TiDB Storage
Basic Knowledge of Storage and Key-Value
Introduction
Databases, operating systems, and compilers are fundamental foundations for building computer software. Databases are close to the application layer and support business systems. They have continued to develop for decades and evolve every day.
Many people have used various kinds of databases, but very few have experience developing databases, especially distributed databases. Knowing database implementation not only improves skills but also helps build other systems and use databases more effectively.
The best way to deepen technical understanding is to immerse yourself in open source projects in that field. There are many excellent open source projects in the database field. Many people have probably looked at the source code of well-known projects such as MySQL and PostgreSQL. In the distributed database field, TiDB is also one of the few recognized projects, and like the products above, its source code can be read.
However, distributed databases are complex, so understanding the entire project is difficult for many engineers. For that reason, the author decided to organize articles that explain TiDB technology clearly. These articles introduce not only techniques that can be read from open source but also many implementation techniques hidden behind the SQL interface.
Data Storage
This section explains data storage, the most basic function of a database. There are many ways to store data. The simplest way is to build a data structure in memory and store data sent by users. For example, you can use an array to store data and add a new item to the array when data is received. This solution is simple, satisfies basic requirements, and has excellent performance. However, it has disadvantages that outweigh these strengths. The biggest problem is that all data is stored in memory, so data is lost when the server stops or restarts.
To achieve data persistence, data must be stored in non-volatile storage such as a disk. You can create a file on disk and append new data to the file when data is received. This is a persistent storage solution, but it is not enough by itself. If the disk that stores the data is damaged, the data is lost. Therefore, assuming disk damage, RAID (Redundant Array of Independent Disks) is used for redundancy. But what happens if the machine goes down? The data can no longer be accessed.
RAID is not a safe storage location. There are also methods such as storing data over the network and replicating at the hardware level with redundant software. The problem with these methods is maintaining consistency during replication. Protecting data integrity and correctness is a basic requirement, and achieving it involves difficult problems like the following.
- Fast write speed is required.
- Data must be read consistently when stored.
- Concurrent modifications must be handled.
- Multiple records must be modified atomically.
All of these problems are difficult to solve, but a database storage system must solve all of them to be considered excellent.
Against this background, we developed TiKV, the data store part of TiDB. First, forget the concept of SQL and look at how TiKV, a high-performance and highly reliable distributed key-value store, is implemented.
※ TiKV can be used as a KVS.
Key-Value
The first and most important step for a data storage system is deciding the data storage model, meaning the format in which data should be stored. TiKV can be thought of as a huge map where both keys and values are byte arrays. In this map, keys are placed in comparison order according to the raw binary bits of the byte array. Note the following.
- It is a huge map made up of key-value pairs.
- In this map, key-value pairs are ordered according to the binary sequence of the key. Users can navigate to the position of a key and use methods for the following key-value pairs. All those key-value pairs are greater than it.
Some readers may wonder what relationship this storage model has with SQL tables. To be clear: none.
Concepts of RocksDB, Raft, and Region
The previous section described data storage and key-value. This section introduces RocksDB, Raft, and Region.
RocksDB
A persistent storage engine stores data on disk. TiKV is no exception. However, TiKV does not write data directly to disk. First, TiKV stores data in RocksDB, and RocksDB performs the actual data storage. Developing a standalone storage engine, especially a high-performance standalone engine, is costly because it requires many optimizations.
PingCAP found that RocksDB is an excellent open source standalone storage engine that satisfies all requirements. While the Facebook team focuses on optimizing this engine, PingCAP can benefit from a powerful standalone engine that continues to improve without excessive difficulty. Of course, PingCAP also contributes some code to RocksDB, but it is hard to expect dramatic additional improvements from this project. In short, RocksDB can be viewed as a standalone key-value map.
Raft
The first important step in this complex project was to find a stable and effective local storage solution. The next relatively difficult task is how to protect data integrity and correctness when one computer stops. An effective approach is replicating data to multiple computers.
Then, if one computer crashes, a replica on another computer can be used. However, a replication solution must be reliable and effective enough to handle invalid replicas. It sounds difficult, but it can be achieved with Raft. Raft is a consensus algorithm equivalent to Paxos but easier to understand. If you are interested in Raft, read the Raft paper for details. This external Raft report presents only the basic solution, and strictly following it results in low performance. PingCAP has made various optimizations to implement Raft.
Raft is a consensus algorithm and has the following three important functions.
- Leader election
- Membership changes
- Log replication
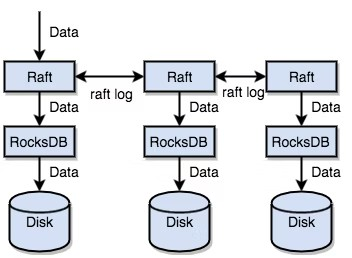
TiKV uses Raft to replicate data. Every data change is recorded as a Raft log. Through Raft’s log replication function, data is synchronized safely and reliably across multiple nodes in a Raft group.
In summary, standalone RocksDB lets data be stored quickly on disk. Raft lets data be replicated to multiple machines in preparation for system failure. Data is written through the Raft interface, not directly to RocksDB. Thanks to the Raft implementation, a distributed key-value system can be used, and there is no longer a need to worry about machine failure.
