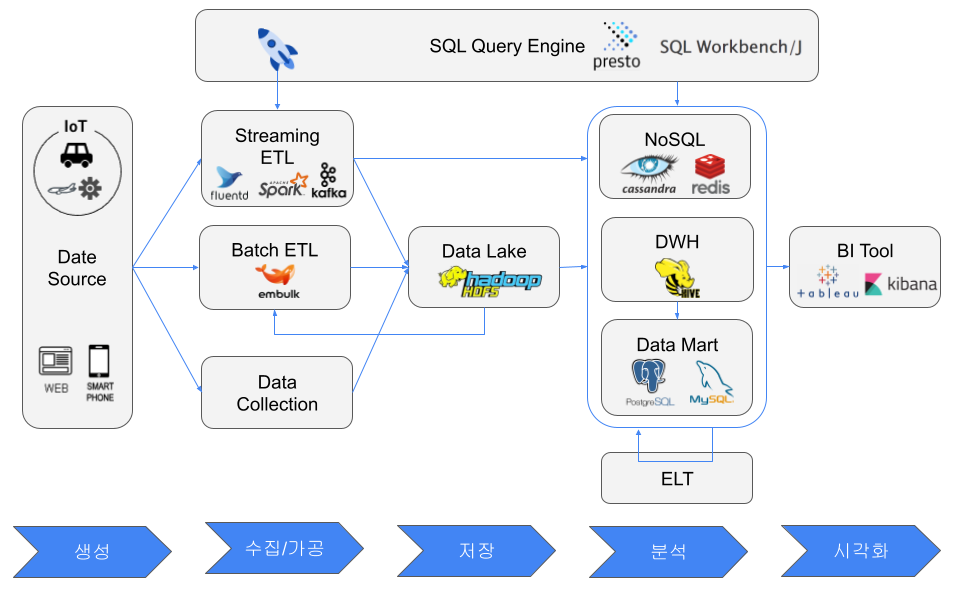
What is a Big Data Analytics Platform? Building a Data Pipeline
What is Big Data?
The goal here is to visualize and analyze big data.
Small-data software such as Excel or a traditional RDB cannot handle big data because of hardware resource limits: CPU time is insufficient, memory cannot hold the data, and storage may not be large enough. To process big data, use software that supports parallel processing and multiple computers.
Data Source
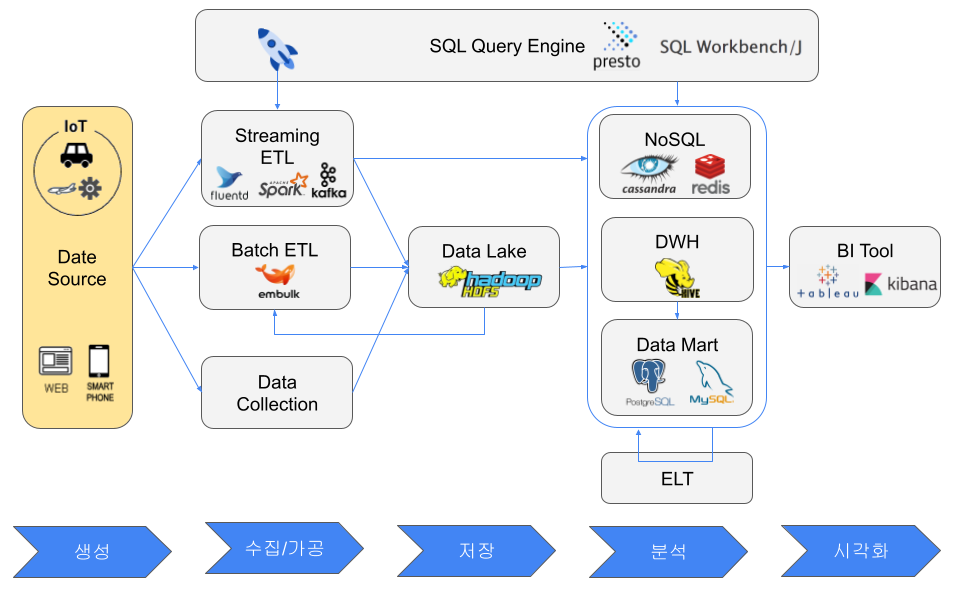
Examples include web servers, IoT devices such as factory or vehicle sensors, and mobile devices. The meaning of data source depends on the viewpoint. From a BI tool, for example, NoSQL, a DWH, or a data mart may be treated as a data source.
