Prometheus와 CNCF, Observability
Prometheus와 CNCF
Prometheus는 CNCF(Cloud Native Computing Foundation)라는 조직 프로젝트 중 하나로 호스팅된다. Linux Foundation을 아시는 사람도 많을까 생각되지만, CNCF는 이 Linux Foundation의 조직 중 하나이며 클라우드 네이티브 오픈 소스 프로젝트를 추진하는 조직이다. 클라우드 네이티브 없이도 되는 다양한 소프트웨어를 점점 사용해 가자, 그것이 점점 성장가도록 추진해 나갈거야, 뒷받침해 주어 나가도록 도울거라고 하는 커뮤니티가 CNCF이다.
CNCF 웹사이트
사실 Prometheus는 이 CNCF의 두 번째 Graduated Project이다. Graduated Project란 무엇인가 하면, 소위 “졸업 프로젝트"라고 하는 식으로 자주 말해진다.
CNCF의 프로젝트에는 주로 3단계가 있으며, 아래에서 Sandbox(샌드박스), Incubating(인큐베이션), Graduated의 3개가 있다. Sandbox가 가장 젊고, 나온지 얼마 안됐고, 아직 미래성은 있지만 버그도 많고, 메인터너(maintainer)도 적어 그런 점에서 아직 깊지 않다고 판단되는 이른바 사용하는 사람이 한정되는 프로젝트이다. Incubating Project는 어느 정도 인지도도 늘어나고 소프트웨어로도 완성되어 왔지만, 커뮤니티의 상태라든지 혹은 소프트웨어의 성숙도가 부족한 단계라고 할 수 있다.
마지막으로, 이들을 어느 정도 만족한 상태, 이것은 단순히 소프트웨어 그 자체의 성숙도 이외에도 거기를 둘러싼 커뮤니티라든지, 유지 보수의 연속성이라든지, 여러가지 관점에서, 이 소프트웨어는 이후 독립하여 충분하다고 할 수 있고, CNCF가 뒷받침을하지 않아도 충분히 할 수 있는 프로젝트가 되었다고 하는 상태가 된 것이 Graduated라고 하는데, Prometheus는 이 Graduated Project의 두 번째 프로젝트로 인정되었다고 한다. 그러므로, 실제 Prometheus는 나온지 벌써 꽤 오래 되었고, 졸업 프로젝트의 하나이기도 하므로 여러 곳에서 사용되기 시작하고 있다.
또한, CNCF 프로젝트의 3단계는 혁신 이론이라고 불리는 것과 매우 일치한다. Sandbox 프로젝트는 혁신가(innovator). Incubating은 얼리 어답터(Early Adopter). Graduated Project는 초기 다수자(Early Majority) 이후의 형태로 그러한 층의 사람들이 사용한다고 한다.
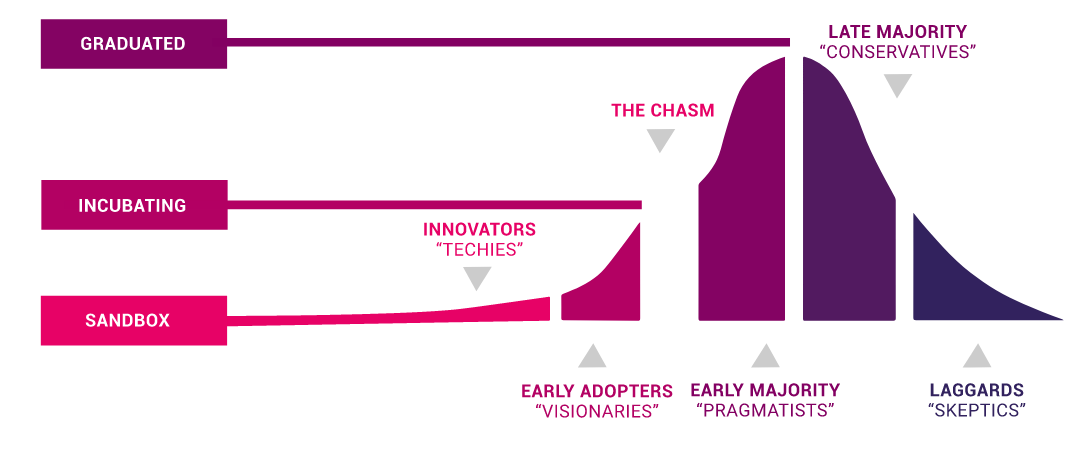
CNCF 프로젝트의 단계와 혁신 이론의 관계 (출처)
이노베이터 이론에는 캐즘(Chasm)이라는 것이 있다. 얼리 어댑터에서 초기 다수자에 가는 사이에, 마지막에 넘어야만 하는 한 발 밟는 것이 있다고 생각되는데, 이것을 넘었다고 하는 것은 이제 어느 정도의 사람들이 사용해도 좋다, 이는 엔터프라이즈 시스템처럼 나름대로 입증된 것을 사용하고 싶은 사람들이라도 사용할 수 있는 프로젝트로서 인정되었다고 하는 것으로, Prometheus는 매우 성숙도가 높아지고 있는 프로젝트의 하나이기도 하다.
