Designing Data-Intensive Applications | Chapter 07. Transactions
Presenters: Hyundo Park, Seungik Lee
The Ambiguous Concept of Transactions
ACID
ACID is an acronym for the properties that guarantee database transactions are performed safely.
Atomicity
Atomicity guarantees that either everything is reflected in the database or nothing is reflected. It prevents partial updates from causing larger problems.
Example: airline tickets
Payment and reservation for a ticket must either both happen or both not happen. A successful payment without a seat reservation is not acceptable.
A single transaction can apply not only to airline ticket reservations, but also to hotels, transportation, and exact currency exchange at the current exchange rate.
Source: wikipedia
Consistency
Consistency means that when a transaction completes successfully, the database always remains in a consistent state.
Source: wikipedia
Example: in an accounting system, debits and credits across all accounts must always balance.
Consistency, the C in ACID, is not actually considered a database property but an application property.
This is because the database alone cannot prevent incorrect data that violates invariants from being written.
This is viewed as the application’s responsibility, and the application can rely on the database’s atomicity and isolation properties to achieve consistency.
Isolation
Transactions running concurrently are isolated from each other and cannot interfere.
If one transaction writes several values, another transaction must see either all of them or none of them. It must not see only part of the changes.
Durability
The purpose of a database system is to provide safe storage where data is not lost.