Data can be divided into structured, unstructured, and semi-structured data.
Structured Data
Structured data is easy for computers to handle through RDBs and SQL. However, rows and columns must be defined in advance, data must be converted into the fixed schema before storage, and nested data is usually handled through joins.
Unstructured Data
Examples include music, photos, and text logs.
<6>Feb 28 12:00:00 192.168.0.1 fluentd[11111]: [error] Syslog test
Unstructured data is easy to store as-is, but difficult to query with RDB and SQL because there is no schema.
Semi-structured Data
Examples include JSON, XML, AVRO, Parquet, and ORC. A log line can be converted into JSON by assigning names to each element.
{
"jsonPayload": {
"priority": "6",
"host": "192.168.0.1",
"ident": "fluentd",
"pid": "11111",
"message": "[error] Syslog test"
}
}
Semi-structured data has attributes, can be queried by compatible databases, and allows schema changes later. It can also contain nested related data.
ETL and ELT
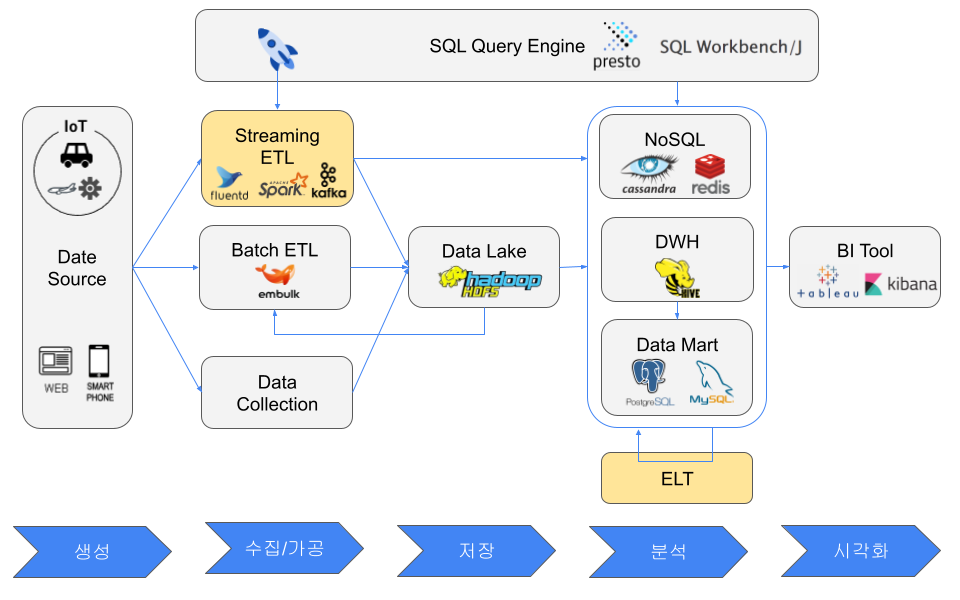
Data sources often do not perform transformation because production web servers should not be overloaded, IoT devices may not have enough resources, and mobile devices belong to customers.
ETL can be batch-oriented or streaming-oriented. Batch ETL focuses on throughput and runs at intervals such as hourly or nightly. Streaming ETL focuses on real time and runs when data is generated.
Extraction tools include Embulk for batch ETL and fluentd, beats, or Kafka Producer API for streaming ETL. A Pub/Sub messaging system can be placed between Extract and Transform to distribute processing and temporarily buffer bursts of data.
Transform processing can be done with SQL, pandas, fluentd, logstash, Kafka Streams, or Spark Streaming. The transformed data is then loaded into NoSQL, a data lake, a data warehouse, or a data mart.