다만, 예를 들면, Zabbix와 같이 상당히 안정이고 시들어 있는가 하면, 아직 그런 것은 아니기 때문에, Zabbix와 비교하면 아직 역사는 짧지만, 그런 중에서도 비교적 여러분에게 사용해 주실 수 있는 소프트웨어의 한가지라고 생각한다.
Observability란?
그래서 Prometheus는 어느 정도 성숙하고 클라우드 네이티브 모니터링 소프트웨어라는 이야기를 해왔다. 이 클라우드 네이티브를 말하는데 있어서 자주 나오는 키워드로는, 컨테이너라든지 서비스 메쉬라든지 마이크로 서비스등이 있지만, 특히 Prometheus를 사용하는데 있어서 의식하는 것이 좋은 것으로 “Observability(옵서버빌리티)“라고 하는 키워드 있다. 원래 “클라우드 네이티브란 무엇인가?“라고 하는 것을 CNCF의 사이트에서 공개되고 있는 것을 꼭 조사해 주었으면 하지만, 그 중에서도 이 Observability라고 하는 것을 들 수 있다. 이 Observability는 무엇입니까? 라는 점도 조금 깊은 알아가려고 한다.
그래서 Observability를 말하고 싶지만, 그 전에 1개, 여러분에게 주의할 것이 있다. Observability라는 단어는 실은 사람에 따라 의미가 다르다. 즉, 앞으로 여기서 이야기를 하는 “Observability는 이런 것이다"라고 하는 의견이나 해석이라고 하는 것은, 사람에 따라서 다르다든가 어떤 사람은 다른 시점이라든가 한다. 그러므로 여러분에게 있어서는 여기서 말한 것이 전부는 아니고, “아, 여기에서는 이런 식으로 Observability를 생각하고 있다"라고 하는 식으로 봐 주시면 좋겠다.
 출처: Distributed Systems Observability
출처: Distributed Systems Observability
Observability라는 말은 한국어로 하면 “관측 가능성"이지만, 이는 시스템의 상태를 받아와서 상태를 볼 수 있는 즉, 관측이 가능한 상태로 하는 것을 관측 가능성, Observability로 정의한다. 이 Observability는 시스템의 상태를 받아와서 보이게 하는 것은 무엇인가에 대해서 더 알아 보도록 하겠다.