Region
This section introduces the very important concept of a “Region.” Region is the foundation for understanding a series of mechanisms. Before considering this concept, forget Raft and imagine a situation where all data has only one replica.
As mentioned earlier, TiKV can be viewed as a huge ordered key-value map. To obtain horizontal scalability for storage, data must be distributed across multiple machines.
In key-value systems, there are two common solutions for distributing data across multiple computers. One solution is to create a hash and choose the storage node based on the hash value. The other is to use ranges and store serial key segments on storage nodes. TiKV chooses the second solution and divides the entire key-value space into multiple segments. Each segment consists of adjacent keys. We call these segments “Regions.” There is an upper limit to the amount of data each Region can store, 64 MB by default, and this size is configurable. Each Region can be represented by an interval from StartKey to EndKey, open on the left and closed on the right.
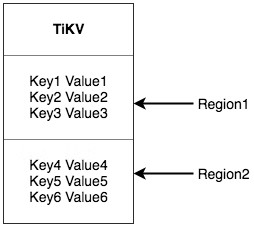
The Region discussed here has nothing to do with SQL tables. For now, forget SQL and focus on key-value.
After data is divided into Regions, two important tasks are performed.
- Distribute data across all nodes in the cluster and use Regions as the basic unit of data movement. Ensure that the number of Regions on each node is roughly the same.
- Replication and membership management through Raft at the Region level.
These two tasks are very important, so they are explained one by one.
For the first task, data is divided into several Regions based on keys, and all data in each Region is stored on one node. One component in the system is responsible for evenly distributing Regions across all cluster nodes. As a result, horizontal scalability of storage capacity is provided. When a new node is added, the system automatically schedules Regions from other nodes. Load balancing is also achieved, so a situation where one node has a large amount of data and another has very little does not occur. At the same time, so that upper-layer clients can access the data they need, another component records the distribution of Regions across nodes. In other words, users can look up the exact Region for a key and the node where that Region is placed. These two components are explained in more detail later.
Now move to the second task. TiKV replicates data in Regions. In other words, data in one Region has several replicas called “Replica.” Raft is used to achieve data consistency between replicas. Multiple replicas of one Region are stored on several different nodes and form a Raft group. One replica acts as the leader of the group, and the others act as followers. Reads and writes both go through the leader, and the leader replicates to followers.
The following diagram shows the overall image of Regions and Raft groups.
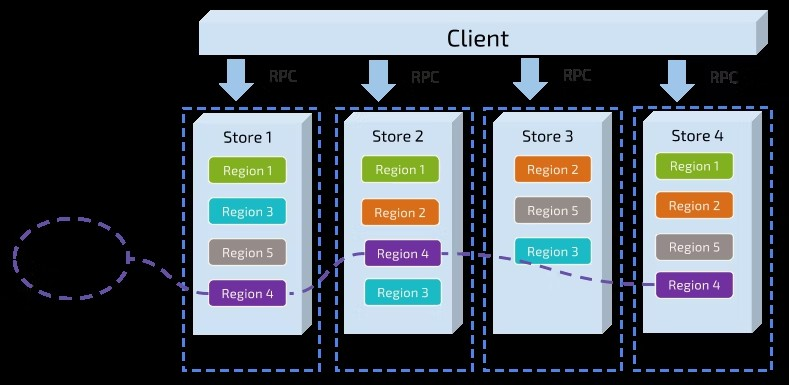
By distributing and replicating data by Region, you can use a distributed key-value system with a certain level of disaster recovery ability. Users no longer need to worry about capacity or data loss due to disk failure. This is excellent, but not perfect. More functionality is needed.
MVCC and Transactions
The previous sections introduced concepts such as data storage, key-value, RocksDB, Raft, and Region. This section introduces MVCC and transactions.
MVCC
Many databases perform multi-version concurrency control, or MVCC. TiKV is no exception. Without MVCC, if two clients update a key value at the same time, the data is locked. In a distributed scenario, this kind of processing leads to performance problems or deadlocks.
TiKV implements MVCC by adding versions to keys. Without MVCC, TiKV’s data layout is as follows.
Key1 -> Value
Key2 -> Value
...
KeyN -> Value
With MVCC, TiKV’s key arrangement is as follows.
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
...
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
...
KeyN-Version2 -> Value
KeyN-Version1 -> Value
...
If a key has multiple versions, the largest number is placed first. If needed, review the key-value section that described keys and sorted arrays. In this way, when a key has a version and a value is fetched, an MVCC key, Key-Version, can be built using the key and version. Then Seek(Key-Version) can be executed directly to find the first position after this Key-Version.
Transactions
TiKV transactions adopt the Percolator model and include many optimizations. What is worth mentioning here is that TiKV transactions use optimistic locking. TiKV transactions do not detect write conflicts during execution. Conflicts are detected only during the commit phase. The transaction that finishes commit first is written successfully, while the other transaction retries. If write contention is not severe, this model performs very well. For example, it can handle random updates to many rows in a large table without difficulty. However, performance drops if write conflicts are severe. Consider a counter as an extreme example. A situation where many clients simultaneously update a few rows leads to serious conflicts and many failed retries.
Conclusion
This storage article introduced the basic concepts and some details of TiKV, the layered structure of this distributed transactional key-value engine, and how multi-data-center disaster recovery is achieved. The next article introduces the computing part of the distributed database TiDB.