What Is Stream Processing? Introduction to OSS Engines
What is stream processing?
For example, imagine using sensors to sort T-shirts moving along a conveyor belt by color and pack them into boxes.
In this case, “streaming data” and “stream processing” mean the following:
- Streaming data: T-shirt images sent by the sensor
- Stream processing: AI determines the color in real time based on the T-shirt images received from the sensor
Stream processing vs batch processing
This section compares stream processing and batch processing to clarify the characteristics of stream processing.
The difference between stream processing and batch processing is the difference in the time axis.
| Stream processing | Batch processing | |
|---|---|---|
| Goal | Prioritizes real time | Prioritizes throughput |
| Processing timing | When streaming data occurs | When hardware resources are available |
| Processing time | A few milliseconds to a few seconds | A few minutes to a few hours |
| Use cases | Credit card fraud detection Real-time game world rankings IoT device data analysis |
Nightly batch jobs Monthly store processing |
As these use cases show, stream processing is used when data generated endlessly over time must be processed in real time.
For example, fraudulent credit card use must be detected and stopped as quickly as possible, even one second earlier. Processing it next month would be too late.
What is streaming data?
Streaming data is also called an “event stream” or “data stream.”
Besides being unbounded, streaming data has the following three characteristics:
- Ordered
- Immutable data records
- Replayable (a desirable characteristic)
Ordered
Events, which are the individual records in streaming data, have an order.
For example, event 1, “transfer 2,000,000 won as salary,” and event 2, “withdraw 500,000 won,” have an order. If event 2 is processed first for an account with a balance of 0 won, the account will become overdrawn.
