Designing Data-Intensive Applications | Chapter 09. Consistency and Consensus
Presenters: Hojun Lee, Sungjik Jo
This chapter introduces algorithms and protocols used to build fault-tolerant distributed systems.
Consistency Guarantees
Weak guarantees, such as eventual consistency, are common in replicated databases. The system may converge eventually, but it does not say when. Stronger guarantees are easier to reason about, but they often reduce performance or fault tolerance.
Linearizability
Linearizability is one of the strongest commonly used consistency models. It makes a replicated system behave as if there were only one copy of the data. It also provides a recency guarantee: once a write has completed, later reads must return that value or a newer one.
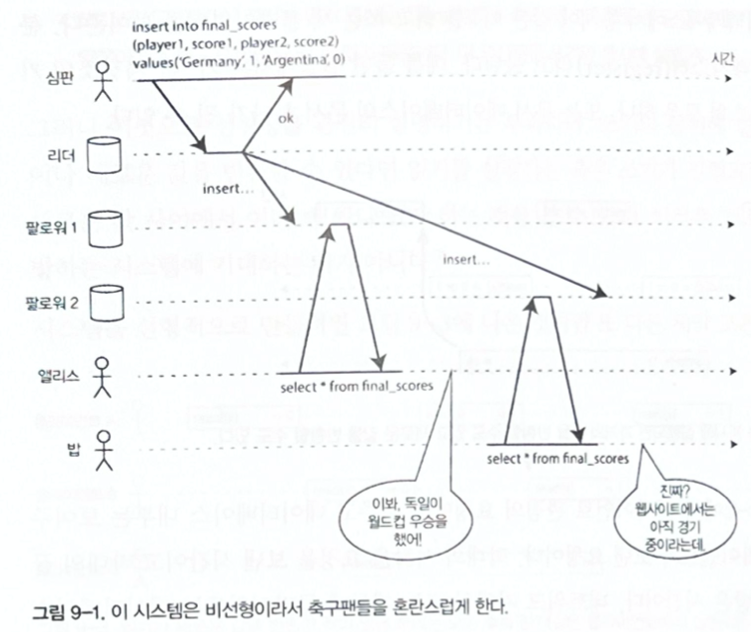
Figure 9-1. A non-linearizable system can confuse users.
If a read overlaps with a write, it may return either the old value or the new value. But once any read has returned the new value, all later reads, whether from the same client or another client, must also return the new value.
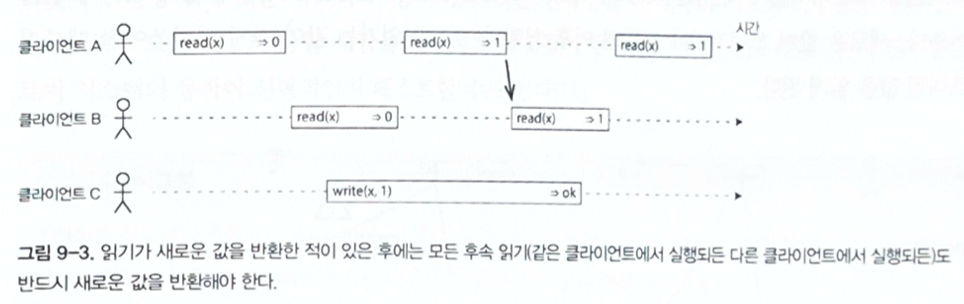
Figure 9-3. After a read has returned the new value, all later reads must return the new value.
Linearizability can be visualized by choosing a single point in time at which each operation appears to take effect.