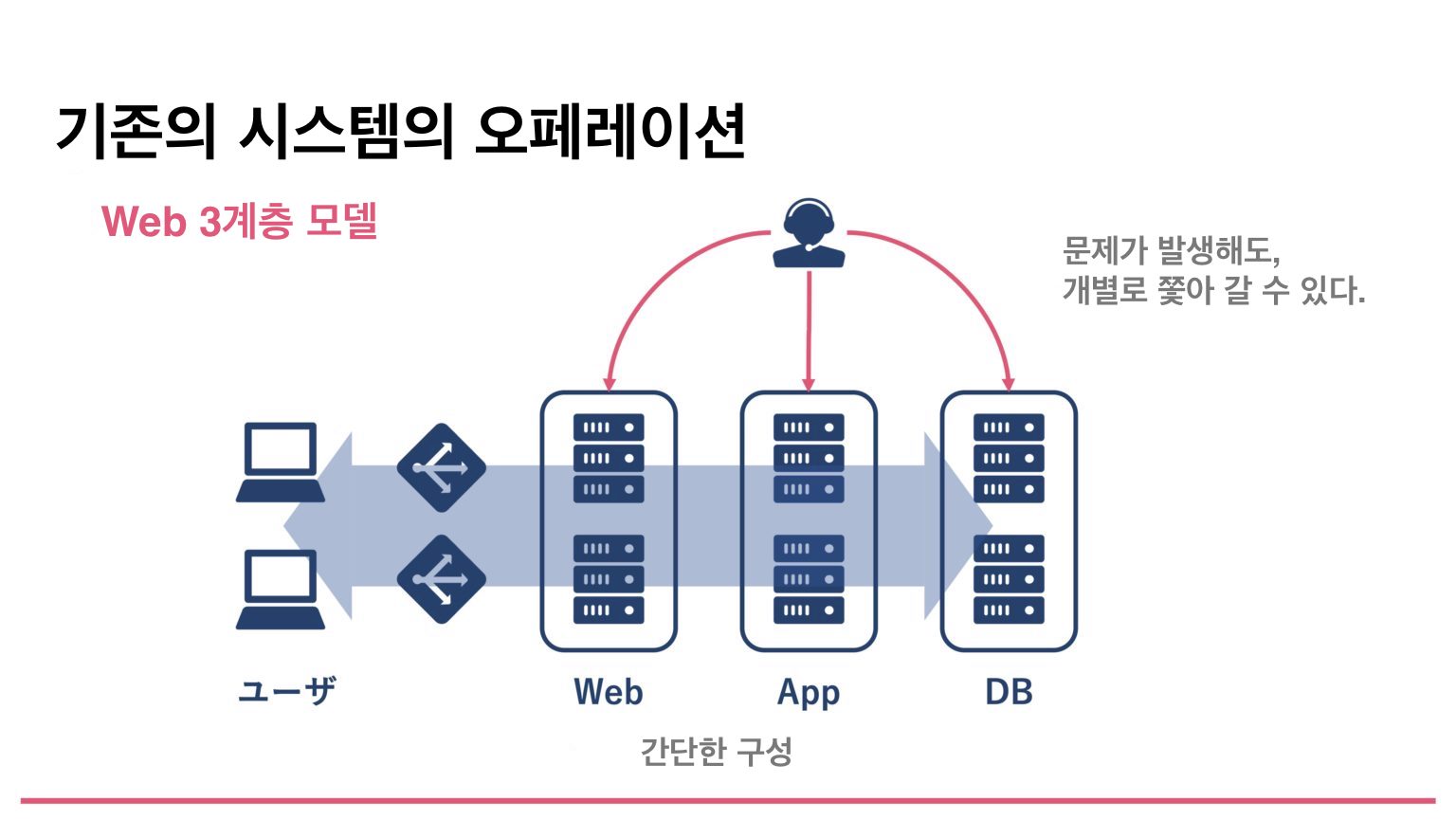
예전에 예를 든다면, 10년전의 시스템은 Web 3계층 모델이라고 하여 로드 밸런서가 있고, Web 서버, 어플리케이션 서버, 데이터베이스가 아래 그림과 같은 간단한 3계층 모델이 많았었다. 만약 이러한 시스템에서 장애가 발생하더라도, 각각의 컴포넌트 레벨에서 쫓아갈 수 있기 때문에, 장애의 트러블 슈팅은 비교적 용이하게 수행 할 수 있었다.