Immutable data records
Once an event occurs, it cannot be deleted or changed.
For example, the event “withdraw 500,000 won” cannot be deleted or modified later. To cancel this event, you create a new event such as “deposit 500,000 won.”
Replayable
Because streaming data is ordered and consists of immutable data records, it can be reproduced.
For example, from the following event list, you can find the current balance as well as the balance at any point in time.
- Event 1: Open an account with a balance of 0 won
- Event 2: Deposit 500,000 won
- Event 3: Deposit 1,000,000 won
- Event 4: Withdraw 500,000 won
- Event 5: Deposit 500,000 won
- Event 6: Withdraw 1,000,000 won
Reconstructing data in a past state from an event list is called materialization. If you materialize the “balance data” at the end of event 4, the result is “1,000,000 won.”
Time concepts in stream processing
Because stream processing can process streaming data based on time, it is important to define accurate time concepts. Stream processing uses the following three time concepts:
- Event Time
- Ingest Time
- Processing Time
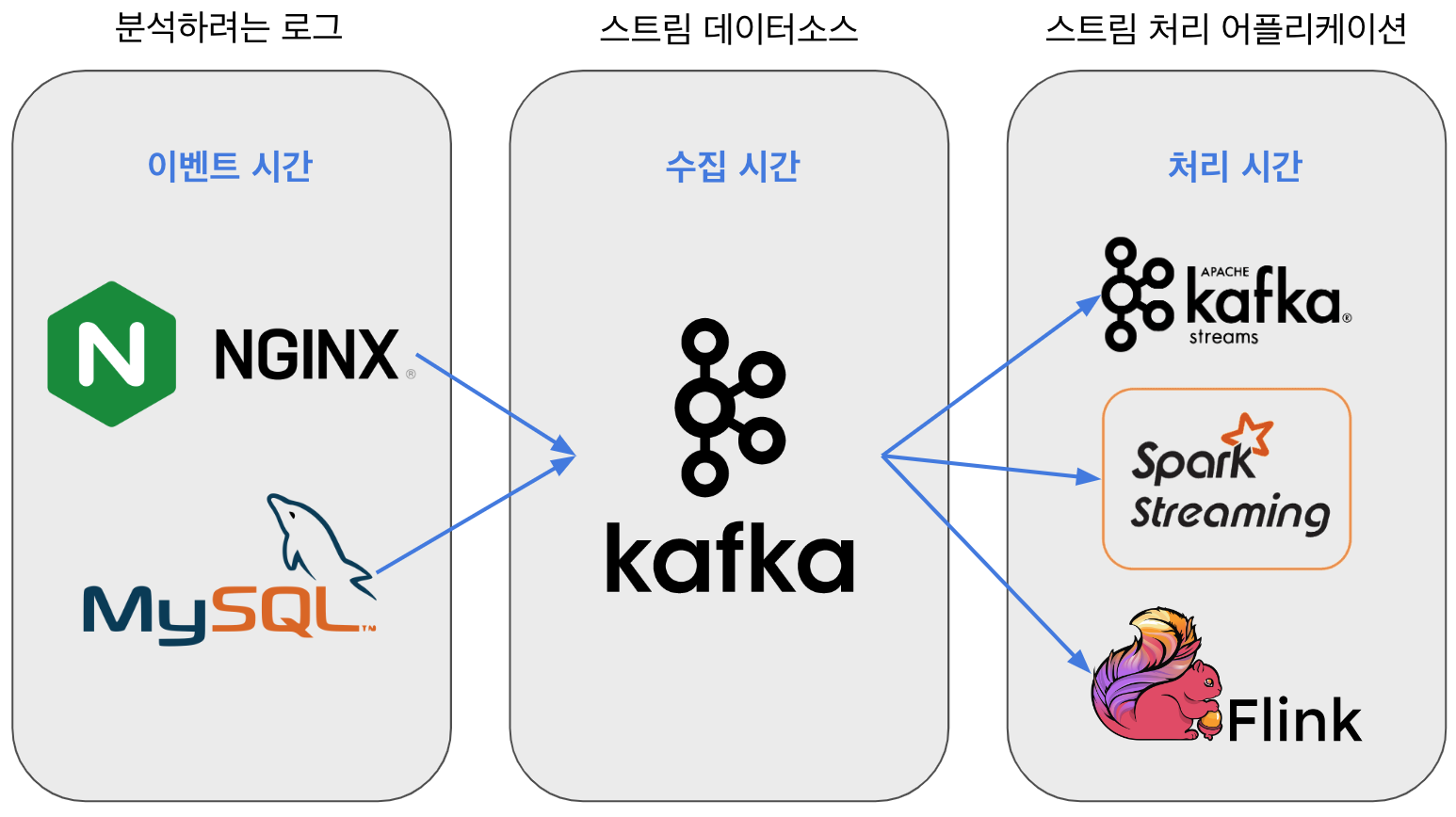
Event Time
Event Time is used to analyze streaming data.
- Peak access times for a website
- Product types whose sales increase by hour
Ingest Time
Because stream processing runs in real time, “Event Time” and “Ingest Time” are usually almost the same.
If arrival is delayed by a network failure or a similar issue, a gap appears between “Event Time” and “Ingest Time.”
Processing Time
If there is a large gap between “Processing Time” and “Ingest Time,” the application side may not be keeping up with stream processing.
Time Window
In stream processing, you can operate on streaming data using time-based windows.
In a time window, the window size is determined based on time, such as processing records accumulated every 10 seconds.
