一致する。Sandboxプロジェクトはイノベーター、Incubatingはアーリーアダプター、Graduated Projectはアーリーマジョリティ以降の層が使う形だといえる。
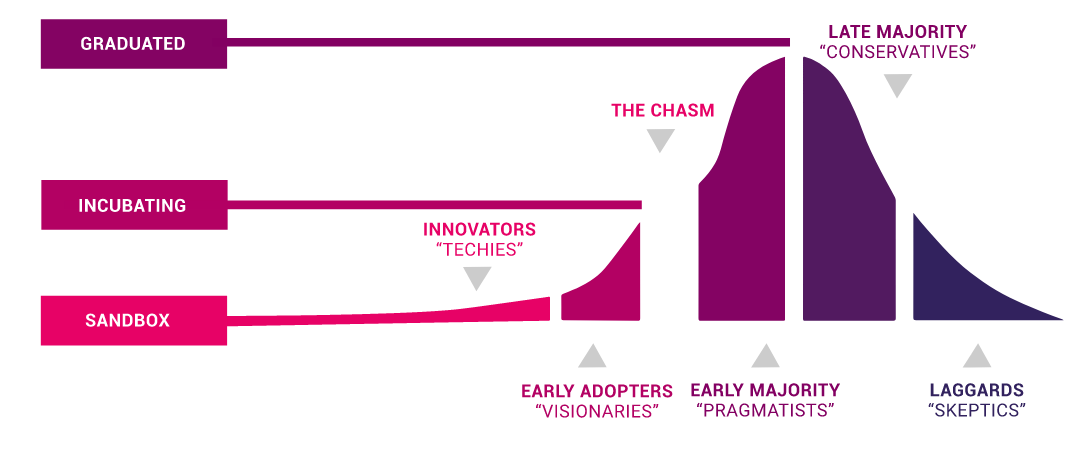
CNCFプロジェクトの段階とイノベーション理論の関係(出典)
イノベーター理論にはキャズム(Chasm)というものがある。アーリーアダプターからアーリーマジョリティへ進む間に、最後に越えなければならない一歩があると考えられており、これを越えたということは、ある程度の人々が使ってもよい、つまりエンタープライズシステムのようにそれなりに実証されたものを使いたい人でも利用できるプロジェクトとして認められたということである。Prometheusは、非常に成熟度が高くなっているプロジェクトの一つでもある。
ただし、たとえばZabbixのようにかなり安定して枯れているかというと、まだそうではない。Zabbixと比べれば歴史は短いが、その中でも比較的多くの人に使ってもらえるソフトウェアの一つだと考えられる。
Observabilityとは?
ここまで、Prometheusはある程度成熟したクラウドネイティブ監視ソフトウェアである、という話をしてきた。クラウドネイティブを語るうえでよく出てくるキーワードには、コンテナ、サービスメッシュ、マイクロサービスなどがあるが、特にPrometheusを使ううえで意識しておくとよいものとして「Observability(オブザーバビリティ)」というキーワードがある。そもそも「クラウドネイティブとは何か?」