Detailed Kafka Concepts | What Is Kafka, Really?
What Is Kafka, Really?
Kafka is middleware called an event streaming platform. Originally, it may have been called a stream buffer.
The official documentation describes it as follows.
Kafka combines three key capabilities so you can implement your use cases for event streaming end-to-end with a single battle-tested solution:
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner.
In other words, Kafka is a platform that can write and read event streams, continuously import data from other systems or export data to them, retain that data for a certain period or indefinitely, and process events both as they occur and retrospectively. It also supports distributed processing and scalability.
The platform consists of the following components.
- Kafka Broker, the middleware itself
- Kafka Client, client libraries for communicating with the middleware
- Administrative commands implemented by those clients
- Kafka Streams and Kafka Connect, frameworks for application development
What Is an Event Stream?
An event stream is a continuous flow of data.
In system terms, it is a data flow that captures data movements generated by databases, mobile devices, and other sources in real time. Each occurrence or change in data is called an event, and a continuous sequence of those events is called an event stream. By processing event streams quickly, a system can immediately deliver up-to-date results to users.
Because event streams are continuous and are usually expected to be processed at near real-time intervals, processing is basically performed record by record. For processing that spans multiple records, such as aggregation, developers need to define the necessary data range themselves and prepare separate storage to accumulate that information.
Kafka’s ecosystem includes libraries needed to implement realistic use cases for this kind of stream processing.
Kafka can handle multiple event streams, and these are called topics. A topic is an event stream that can be managed by name.
Topics and Partitions
Each topic is divided into one or more partitions. A topic also has a replication factor, which sets how many replicas of each partition exist. If the replication factor is 3, it means there are three replicas of a partition’s data inside the cluster.
One replica of a partition is maintained by one node.
For example, if “TopicA” has 8 partitions and a replication factor of 3, a total of 24 partition replicas are distributed across nodes in the cluster.
The output of the kafkacat or kcat command looks like this. The cluster has five nodes.
topic "TopicA" with 8 partitions:
partition 0, leader 5, replicas: 5,3,1, isrs: 1,5,3
partition 1, leader 3, replicas: 3,4,2, isrs: 4,2,3
partition 2, leader 1, replicas: 1,4,2, isrs: 1,4,2
partition 3, leader 4, replicas: 4,2,5, isrs: 4,2,5
partition 4, leader 2, replicas: 2,5,3, isrs: 2,5,3
partition 5, leader 5, replicas: 5,2,3, isrs: 2,5,3
partition 6, leader 3, replicas: 3,5,1, isrs: 1,5,3
partition 7, leader 1, replicas: 1,5,3, isrs: 1,5,3
Each row of data stored in a topic is called a record, and a record consists of a key-value pair. For Kafka Brokers, keys and values are simply byte arrays, and clients distinguish what format the data has. The actual format depends on serialization, such as JSON-serialized data, binary data serialized by Avro or Protocol Buffers, plain character strings, or raw byte arrays interpreted as numbers.
Why Is Kafka Needed?
Kafka has a very broad range of applications, so it is hard to explain in one phrase. It can be used for the following purposes.
- Message broker for loose coupling between systems and improved scalability
- Behavior tracking in web systems
- Metric recording for monitoring system load and other values
- Log aggregation
- Event sourcing
Kafka Is Not a Queue
Kafka can behave like a queue and is sometimes called a distributed queue, but strictly speaking it is not a queue.
Kafka retains event streams for a certain period. Even when a Consumer processes data, the retained data does not change, unlike in a queue. In a queue, once a Consumer processes data, that data is deleted from the queue and can no longer be used by another worker. Also, the next record is basically not processed until the leading data disappears. AWS SQS works this way, though ordering can be controlled to some extent with visibility timeout. In AWS, Kinesis, a real-time data analytics processing system, is relatively close to Kafka. Amazon Managed Streaming for Apache Kafka, MSK, is also available.
Benefits of Not Being a Queue
Topic Sharing
The fact that data remains available means one topic can be shared by multiple systems. A data source only needs to send data to Kafka, and multiple microservices can operate from it. The data source does not need to know what services exist downstream. Each service only needs to know which topic it uses, retrieve data from that topic, and perform its own processing. If a new service wants to use the data, the data source does not need to add a new destination. Kafka’s core middleware is called a message broker because it can mediate messages and keep services loosely coupled in this way.
Durability
Because data is not changed when a Consumer processes it, data is not lost even if an error occurs during Consumer processing and the processing node goes down. Therefore, even if an error occurs in a Consumer, the data does not need to be requeued. Another node can continue processing from the same offset without losing data. If Redis is used as a processing queue, as in Sidekiq, data may be lost if a worker does not handle errors correctly. If a process suddenly dies due to OOM, recovery may be impossible. Kafka avoids that concern.
However, unless exactly-once mode is used, retries may cause duplicate processing, so idempotency and consistency need separate attention.
Historical Data Can Be Used
Kafka retains data for a certain period, seven days by default, and unlike a queue, data can be read from any offset. Therefore, processing can be started by using past data.