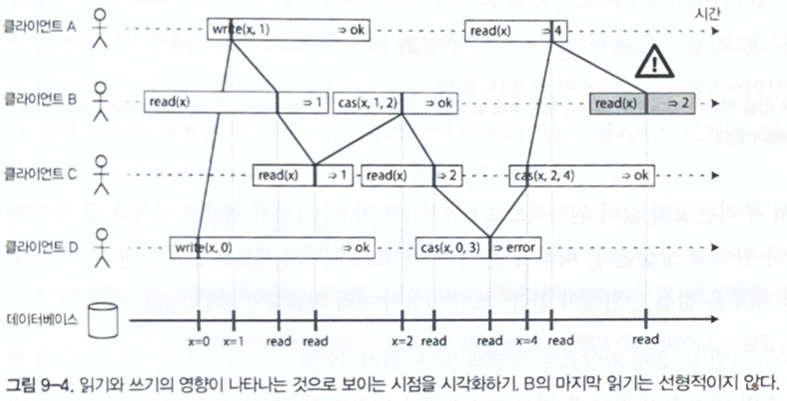
Figure 9-4. Visualizing the point where each read or write appears to take effect.
Linearizability is useful for locks and leader election. A system must not accidentally have two leaders. Coordination services such as ZooKeeper and etcd often provide linearizable operations for this purpose.
It also helps avoid timing dependencies between communication channels. For example, if a web server writes an image to a file store and sends a message to an image-resizing worker, the worker must not see a stale version of the file.
Implementing Linearizable Systems
Linearizability means behaving as if there is one copy of the data and every operation on it is atomic. A truly single copy cannot tolerate faults, so replication is still necessary.
Replication methods differ:
- Single-leader replication can be linearizable if reads go through the leader or are otherwise guaranteed to be up to date.
- Consensus algorithms can provide linearizability.
- Multi-leader replication is generally not linearizable.
- Leaderless replication is usually not linearizable unless extra coordination is added.
Linearizability and Quorums
Quorum reads and writes may appear linearizable when w + r > n, but races can still occur. Dynamo-style leaderless systems generally do not provide linearizability because doing so would add performance cost and require stronger coordination.
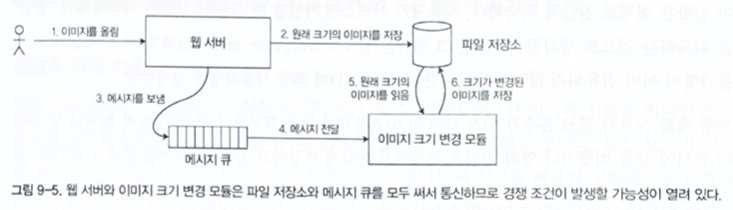
Figure 9-5. Even quorum reads and writes can produce race conditions.
The Cost of Linearizability
When a network interruption occurs, a system may need to choose between linearizability and availability.
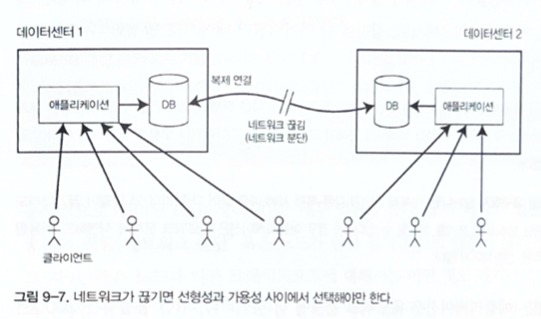
Figure 9-7. A network partition forces a choice between linearizability and availability.
The CAP theorem states that if a network partition occurs, a system that requires linearizability cannot remain fully available. This does not mean that networks are always partitioned, but it means a design must decide what happens when communication fails.
Ordering Guarantees
Ordering, causality, and consistency are closely related. If one event caused another, all nodes should observe them in that causal order. Causal order is weaker than total order, but still rules out many confusing histories.
Sequence numbers and timestamps can help order events. Physical clocks are imperfect in distributed systems, so logical clocks such as Lamport timestamps are often used to capture causal relationships.
Total order broadcast delivers every message to every node in the same order. It is equivalent in power to consensus and is a fundamental building block for replicated state machines.