についてはCNCFのサイトで公開されている内容をぜひ調べてほしいが、その中でもこのObservabilityを挙げることができる。ではObservabilityとは何か、という点を少し深く見ていく。
Observabilityについて話す前に、一つ注意しておきたいことがある。Observabilityという言葉は、実は人によって意味が異なる。つまり、ここで話す「Observabilityとはこういうものだ」という意見や解釈は、人によって違ったり、別の視点があったりする。したがって、ここで述べることがすべてではなく、「ここではこのようにObservabilityを考えているのだ」と受け止めてもらうとよい。
 出典: Distributed Systems Observability
出典: Distributed Systems Observability
Observabilityは日本語では「観測可能性」と訳される。これはシステムの状態を取得し、その状態を見られる、つまり観測可能な状態にすることを意味する。このObservability、つまりシステムの状態を取得して見えるようにするとは何かについて、さらに見ていく。
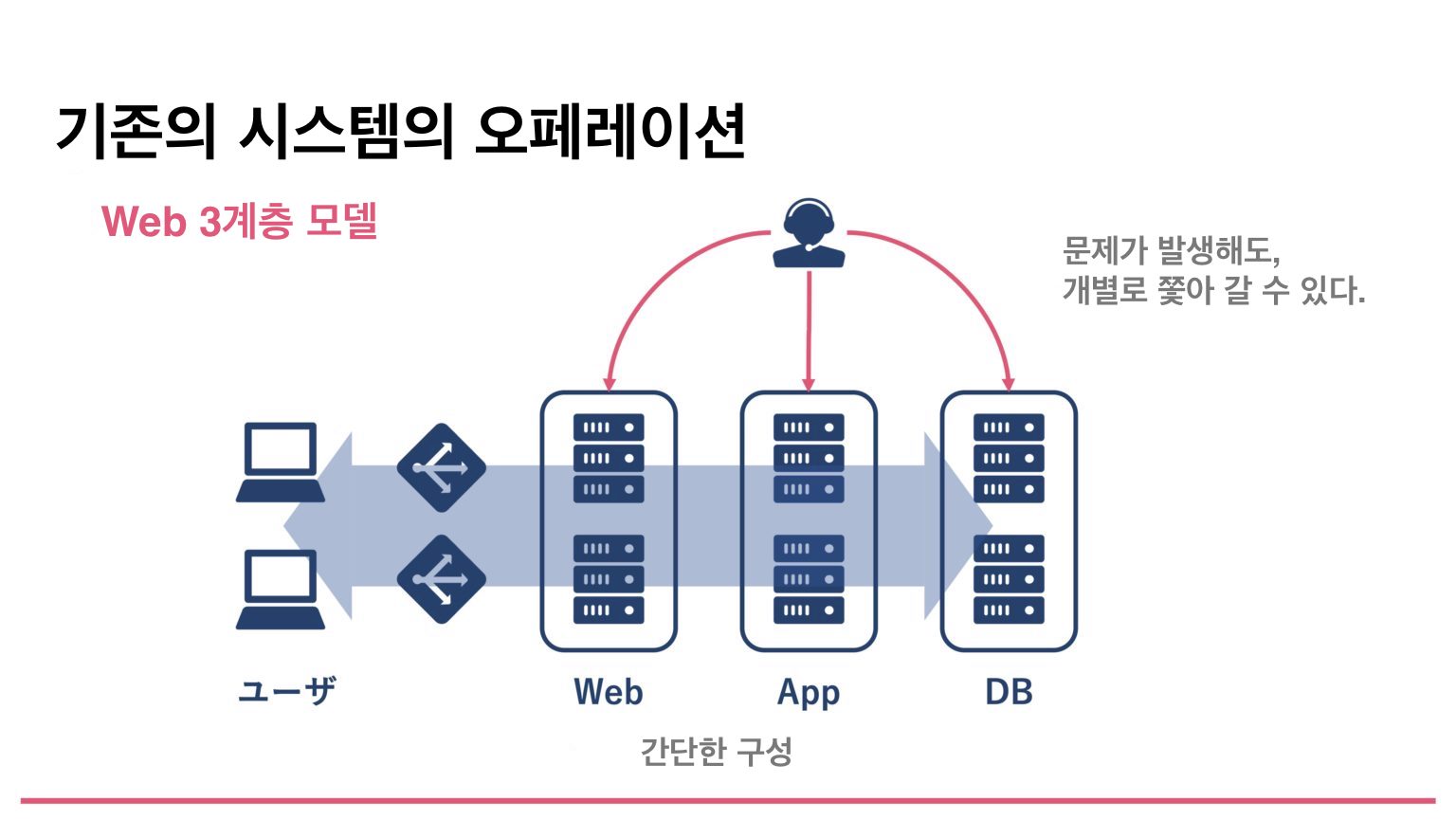
以前の例でいえば、10年前のシステムはWeb 3階層モデルと呼ばれ、ロードバランサー、Webサーバー、アプリケーションサーバー、データベースがある、下図のような単純な3階層モデルが多かった。このようなシステムで障害が発生しても、それぞれのコンポーネントレベルで追跡できるため、障害のトラブルシューティングは比較的容易に行えた。