Data Lake
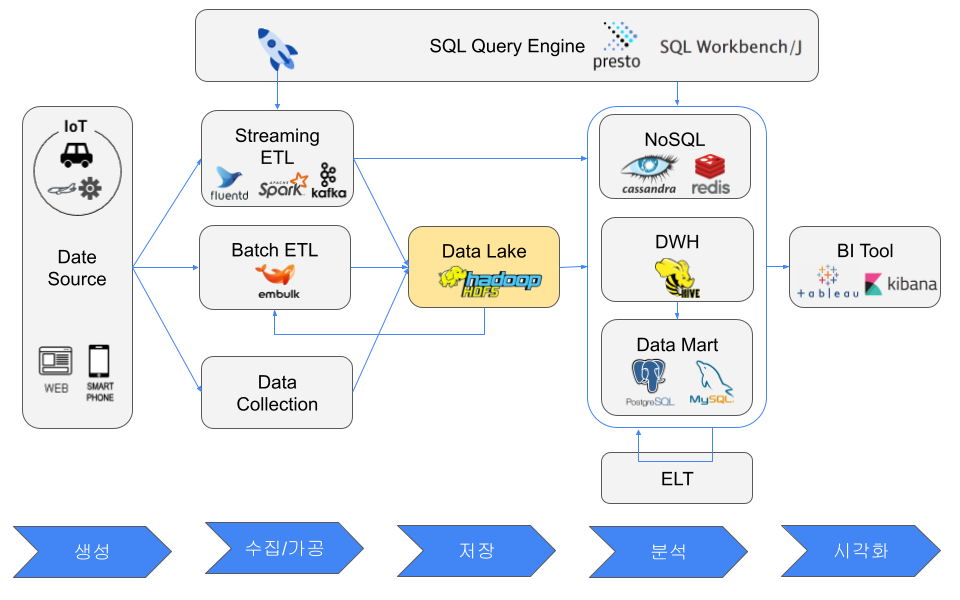
Examples include Hadoop HDFS and Amazon S3. Because a data lake keeps large amounts of data in various formats, scalable storage is usually selected.
NoSQL Database
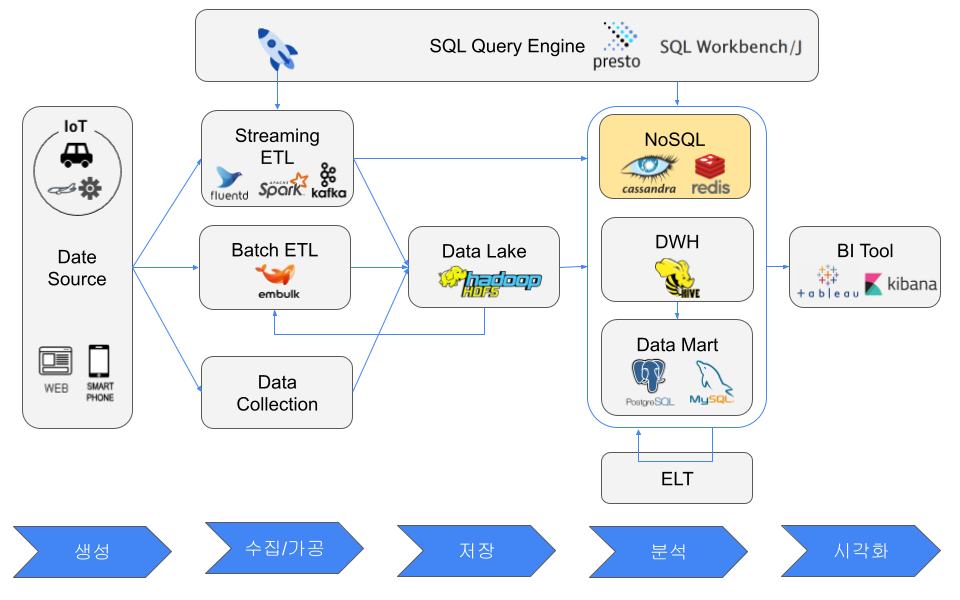
NoSQL databases generally relax some constraints of RDBs to pursue performance. Compared with RDBs, they often target low-latency processing, use flexible data models such as key-value, document, or graph, prefer client-side joins or nested data, and scale by adding nodes.
Common NoSQL models include in-memory key-value caches such as Memcached and Redis, key-value stores such as DynamoDB, wide-column stores such as Cassandra and HBase, graph databases such as Neo4j, and document stores such as Elasticsearch and MongoDB.