Durability guarantees that if a transaction has committed successfully, all data written by that transaction is not lost even if hardware fails or the database crashes.
Single-Object and Multi-Object Operations
Single-object writes
Atomicity and isolation also apply when changing a single object.
Therefore, storage engines almost universally aim to provide atomicity and isolation at the level of a single object on one node.
Example: writing a 20KB JSON document to a database.
What happens if the network connection is lost after sending the first 10KB, if power fails while the database is overwriting the existing value on disk, or if another client reads the document while it is being written and sees a partially updated value?
The need for multi-object transactions
Multi-object transactions are needed when several pieces of data must stay synchronized.
Even without transactions, applications that perform complex reads and writes can be implemented.
However, without atomicity, error handling becomes much more complicated, and without isolation, concurrency problems can occur.
- Multi-object transactions guarantee that references remain valid, such as foreign keys.
- They prevent denormalized data from becoming unsynchronized when several documents are updated at once.
- Without transaction isolation, a record may appear in one index but not another because the other index has not yet been updated.
Weak Isolation Levels
Read Committed
At the most basic level of transaction isolation, this level provides two guarantees:
- When reading from the database, you see only committed data. There are no dirty reads.
- When writing to the database, you overwrite only committed data. There are no dirty writes.
Preventing dirty reads