しかし近年は、Kubernetesをはじめ、マイクロサービスと呼ばれるものが全盛の時代である。このような分散システムでは、小さなサービスを組み合わせて利用する。システム内に大量のコンポーネントが存在しているため、障害が発生したときに一つずつ人が手作業で追っていくことは非常に難しくなった。ほとんど無理だといえる。
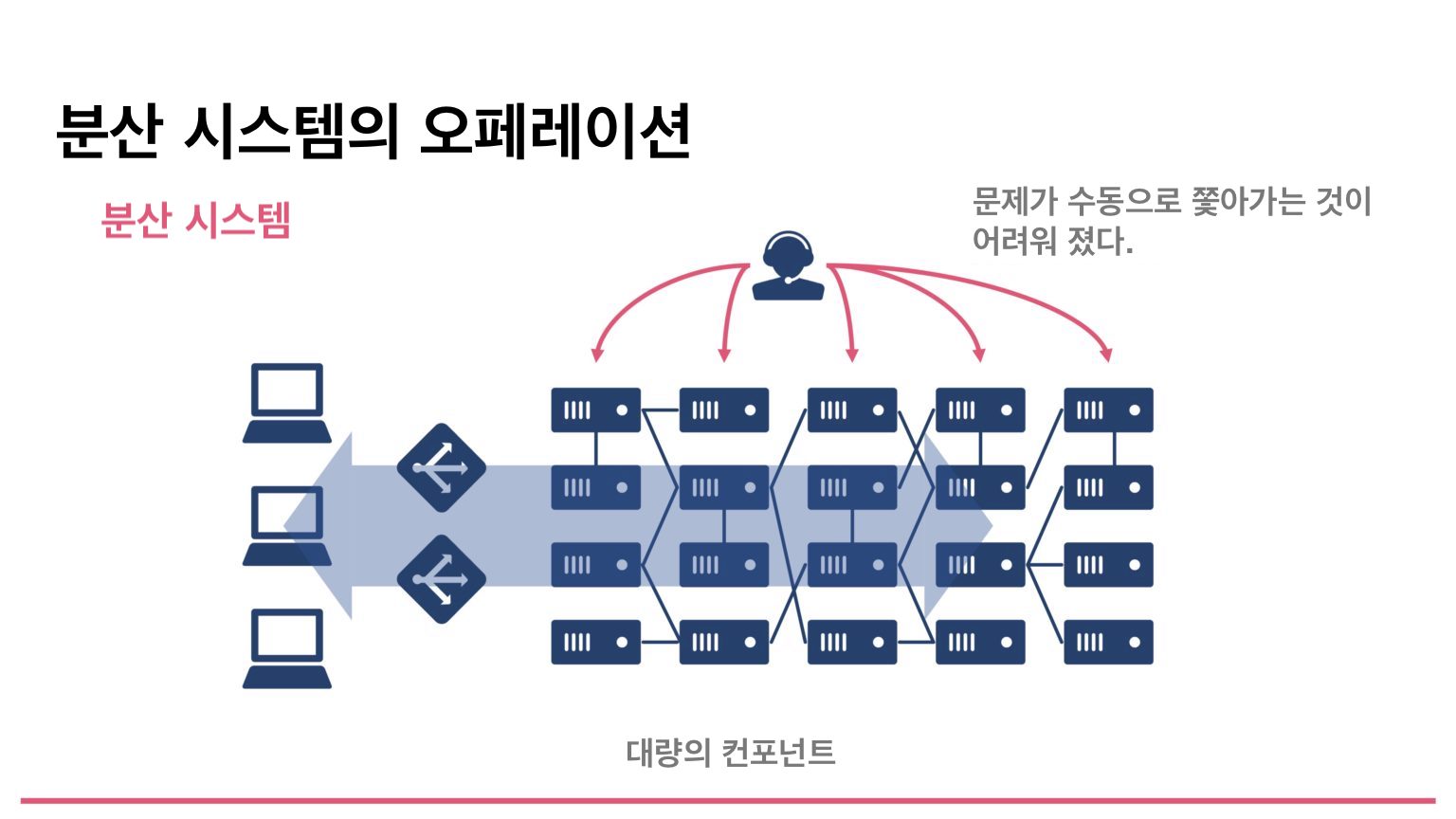
とても良い例がある。それはTwitterの分散システムである。下の円状に広がっている、とげのような一つ一つが実はシステム名である。その円の中に描かれている一本一本の線は、システム間の接続を表している。このように、ある程度大規模なシステムになると構成は非常に複雑になる。これらを人の手で一つ一つ追うのは無理である。そこで、このようなシステムの状態をきちんと横断的に見えるようにしよう、というのがObservabilityである。
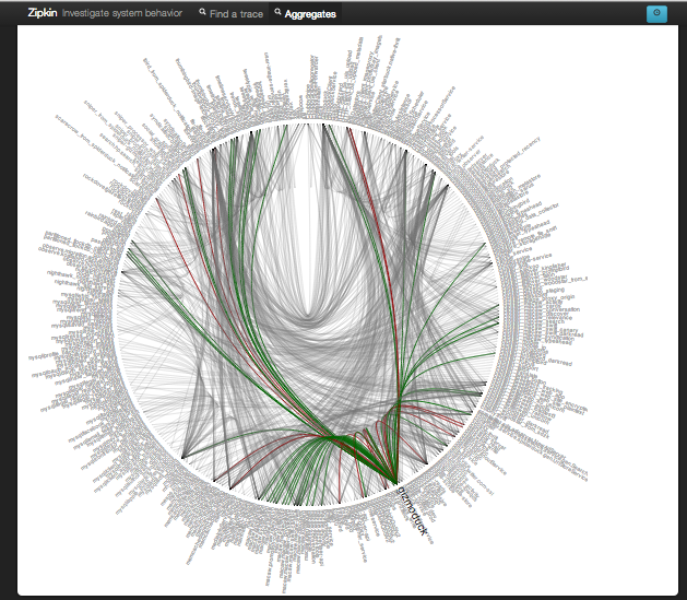
Twitter分散システム(出典: Observability at Twitter)
したがって、Prometheusを単なる監視ツールとして使うこと自体はまったく問題ない。ただし、Prometheusを使っていくうえで覚えておきたいのは、PrometheusはObservabilityを実現する要素の一つだという点である。さまざまなコンポーネントを一つずつ手動で登録するのではなく、Service Discoveryを使って簡単に登録できる。そうすることで、これまで人が手動で行っていた作業を自動化し、ある程度システム側に任せられるようになり、クラウドネイティブに近づけると考えられる。