Data Warehouse
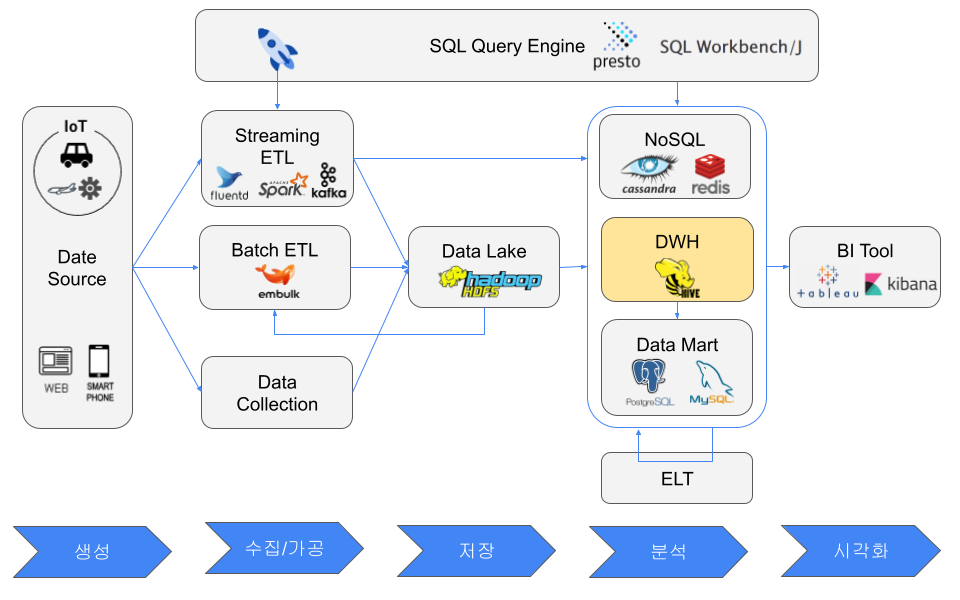
A DWH is used for analytics or OLAP, while an RDB is commonly used for transaction processing or OLTP. DWH systems generally use column-oriented storage and are suited to large-scale analysis.
Column-oriented storage formats include ORC and Parquet. Columnar databases read only necessary columns during analysis, making reads efficient. Writes are less efficient because values must be appended across column blocks, but compression is often very effective because values in the same column have similar types and patterns.
Examples include Snowflake, Amazon Redshift, and Hadoop with Hive or Presto using ORC or Parquet.
Compared with a data lake, a DWH is optimized for analyzing current structured data quickly, while a data lake stores all data for possible future use.
Data Mart
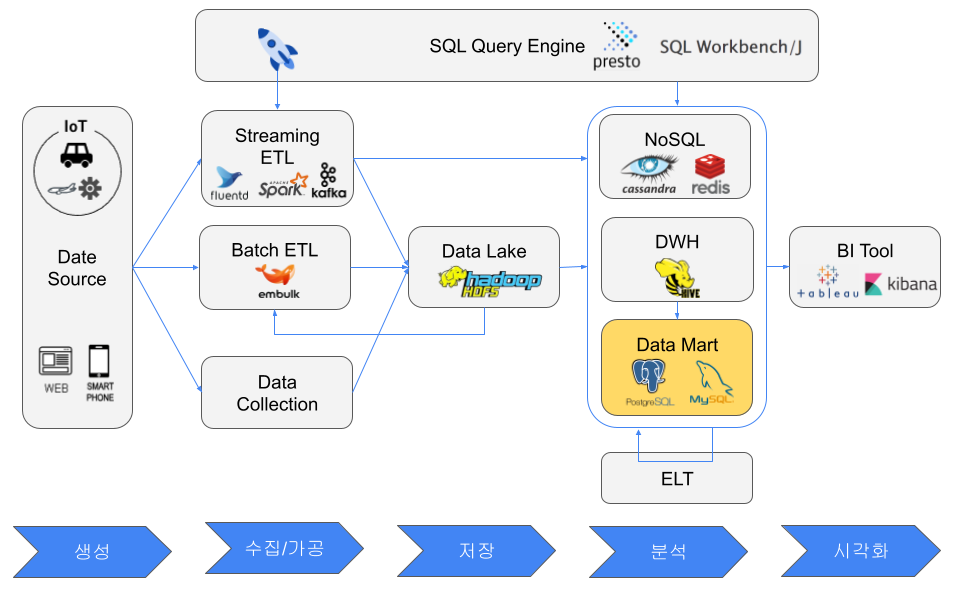
A data mart can be considered a smaller data warehouse. It usually serves a single department, contains only necessary data, and is fast for small analysis workloads. Examples include an RDB, a small DWH cluster, or CSV files.