A dirty read is a phenomenon where work processed by one transaction is visible to another transaction even though it has not completed.
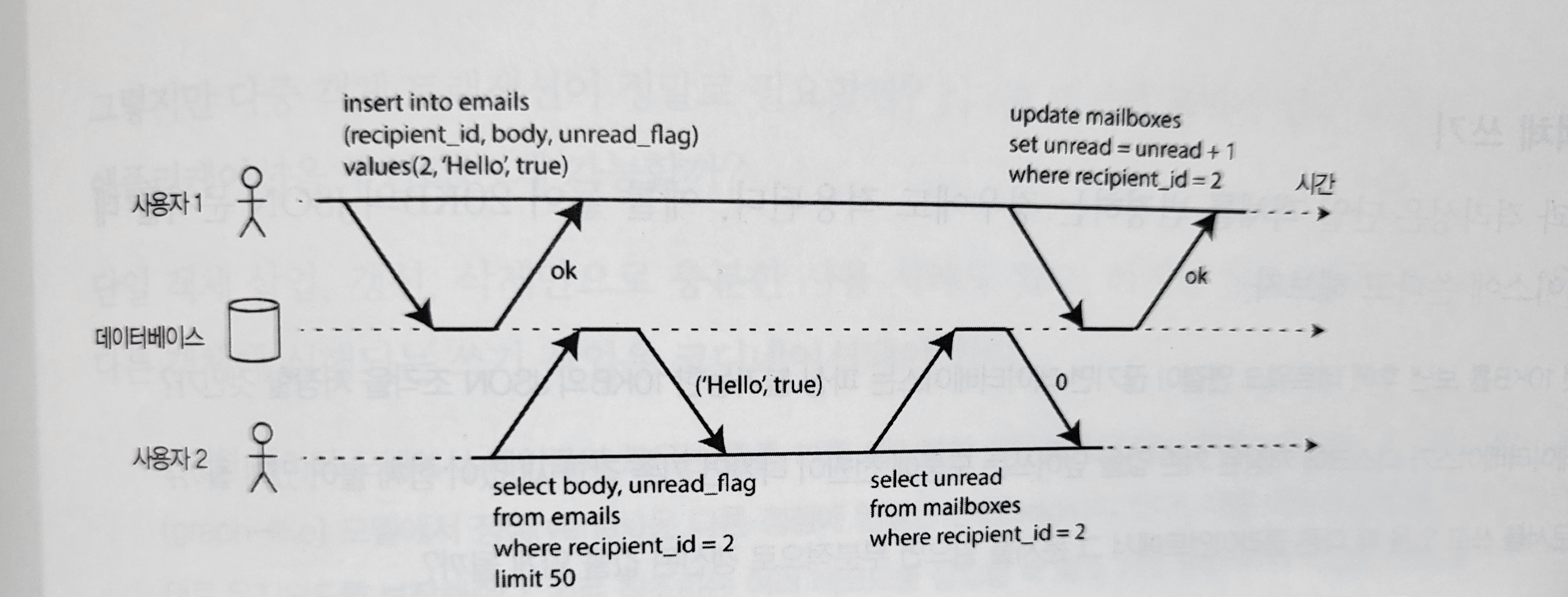
Figure 7-2. Isolation violation: a transaction reads data written by another transaction but not yet committed, a dirty read.
Why preventing dirty reads is useful:
- If dirty reads occur, another transaction may see some updated values and some values that have not been updated.
- If a transaction aborts, everything must be rolled back. If dirty reads are allowed, another transaction may see data that will later be rolled back.
Preventing dirty writes
A dirty write occurs when two transactions try to update the same object at the same time, and the later write overwrites a value written by a transaction that has not yet committed.
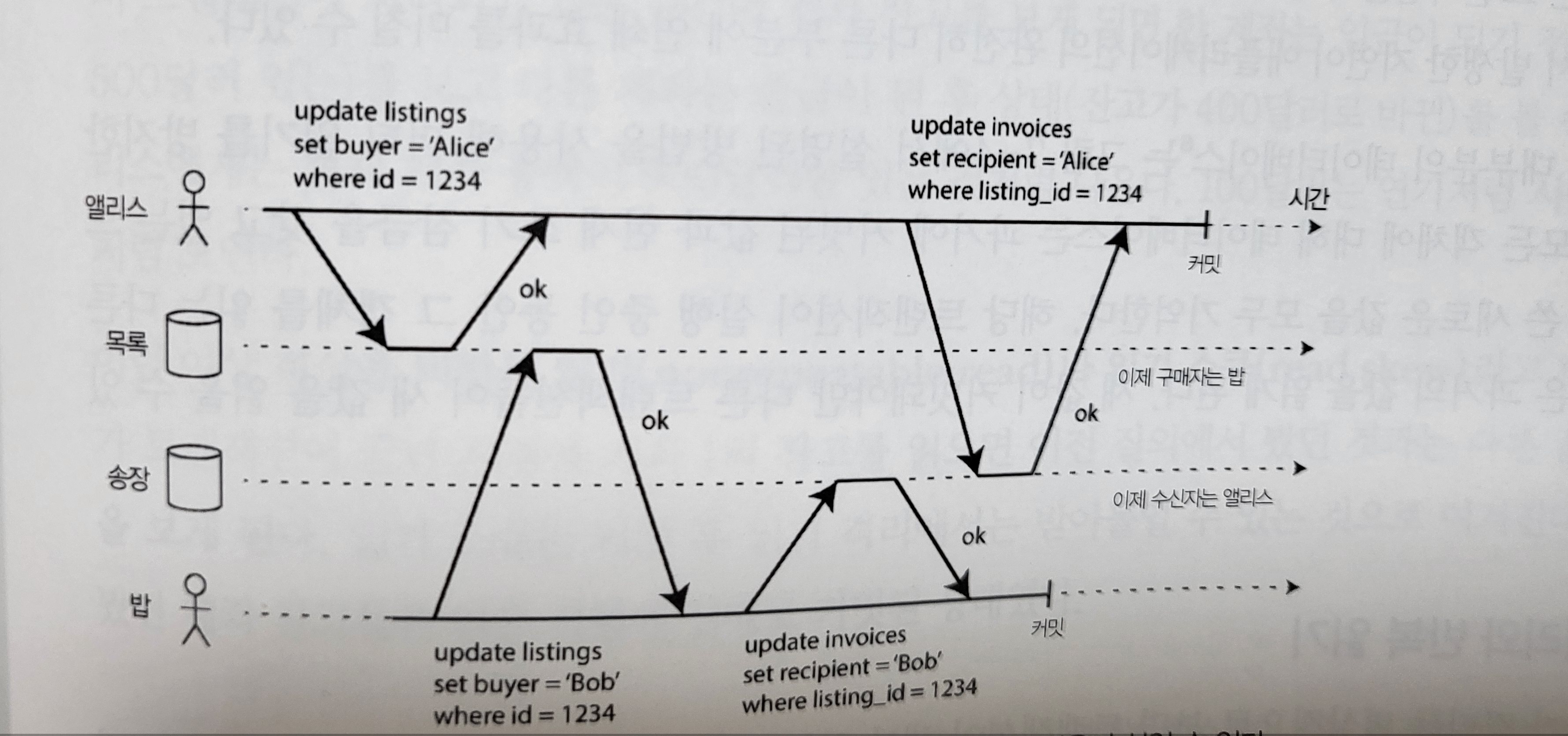
Figure 7-5. Dirty writes can mix contents when conflicting writes are executed by different transactions.
When conflicting writes are executed by different transactions, dirty writes can mix contents. Preventing dirty writes helps avoid several concurrency problems.
Implementing read committed
Read committed is the default isolation level in Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL, and others.
- Preventing dirty writes: a lock is held until the transaction commits or aborts. This lock is automatically used by the database in read committed mode.
- Preventing dirty reads: the database remembers both the old committed value and the new value currently being written, and reads the old value while the transaction is running.
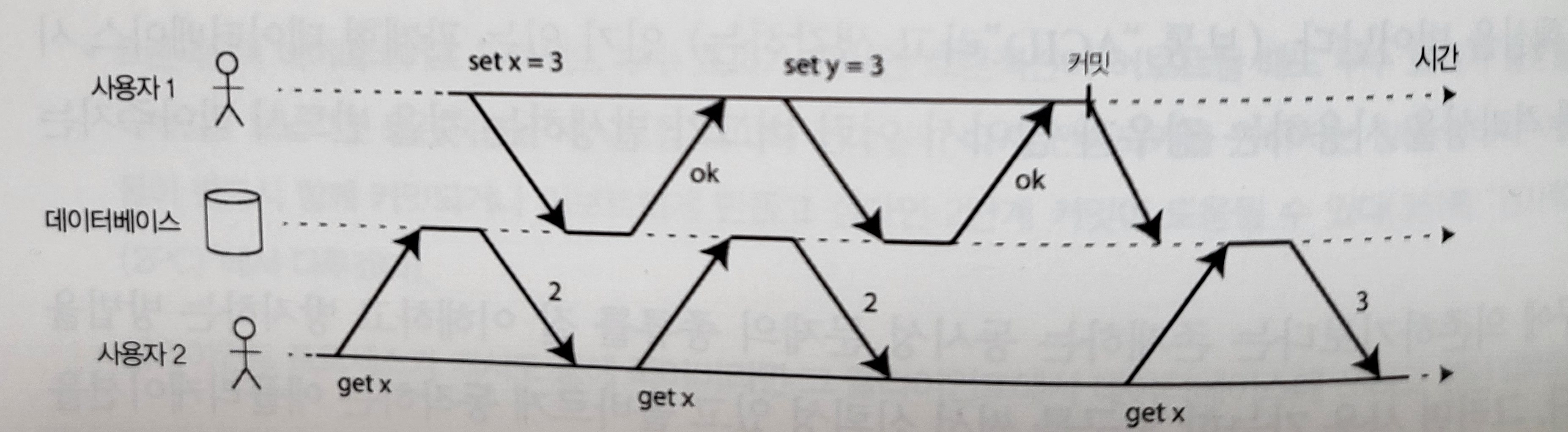
Figure 7-4. Preventing dirty reads: user 2 sees the new value of x only after user 1’s transaction commits.