ObservabilityとPrometheus
続いて、ObservabilityとPrometheusについて話す。Observabilityを語るうえで、また新しい言葉が出て恐縮だが、注意しておくべき用語がある。「Telemetry(テレメトリー)」という用語である。Telemetryとは、Observabilityを実現するためのツールに求められる要素の一つである。ObservabilityとTelemetryは同じものではない。あくまで要素の一つとして解釈される。
したがって、Telemetryを実現するツールを導入すること自体がObservabilityの実現ではない。つまり、Prometheusを使ったからObservabilityを実現できた、というわけではない。Prometheusはあくまでそれを実現するためのツールであり、Prometheusを使うだけでなく、それを活用してどのようにObservabilityを実現していくか、システムの状態を横断的に見えるようにするかが、Observabilityを作っていくうえでの目的だといえる。
Telemetryを語るときに出てくる要素には、Metrics、Logging、Tracingの3つがある。Metricsは知っている人もいると思うが、たとえばZabbixなどもMetricsを使用しており、世の中の監視システムの多くはMetricsを前提としている。次にLoggingだが、これも当然使われていると思う。ここであまり見慣れない用語はTracingである。分散トレーシングもかなり前からある言葉だが、あまり馴染みがないかもしれない。
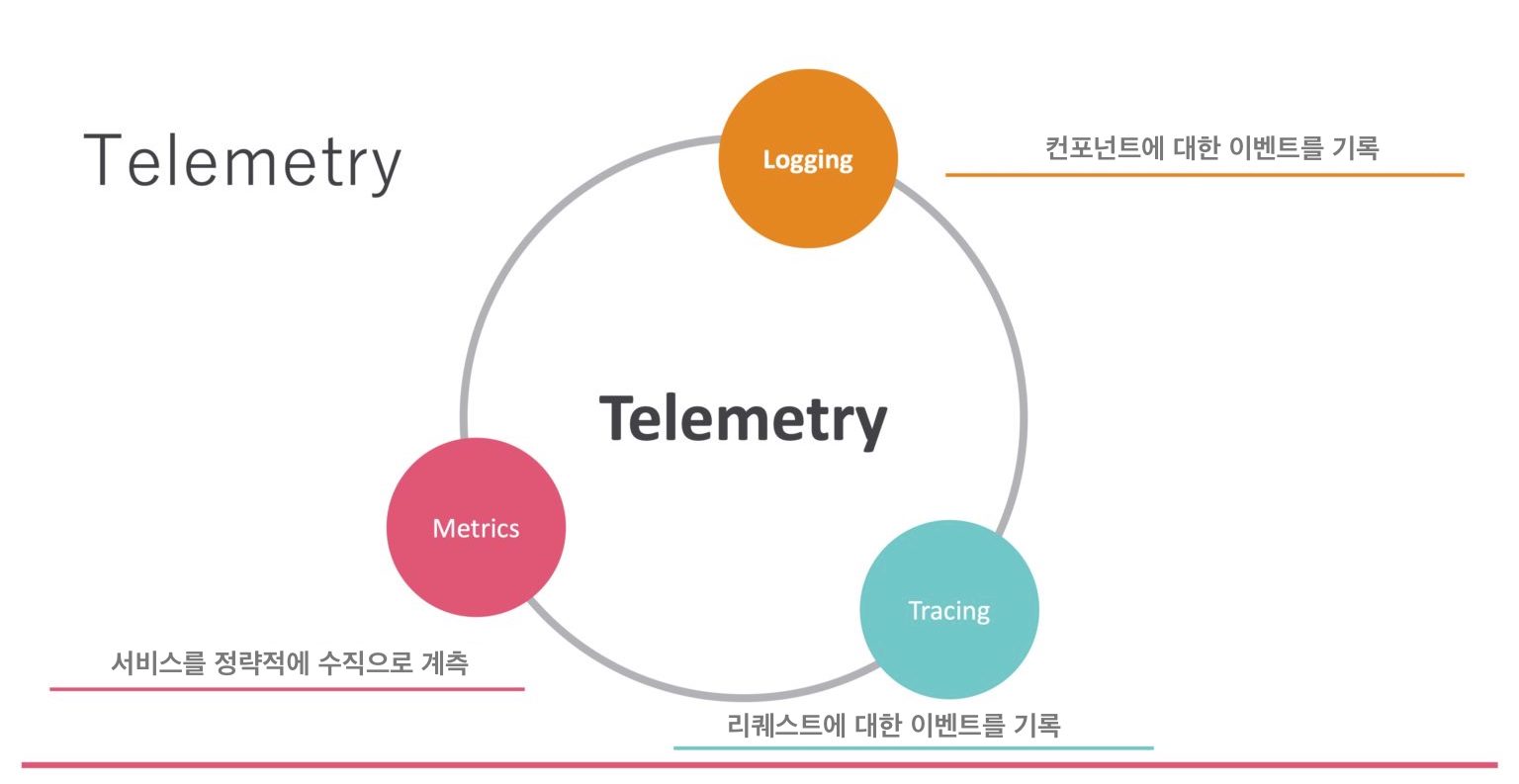
Observabilityを実現するには、この3つの要素を適切に扱う必要がある。ではPrometheusがこれらすべてを実現できるのかというと、そうではない。Prometheusはこの中の一要素、具体的にはMetricsを実現するためのツールである。このMetricsとは連続的な数値データである。たとえば、メモリ使用量があるタイミングでは1GB、別のタイミングでは2GB、それが3GBになり、また2GBに戻る、といった連続的なデータであり、それが時系列に並んでいるようなデータである。
このようなデータは比較的構造が単純なため、統計的な集計が可能である。たとえば、ある時間全体を見て、実際にどのような変化があったのか、あるいはシステムリソースの使用量がどの程度だったのかを集計できる。また、その集計によって、たとえば毎週金曜日にMetricsが大きく上昇しているので、皆が業務終了後にWebサイトへアクセスしているのだとわかり、対策としてサービスをスケールアップしたり、対応するインスタンスを追加したりできる。つまり、Prometheusを活用すると、Metricsを使った集計と傾向予測ができるようになる。
次は
次は、Prometheusを実際に始めるにはどうすればよいかについて見ていく。