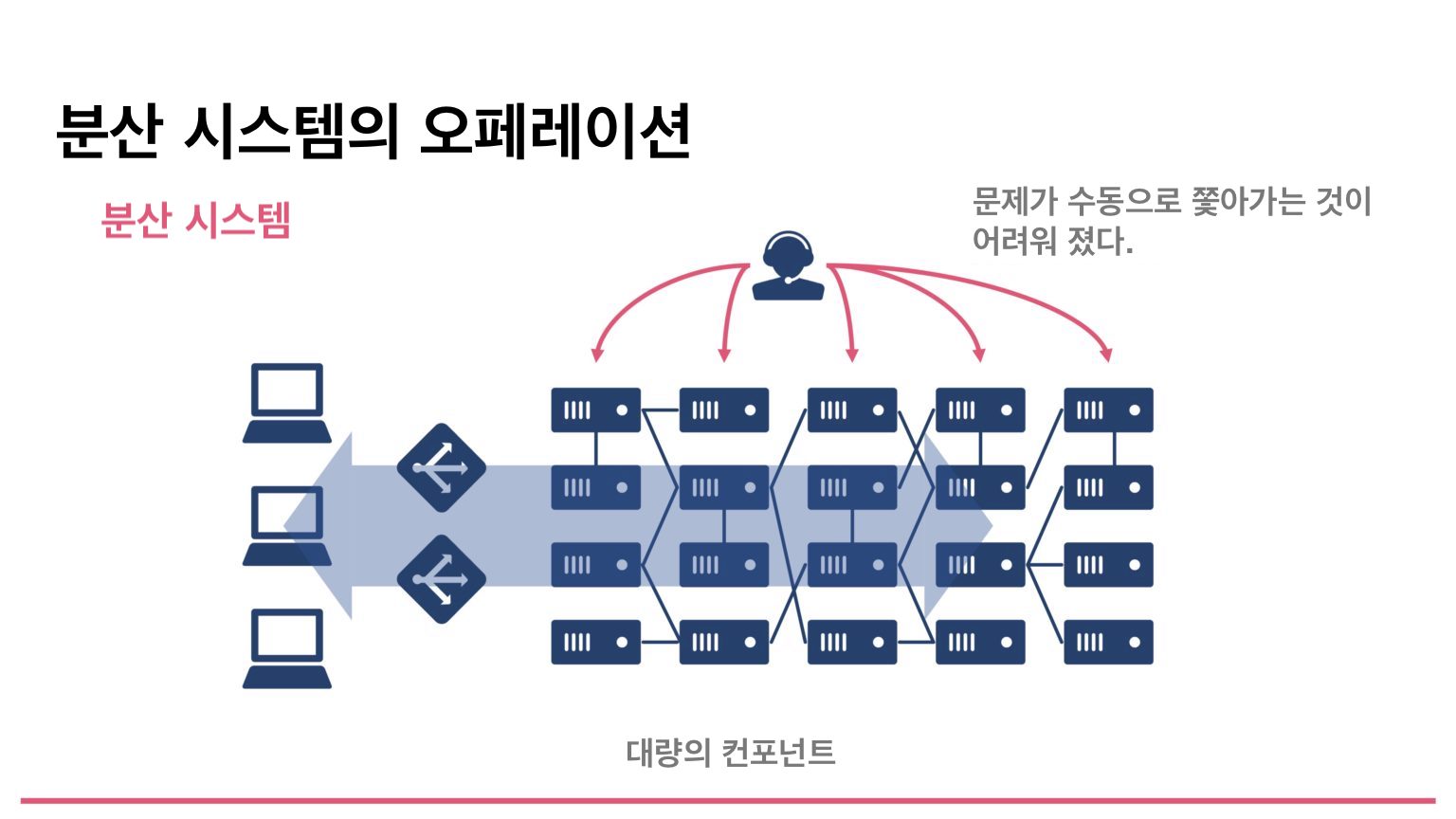
그러나 최근에는 Kubernetes를 비롯해 마이크로 서비스라고 불리는 것이 전성의 시대이다. 이러한 분산 시스템에서는 작은 서비스를 조합하여 사용한다. 시스템내에 대량의 컴퍼넌트가 존재하고 있기 때문에, 장애가 발생했을 때에 1개씩 1개씩을 사람이 수동으로 쫓는다고 하는 것은 매우 어려워졌다. 거의 무리라고 할 수 있다.
매우 좋은 예가 있는데, 그것은 Twitter의 분산 시스템이다. 아래 원으로 넓게 퍼져있는 삐쭉삐죽 가시처럼 되어 있는 하나 하나가 실은 시스템 이름이다. 그 원 안에 그려진 하나 하나의 선은 시스템 간의 연결이다. 이와 같이, 어느 정도 대규모 시스템이 되면 구성은 매우 복잡해 진다. 이것들을 사람의 손으로 하나하나 쫓아가는 것은 무리이다. 그런데 이러한 시스템의 상태를 제대로 횡단적으로 보이도록 하자는 것이 Observability라는 것이다.