Preventing dirty reads: user 2 sees the new value of x only after user 1’s transaction commits.
Snapshot Isolation and Repeatable Read
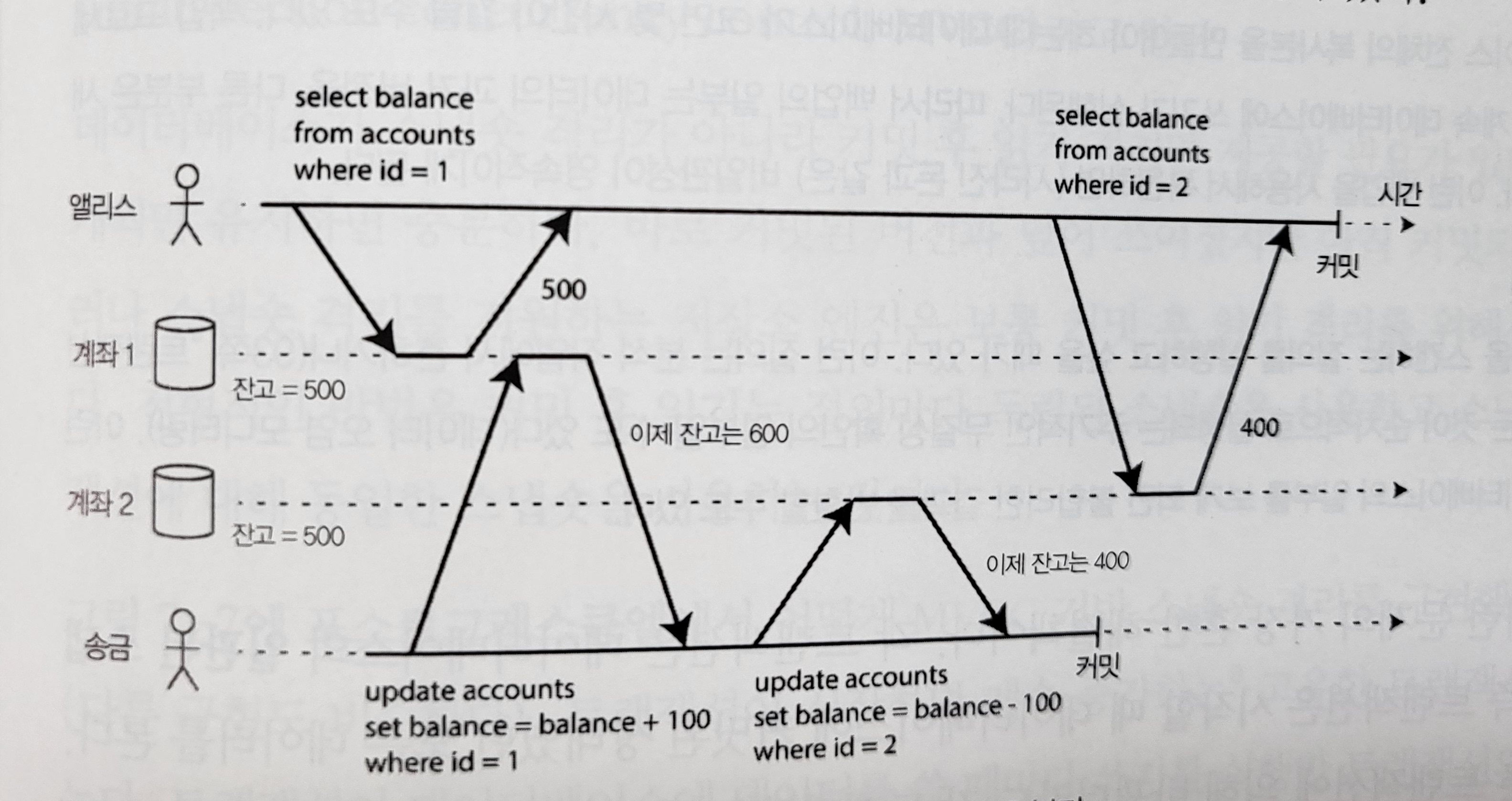
Figure 7-6. Read skew: Alice sees the database in an inconsistent state.