Time windows are mainly divided into the following three types according to how often the window moves, or advances:
| Window movement frequency (advance interval) | Duplicate processing | |
|---|---|---|
| Tumbling window | Same as the window size. | No |
| Hopping window | Smaller than the window size. | Yes |
| Sliding window | Every time an event in the window changes. | May occur |
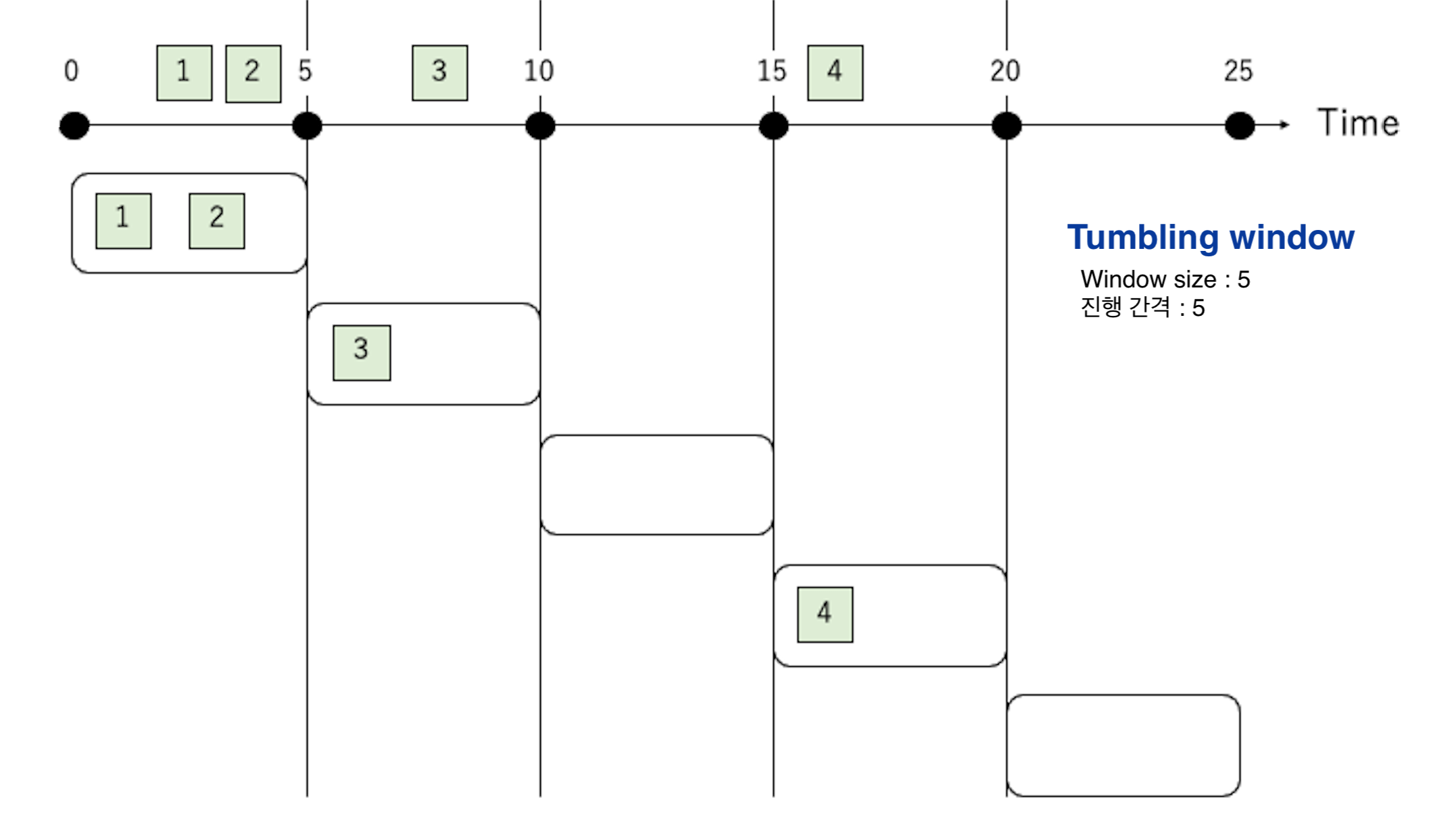
Tumbling window
A tumbling window is a window type where the movement frequency and the window size are the same.
Its characteristic is that processing for events does not overlap.