Distributed Transactions and Atomic Commit
Atomic commit ensures that all participants in a transaction either commit or abort. It is especially important when a transaction affects multiple nodes or multiple systems.
Two-phase commit (2PC) uses a coordinator and participants:
- The coordinator sends a prepare request. Each participant checks whether it can commit and writes enough information to durable storage to make that decision recoverable.
- After receiving all responses, the coordinator decides commit or abort and records the decision.
- The coordinator sends the final decision to all participants, which then commit or abort accordingly.
If a problem happens before the prepare phase completes, the coordinator can abort. If a problem happens after participants have prepared, they must wait for the coordinator’s final decision. This can block resources.
Three-phase commit was proposed to avoid blocking, but it assumes bounded network delays and bounded node response times. Those assumptions are unrealistic for many distributed systems.
Distributed Transactions in Practice
Distributed transactions have a mixed reputation. They provide safety through atomic commit, but can cause operational problems and performance issues.
There are two broad kinds:
- Database-internal distributed transactions occur between nodes of the same distributed database. The database can choose and optimize its own protocol.
- Heterogeneous distributed transactions span different systems, such as two databases from different vendors or a database and a message broker. They require a common protocol.
XA is a standard for implementing heterogeneous distributed transactions with two-phase commit. It defines an interface between transaction coordinators and resource managers, and is supported by many relational databases and message brokers.
XA can leave transactions in doubt if the coordinator fails. Participants must keep locks until a final decision is known. If the coordinator’s transaction log is lost or software bugs occur, administrators may need to make a heuristic decision manually.
Distributed transactions also make the coordinator a single point of failure unless it is made highly available. If the coordinator is embedded in an application server, that server becomes stateful because it stores a transaction log locally. XA also only provides the common denominator of features across participating systems.
Fault-Tolerant Consensus
Consensus means getting several nodes to agree on a value. A consensus algorithm should provide:
- Uniform agreement: no two nodes decide differently.
- Integrity: no node decides twice.
- Validity: if a node decides value
v, thenvwas proposed by some node. - Termination: every non-failed node eventually decides a value.
The first three properties are safety properties. Termination is a liveness property and requires assumptions about failures and timing. Consensus algorithms generally assume that a majority of nodes are available and that Byzantine faults are out of scope.
Consensus and Total Order Broadcast
Total order broadcast has the same core properties as consensus: all nodes deliver the same messages in the same order, messages are not duplicated, messages are not corrupted, and messages are eventually delivered.
Single-leader replication resembles total order broadcast because the leader determines the order of writes. However, if the leader fails, the system must agree on a new leader. Solving that safely requires consensus or a service that already provides it.
Epoch Numbers and Quorums
Consensus systems use epoch numbers, terms, or ballots to distinguish one leader’s authority from another’s. A leader must prove that it is still valid, usually by communicating with a quorum. This prevents an old leader from continuing to accept writes after a newer leader has been elected.
The difference from two-phase commit is that fault-tolerant consensus can still make progress as long as a majority is available, whereas 2PC can block if the coordinator fails at the wrong time.
Limitations of Consensus
Consensus requires synchronous replication to a quorum, which adds latency. A majority must be available, so losing too many nodes makes the system unavailable. Changing the set of nodes is delicate, and networks with unstable latency can trigger repeated elections or degraded performance.
Membership and Coordination Services
Systems such as ZooKeeper and etcd provide a small set of coordination primitives on top of consensus:
- Linearizable atomic operations.
- Total ordering of operations.
- Failure detection through leases and sessions.
- Change notifications when data changes.
These primitives are useful for assigning work to nodes, service discovery, leader election, membership tracking, and cluster configuration.
Summary
Linearizability offers a simple mental model but costs availability under network partitions. Atomic commit coordinates all-or-nothing decisions across participants, but can block. Consensus lets distributed systems agree safely despite failures, and coordination services expose consensus through practical primitives such as locks, leases, membership, and notifications.