Concurrency bugs can still occur at the read committed isolation level. This phenomenon is called nonrepeatable read or read skew.
In the case above, if the page is refreshed a few seconds later, the account may look consistent again, but some situations cannot tolerate this inconsistency.
Examples: backups, where the original and copy differ; analytical queries and integrity checks, where a query scanning a large part of the database sees different parts at different points in time and returns incorrect results.
Snapshot isolation is an implementation where each transaction reads from a consistent snapshot of the database.
In other words, a transaction sees all data that was committed in the database when the transaction began. Even if data is later changed by another transaction, each transaction sees only past data from a specific point in time.
Implementing snapshot isolation
Multi-version concurrency control, or MVCC, is a technique where the database maintains several versions of an object together.
Q. Read committed also uses versions to prevent dirty reads, so what is the difference?
A. Read committed uses an independent snapshot for each query, while snapshot isolation uses the same snapshot for the entire transaction. The difference is how far back through the backed-up record versions the database must look.
Visibility rules for seeing a consistent snapshot
When a transaction reads an object from the database, it uses transaction IDs to determine what can and cannot be seen.
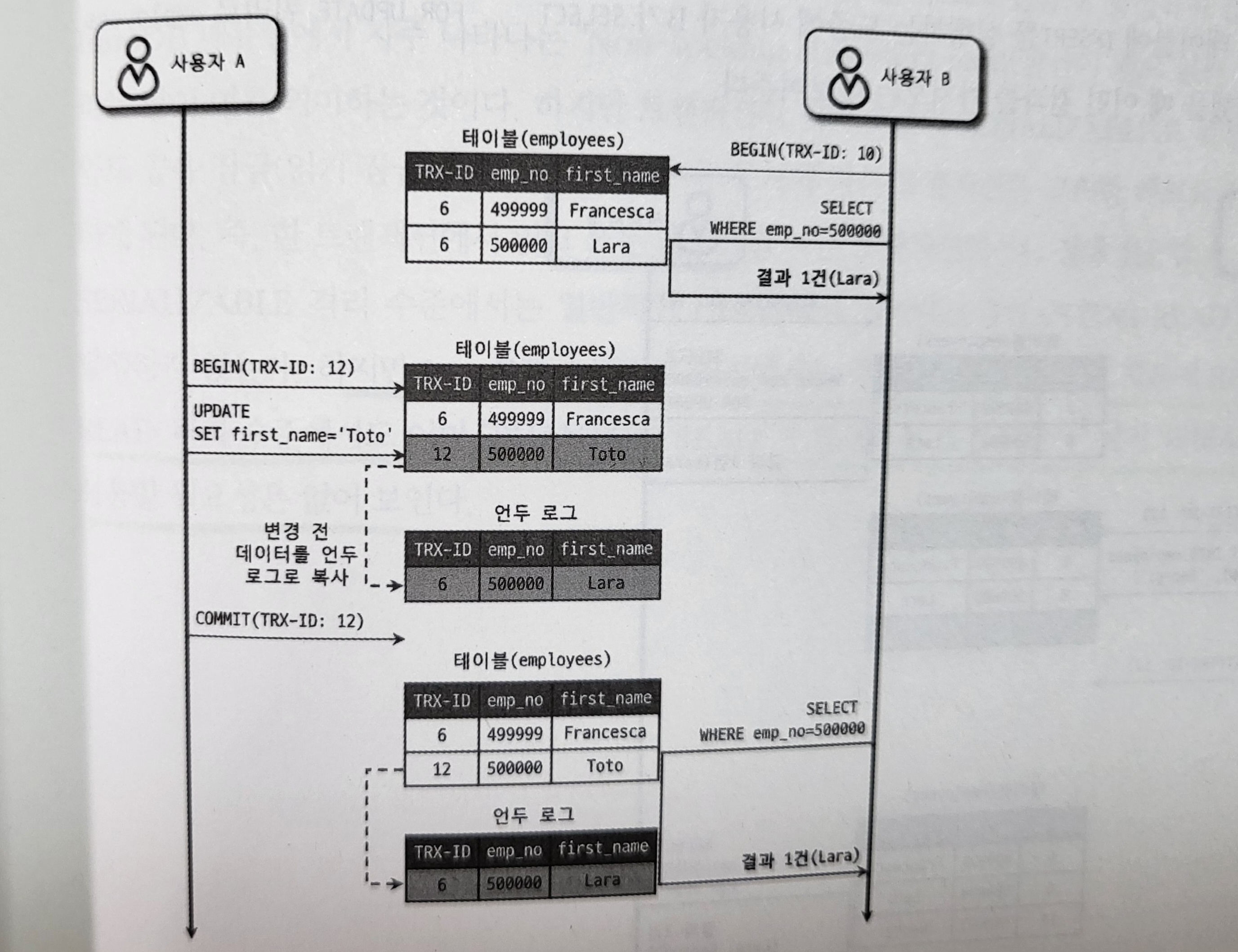
Source: Real MySQL 8.0
Behavior:
- Data written by transactions with larger transaction IDs, meaning transactions that started after the current transaction started, is ignored regardless of whether those transactions committed.