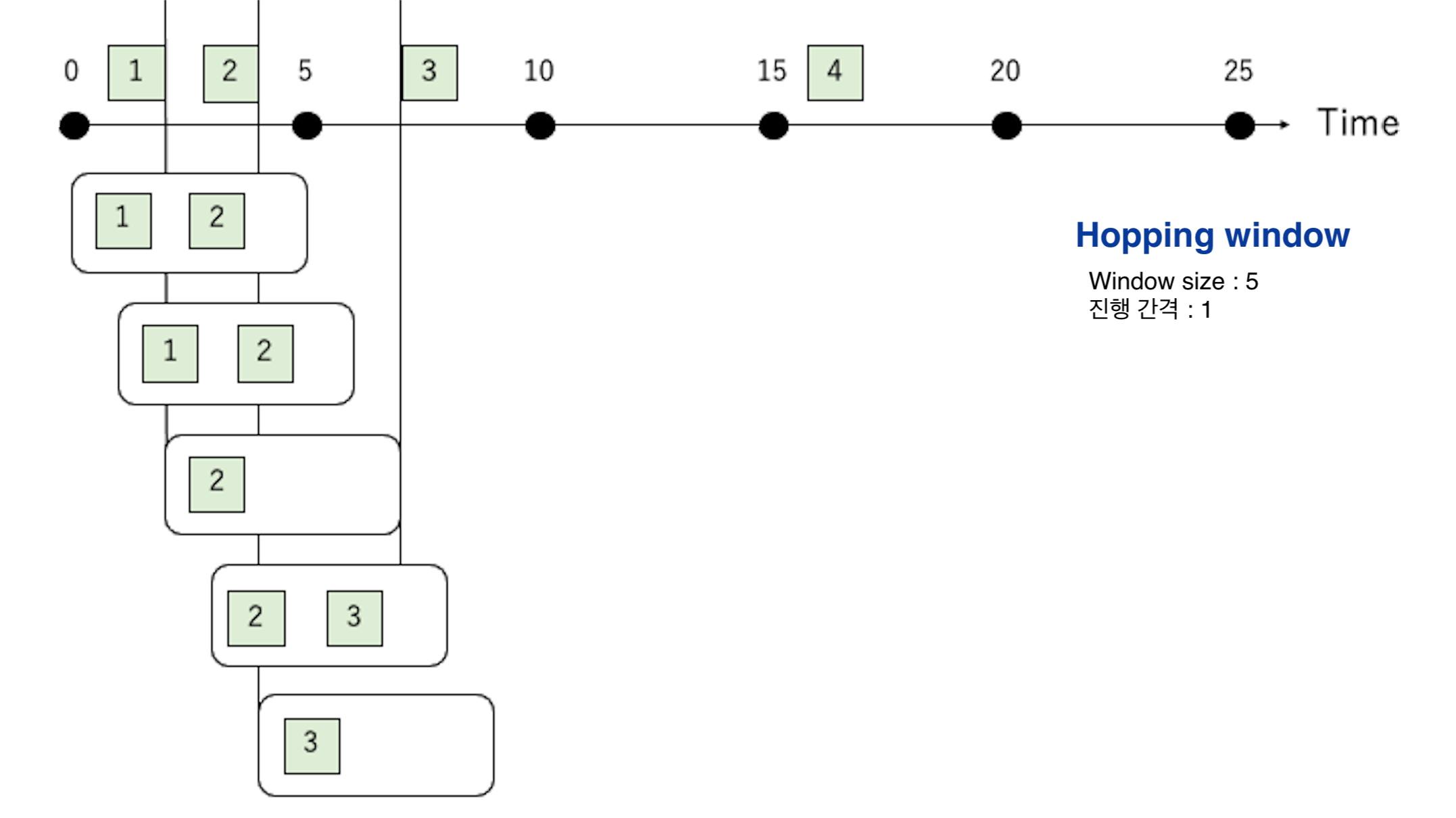
Hopping window
A hopping window is a window type where the window size is larger than the movement frequency.
Its characteristic is that processing for events overlaps.