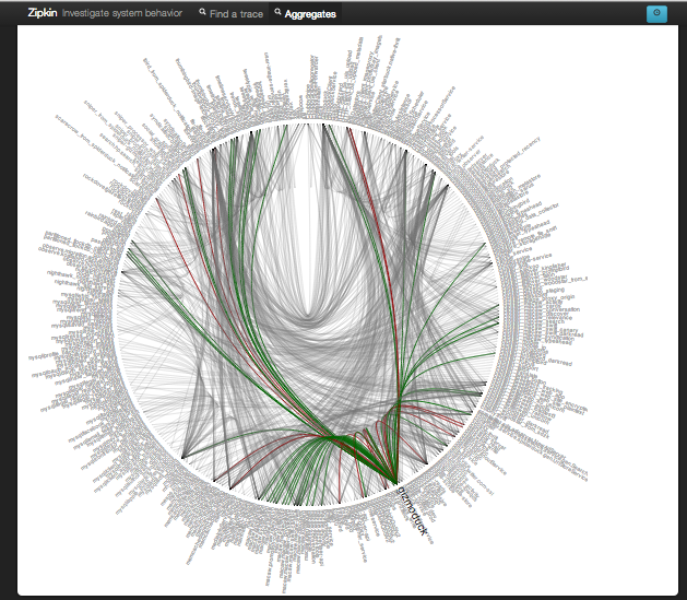
Twitter 분산 시스템 (출처: Observability at Twitter)
그러므로, Prometheus를 사용하는 것은 그냥 감시 도구로 사용하는 것도 전혀 문제가 없다. 다만, Prometheus를 사용해 가는데 꼭 기억해야 하는, Prometheus는 Observability를 실현하는 요소의 하나인 점이다. 다양한 컴포넌트를 1개씩 수동으로 등록해 가는 것이 아니라, Service Discovery를 사용해 간단하게 등록할 수 있다. 그렇게 함으로써, 사람이 지금까지 수동으로 하고 있던 것 같은 작업을 자동화하고, 어느 정도 시스템 측에 의지할 수 있기 되고, 클라우드 네이티브로 할 수 있게 될 것이라고 생각된다.
Observability와 Prometheus
계속해서 Observability와 Prometheus에 대해 이야기하려고 한다. Observability를 말하는데, 또 새로운 말이 나와서 미안하지만, 유의해야 할 용어가 있다. “Telemetry(텔레메트리)“라고 하는 용어가 있는데, Telemetry라고 것은 Observability를 실현하기 위한 툴에 요구되는 요소의 하나이다. Observability와 Telemetry는 같는 것이 아니다. 어디까지나 요소라고 것으로 해석된다.
그래서, Telemetry를 실현하는 툴을 도입하는 것 자체가 Observability의 실현이 아니다. 즉, Prometheus를 사용했기 때문에 Observability를 실현할 수 있었다는 것은 아니다. Prometheus는 어디까지나 그것을 실현하기 위한 툴로서, Prometheus를 사용하는 것 뿐만 아니라, 그것을 활용함으로써 어떻게 Observability를 실현해 나가는지, 횡단적으로 시스템의 상태를 보이도록 할까라고 하는 하지만, Observability를 만들어 가는데 있어서의 목적이라고 할 수 있다.
Telemetry를 말을 할 때 나오는 요소로는 Metrics, Logging, Tracing의 세 가지가 있다. Metrics는 아시는 사람도 있다고 생각되지만, 예를 들면 Zabbix등도 Metrics를 사용하고 있고, 세상의 감시 시스템의 대부분은 Metrics를 전제로 하고 있다. 다음 Logging인데, 이것도 당연히 사용하고 있다고 생각된다. 여기서 그다니 별로 보지 않는 용어는 Tracing이다. 분산 트레이싱도 꽤 오래전부터 있는 말이지만, 그다지 익숙하지 않을지도 모른다.