Indexes and snapshot isolation
How indexes work in multi-version databases:
One option is for the index to point to all versions of an object, for index queries to filter out versions not visible to the current transaction, and for garbage collection to delete corresponding index entries when it removes old object versions that are no longer visible to any transaction.
PostgreSQL:
- Performs an optimization that avoids index updates if different versions of the same object can be stored on the same page.
CouchDB, Datomic, LMDB:
- Use an append-only/copy-on-write variant.
When a tree page is updated, a new copy of each changed page is created instead of overwriting it. Parent pages up to the tree root are copied and updated to point to the new versions of their child pages. Pages unaffected by the write do not need to be copied and remain unchanged. - Use an append-only B-tree.
Every transaction that performs a write creates a new B-tree root, and a particular root becomes the consistent snapshot of the database at the time it was created. Later writes can only create new tree roots and cannot change existing B-trees, so there is no need to filter objects by transaction ID.
However, this method also needs background processes for compaction and garbage collection.
Repeatable read and confusing names
Snapshot isolation is useful for read-only transactions. Because the SQL standard does not include the concept of snapshot isolation, different databases use different names.
- Oracle: Serializable
- PostgreSQL, MySQL: Repeatable Read
Preventing Lost Updates
If two transactions work at the same time, the second write may not include the first change, and one of the changes can be lost.
Solutions:
- Atomic write operations
- Explicit locking
- Automatic lost update detection
- Compare-and-set
- Conflict resolution and replication
Atomic write operations
- Achieve concurrency safety by giving write operations the property of atomicity.
- Implemented by acquiring an exclusive lock, so other transactions cannot read the object until the update is applied.
- Another method is to force all atomic operations to execute on a single thread.
Explicit locking
- The application explicitly locks the object it is going to update.
- If another transaction tries to read the same object at the same time, it is forced to wait until the first read-modify-write cycle completes.
Listing development team > 07. Transactions > Screenshot 2022-04-01 1.30.42 PM.png
Example 7-1. Preventing lost updates by explicitly locking a row
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE; (1)
-- After checking that the move is valid,
-- update the position returned by the previous SELECT.
UPDATE figures SET position = '4' WHERE id = 1234;
COMMIT;
Automatic lost update detection
- Allow parallel execution of multiple transactions. If the transaction manager detects a lost update, it aborts the transaction and forces a retry.
Compare-and-set
- Avoid lost updates by allowing an update only if the value has not changed since it was last read.
-- Depending on the database implementation, this may or may not be safe.
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';
Conflict resolution and replication
- Locks and compare-and-set operations assume there is only one latest copy of the data.
- Databases that use multi-leader or leaderless replication generally allow multiple writes to run concurrently and replicate asynchronously.
- Therefore, they cannot guarantee that there is only one latest copy of the data.
- A common approach in replicated databases is to allow multiple conflicting versions of a value to be created when writes happen concurrently, and later resolve the conflict and merge those versions.
Write Skew and Phantoms
- Assume two transactions start almost at the same time.