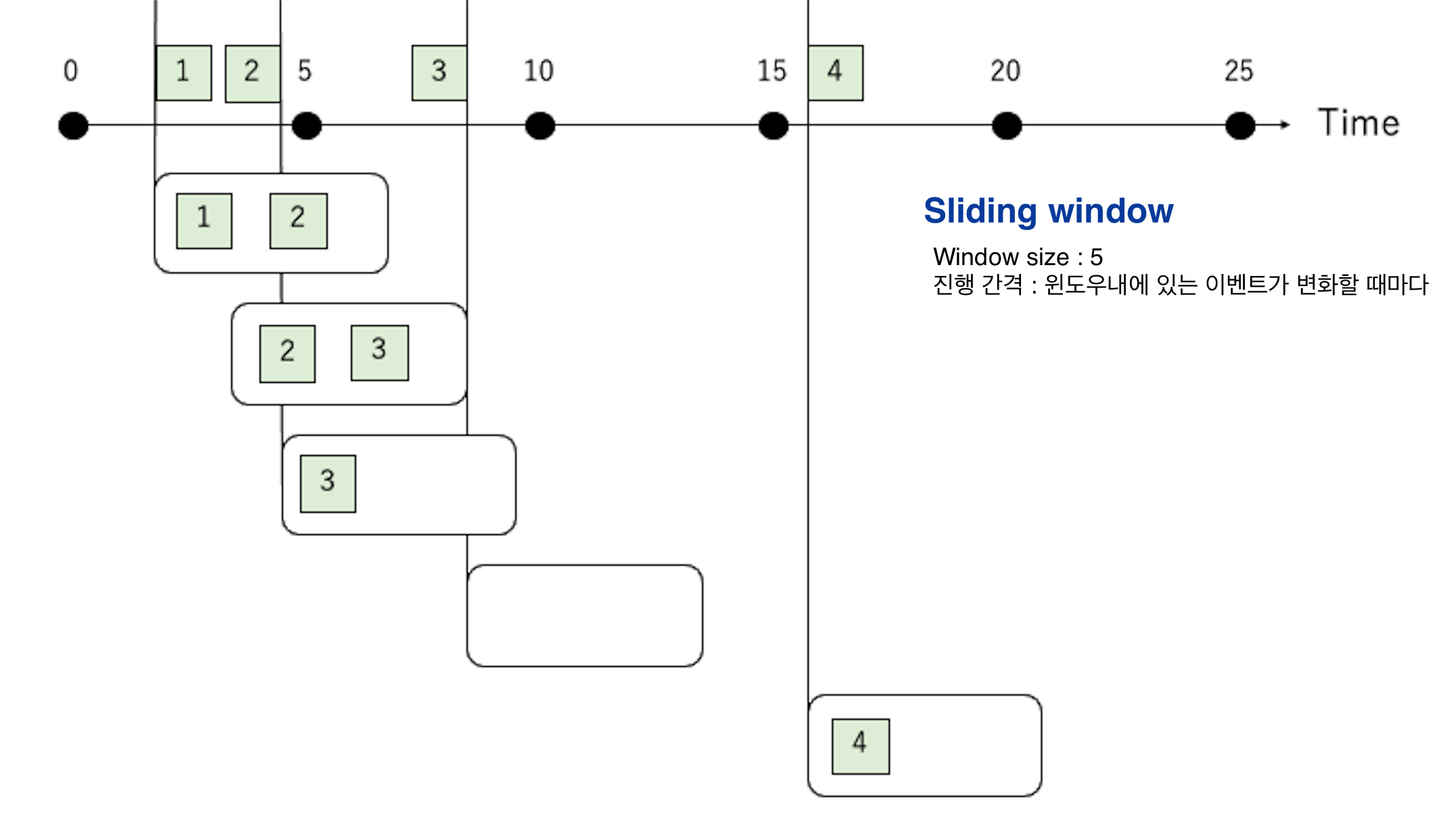
Sliding window
A sliding window is a window type where movement occurs whenever an event within the window changes.
When no event in the window changes, no operation is performed. In the case of an SQL query, no result is output.