SQL Query Engine
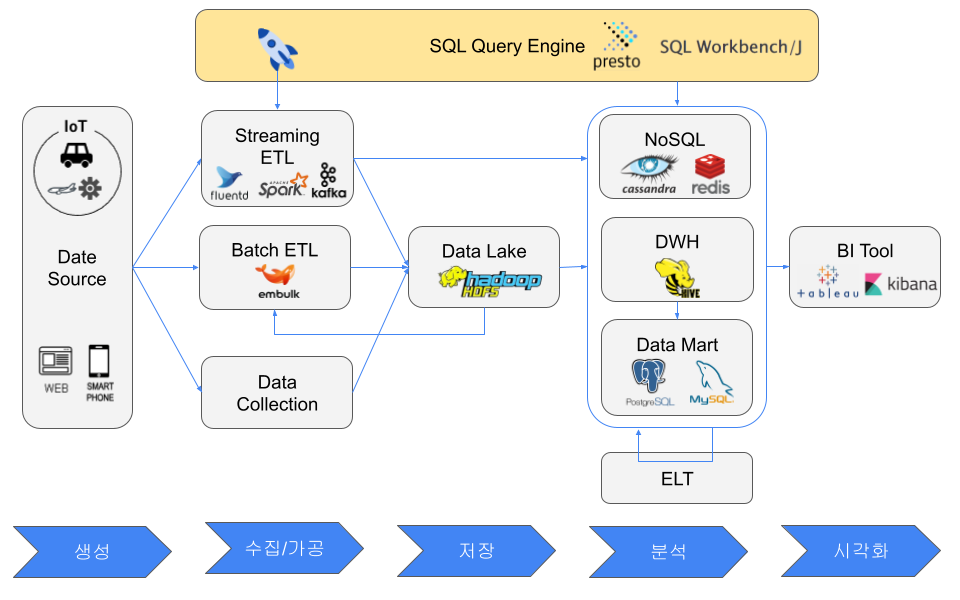
SQL query engines were created because users wanted to manipulate data more easily without writing programs. Examples include ksqlDB, Apache Flink SQL, Elasticsearch SQL, PartiQL, Presto, Apache Hive, SQL Workbench/J, and DBeaver.
BI Tool
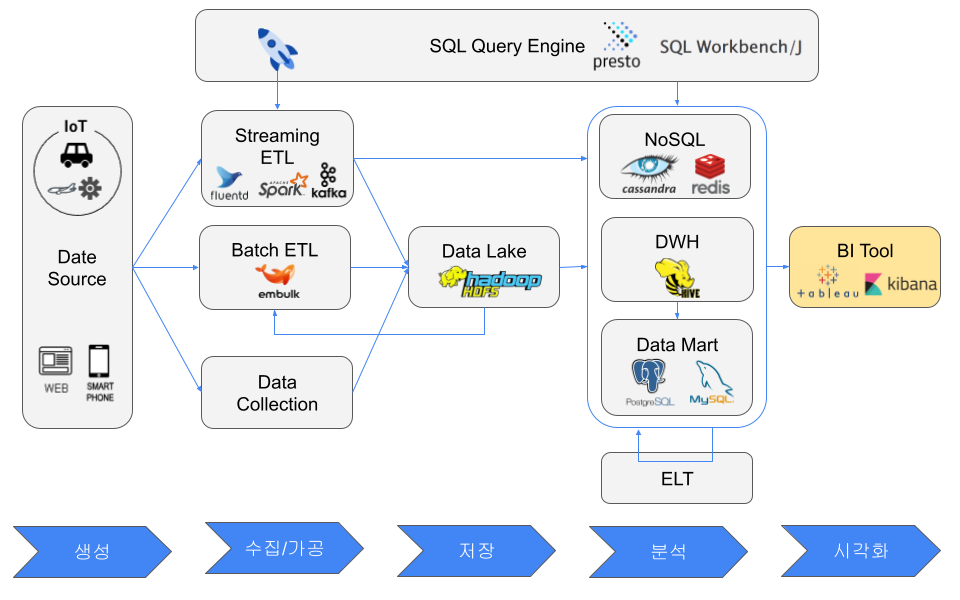
Representative BI tools include Tableau, Grafana, Kibana, and QuickSight.
Datastore Summary
RDBs are primarily used for transactions and fixed-schema structured data. NoSQL databases are often used for performance-focused workloads and flexible schemas. DWH systems are used for OLAP and structured or semi-structured analysis. Data lakes store structured, unstructured, and semi-structured data with a schemaless or catalog-based approach.