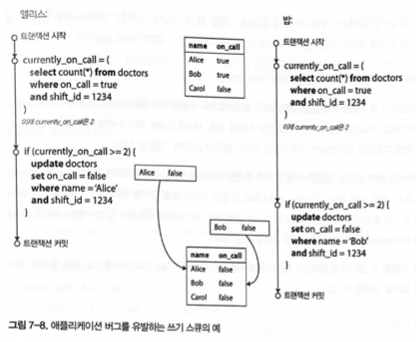
Figure 7-8. Example of write skew that causes an application bug
- Because the database uses snapshot isolation, both return 2 and both transactions proceed to the next step.
- This violates the requirement that at least one doctor must be on call.
- This phenomenon is called write skew.
Characterizing write skew
- Write skew can appear when two transactions read the same objects and then update some of them.
Phantoms that cause write skew
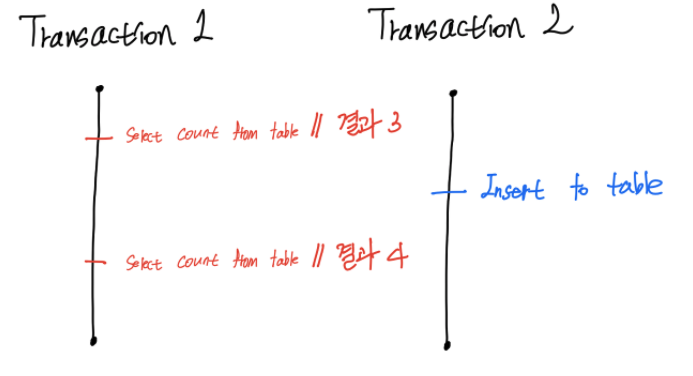
- A phantom is a phenomenon where a write executed by one transaction changes the result of a search query in another transaction.
Materializing conflicts
- Why materialize conflicts? Because there was no object to lock during the initial select, so an artificial lock object is added to the database.
- Create the target row in advance and lock it. Rows are created in advance for all combinations of the specific range targeted by transactions, such as the next six months for meeting room reservations.
- A reservation transaction can lock the desired target row in the table because it was created in advance.
- The created rows are only a collection of locks to prevent concurrent changes. They are not actual application data.
- Disadvantage: it is not pleasant for a concurrency control mechanism to leak into the application data model. It should be considered a last resort when no other alternative is possible.
Serializability
Problems with the way databases manage concurrency:
- Isolation levels are hard to understand, and their implementations are inconsistent across databases.
- It is hard to know from application code whether it is safe to run that code at a particular isolation level, especially in a large application where not everything happening concurrently is known.
- Concurrency problems are usually nondeterministic and intermittent, so they are difficult to test. They occur only when timing is unlucky.
- The alternative is to use serializable isolation.
- Serializable isolation is generally considered the strongest isolation level.
- Even if multiple transactions run in parallel, the final result is guaranteed to be the same as if they had run serially, one at a time, without concurrency.
Three techniques that provide serializability
- Literally execute transactions sequentially.
- Two-phase locking.
- Optimistic concurrency control techniques such as serializable snapshot isolation.
Actual serial execution
- The simplest way to avoid concurrency problems is to remove concurrency completely.
- Run only one transaction at a time, serially, on a single thread.
- Disadvantage: performance.
Encapsulating transactions in stored procedures
- In the early days of databases, the intention was that a transaction could include the entire flow of a user’s activity.
- For example, selecting a route, fares, available seats, and itinerary for an airline ticket reservation could be represented as one transaction and committed atomically.
- If database transactions had to wait for user input to implement this method, they would be very slow.
- Instead, the entire transaction code is submitted to the database in advance as a stored procedure.
- It is assumed that all data needed by the transaction is in memory and that the stored procedure runs very quickly without network or disk I/O.
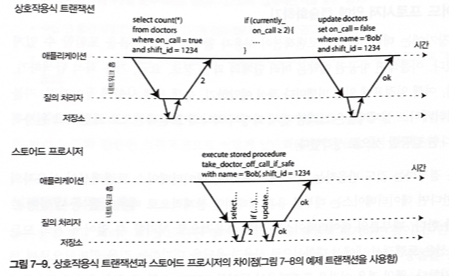
Figure 7-9. Difference between interactive transactions and stored procedures, using the example transaction from Figure 7-8
Partitioning
If each transaction can be partitioned so that it reads and writes data only within a single partition, each partition can have its own transaction-processing thread that runs independently from other partitions.