OSS and services for stream processing
Stream processing can be performed using the following two components:
- A distributed streaming data source, which queues events
- A distributed stream processing application, which performs stream processing on events in the queue
Distributed streaming data sources
Distributed streaming data sources mainly use the following Pub/Sub messaging queues:
- Apache Kafka
- Amazon Kinesis Data Streams
Engines used in distributed stream processing applications
Distributed stream processing applications mainly use the following distributed processing engines:
- Kafka Streams (Apache Kafka Streams API)
- Kinesis Data Analytics
- Apache Flink
- Apache Spark Streaming
- Apache Storm
- Apache Samza
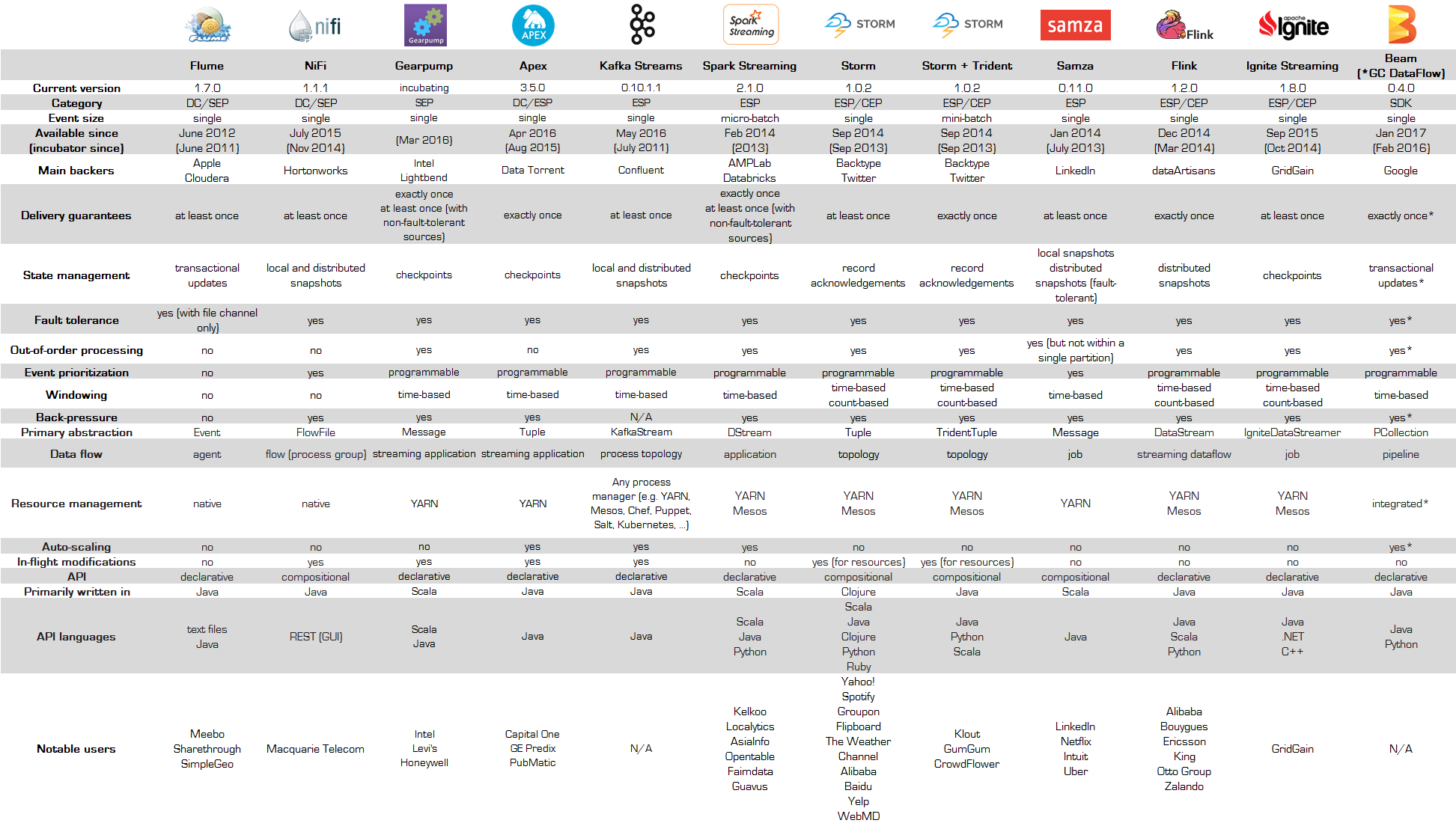
https://databaseline.tech/an-overview-of-apache-streaming-technologies/
Company stream processing examples
Examples of companies using stream processing with Apache Kafka and Kafka Streams include the following:
- LINE: Multi-Tenancy Kafka cluster for LINE services with 250 billion daily messages
- Cerner: Kafka use case at major healthcare IT company Cerner
- Bosch: Tools Streams IoT Data with Confluent Cloud