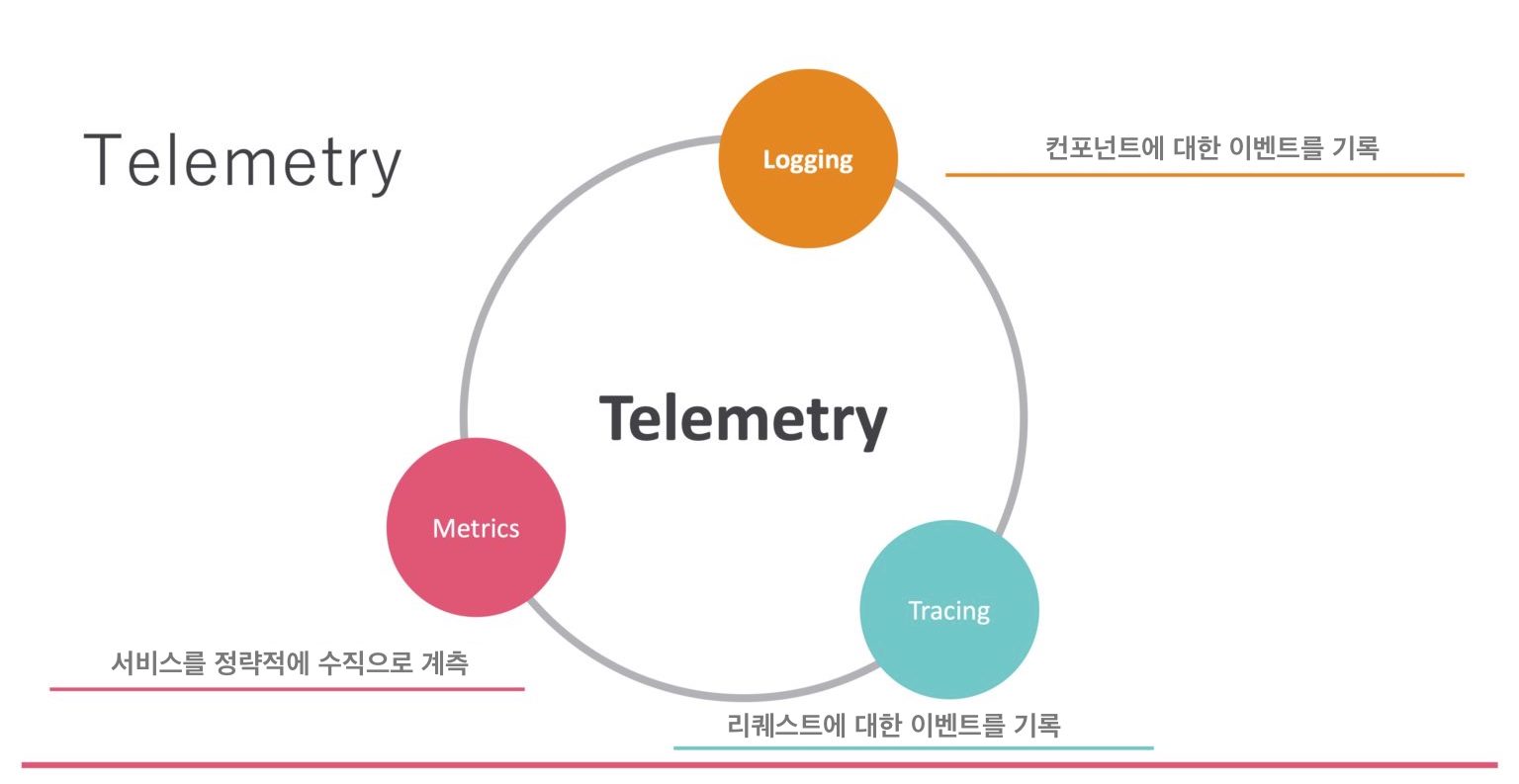
Observability를 실현하기 위해서는 이 3가지 요소를 적절히 다루어야 하는데, Prometheus가 이 모든 것을 실현할 수 있을까? 하면 그런 일이 없고, Prometheus는 이 안의 요소 중 하나, 구체적으로는 Metrics를 실현하기 위한 툴이다. 이 Metrics라는 것은 연속적인 수치 데이터이기도 한다. 예를 들면, 메모리의 사용량이 어느 타이밍에 1GB였고, 어느 타이밍에 2GB였다. 그것이 3GB가 되어, 또 2GB로 돌아오고 하는 계속적인 데이터이거나 라든지, 그리고는 그것이 시계열로 줄지어있는 것 같은 데이터이다.
이러한 데이터는 비교적 구조가 간단하기 때문에 통계적인 집계가 가능하다. 예를 들어, 어느 시간 전체를 보고, 실제로 어떤 변화가 있었는지, 혹은 시스템의 자원의 사용량은 어느 정도였는지, 그러한 집계를 할 수 있는 것이다. 또, 그 집계를 함으로 써, 예를 들어 매주 금요일은 Metrics가 대폭 상승하고 있으므로, 모두 업무가 끝난 후에 웹 사이트에 액세스을 한다는 것을 알 수 있고, 대책으로서 서비스를 스케일-업하거나, 대응되는 인스턴스를 추가하거나 하는 것을 할 수 있다. 즉, Prometheus를 활용하면 Metrics를 활용한 집계와 추세 예측을 할 수 있게 된다.
다음은
다음에는 Prometheus를 실제로 시작하려면 어떻게 해야 하는가에 대해서 알아보려고 한다.