In this case, by assigning each partition to its own CPU core, transaction throughput can scale linearly with the number of CPU cores.
However, transactions that need to access multiple partitions are much slower than single-partition transactions because of coordination overhead.
Summary of serial execution
Serial execution of transactions has become a practical way to obtain serializable isolation under several constraints.
- All transactions must be small and fast because one slow transaction can delay all processing.
- It is limited to cases where the active dataset can fit in memory. If a single-threaded transaction must access disk, the system becomes very slow.
- Write throughput must be low enough to be handled by a single CPU core.
- Transactions across multiple partitions can be used, but there are strict limits on how much they can be used.
Two-Phase Locking (2PL)
-
If transaction A reads an object and transaction B wants to write that object, B must wait until A commits or aborts before proceeding. This guarantees that B cannot secretly change the object behind A’s back.
-
If transaction A wrote an object and transaction B wants to read that object, B must wait until A commits or aborts before proceeding. As shown in Figure 7-4, when 2PL is used, reading an old version of the object is not allowed.
-
Compared with snapshot isolation, readers never block writers and writers never block readers under snapshot isolation.
Implementing two-phase locking
- Used to implement the serializable isolation level in MySQL and SQL Server.
- Locks can be used in shared mode or exclusive mode.
- Because locks are used very heavily, deadlocks, where two transactions wait for each other, can occur very easily.
Performance of two-phase locking
- Its biggest weakness is performance.
- It is slow because of the overhead of acquiring and releasing locks.
- The more important reason is reduced concurrency. Concurrency and performance are inversely related.
Predicate Locks
Predicate locking acquires locks on all objects that match a condition.
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00'
- Predicate locks are slow because it takes time to check locks that match the condition.
- For this reason, most databases that support 2PL actually implement index-range locks or next-key locks.
Index-range locks
- For example, a predicate lock on reserving room 123 between noon and 1 p.m. can be approximated by locking reservations for room 123 across all time ranges.
- In the example above, there will likely be an index on
room_idor time values, so the lock is placed on that index range. - Index-range locks are less precise than predicate locks and may lock a larger range than strictly necessary for serializability, but they are a good compromise because their overhead is lower.
- If there is no suitable index for taking a range lock, the database may fall back to taking a shared lock on the entire table.
Serializable Snapshot Isolation (SSI)
- Can serializable isolation and good performance coexist?
- The most promising current approach is serializable snapshot isolation.
- It has only a small performance penalty compared with snapshot isolation.
Pessimistic concurrency control vs optimistic concurrency control
- Two-phase locking is a pessimistic concurrency control mechanism.
- The principle is that if something might go wrong, it is better to wait until the situation becomes safe before doing anything.
- Serializable snapshot isolation is an optimistic concurrency control mechanism.
- When a risky situation may occur, it proceeds with the hope that everything will be fine instead of blocking the transaction.
- When a transaction wants to commit, the database checks whether a bad situation has occurred.
- If it has, the transaction is aborted and retried.
- If contention is high, the abort rate increases and performance drops.
- If there is enough spare capacity and contention between transactions is not too high, optimistic concurrency control tends to perform well.
- SSI = snapshot isolation + an algorithm that detects serialization conflicts and decides which transactions to abort.
Detecting stale reads
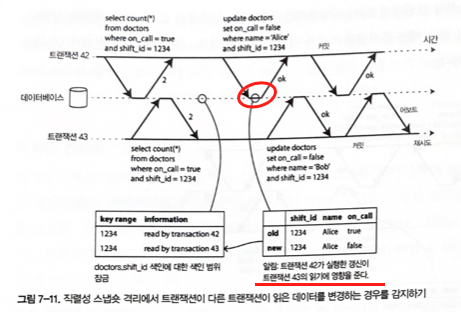
Figure 7-10. Detecting whether a transaction read a stale value from an MVCC snapshot
Detecting writes that affect past reads
Figure 7-11. Detecting when a transaction changes data read by another transaction under serializable snapshot isolation