For example, when adding a new microservice, it can start processing from some amount of historical data. Even if a service has been stopped for a period, if the data up to the time it stopped remains when it resumes, processing can safely continue.
Complexity Caused by Not Being a Queue
Offset Recording
Unlike a queue, data is not deleted, which means the Consumer must remember how far it has processed records. Therefore, Kafka Consumer clients need a place to record offsets. Kafka’s protocol uses the Kafka Broker as the offset recording location. Because Kafka Brokers can retain data indefinitely, they can also be used as storage for each client’s offset information. Updating the offset information that records how far the client has processed is also an event, and it is an event stream that continues to be updated. Kafka stores this in the Broker itself, and the client reads the offset information from the topic when starting. The latest value remaining in the Broker becomes the offset of the last processed record.
For reference, AWS Kinesis records this kind of offset information in DynamoDB.
Consumer Group
Offset recording is not the only complexity caused by Kafka not being a queue. Because a Consumer’s processing does not change the Broker data, if multiple workers try to process the same topic, offset recording alone would cause the same processing to be duplicated by the number of workers.
For this reason, Kafka Consumers have a concept called Consumer Group. A Consumer Group is a set that indicates the purpose for which Kafka is being used, and Consumers belong to it when obtaining data from Brokers.
Within the same Consumer Group, Kafka allows a partition of a specific topic to be processed by only one Consumer in that group. One Consumer can process multiple partitions and topics.
The diagram is as follows.
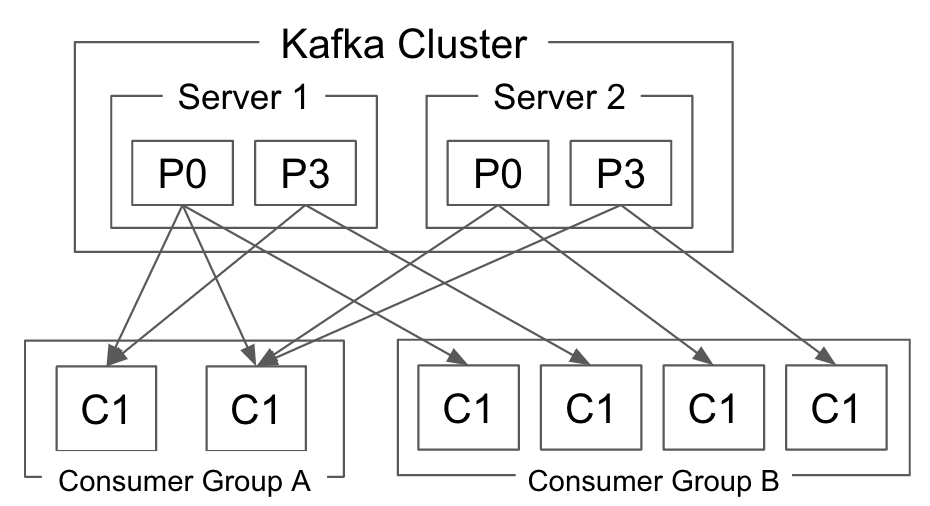
Therefore, the number of Consumers processing one topic cannot exceed the total number of partitions in that topic. If a topic has 30 partitions, the number of Consumers that can process that topic is limited to 30. This is the total number of instances, regardless of whether there are 30 on one node or one each on 30 nodes.
Kafka Brokers Do Not Partition Data
One major characteristic of Kafka is that the Broker is not responsible for partitioning. In Kafka, partitioning is done by the Producer.
When a data source sends a record to a Kafka Broker, the client library implementation determines the partition. Therefore, different client libraries may have different partitioning logic. For example, the default partitioning logic in the Java Producer calculates a Murmur2 hash for the key and uses the remainder after dividing by the total number of partitions. In contrast, the Ruby implementation ruby-kafka calculates a CRC32 hash and uses the remainder in the same way. Ruby also has a gem implemented as bindings for the C library librdkafka, where the hash can be selected from CRC32, Murmur2, fnv1a, and others. As a result, even when sending the same data, the partition ID can differ depending on the client implementation.
Strictly speaking, the record key and partitioning are not directly tied together. Using the record key is only the default behavior. A client can partition arbitrary data with arbitrary logic and directly specify the resulting partition in the record sent to the Broker.
For example, even when using ruby-kafka, if the same hash value can be calculated internally with Murmur2, the partition calculated from that value can be specified directly in the record, allowing data to be sent to the same partition as with the Java library.
Keeping partitioning logic consistent is very important in real systems.
For example, suppose you want to aggregate the daily access count of one user, ID 100. You may need all records for that user to be processed on one node. Consumer Groups guarantee that data from one partition is processed by only one node, so if records for user ID 100 are consistently sent to a specific partition, each node only needs to store aggregation results locally for the data it receives. If a new producer is later added and the client library implementation differs, causing different partitioning results, the aggregation results may be stored in inconsistent locations and the aggregation will be incorrect.
Therefore, it is very important to understand which key and which algorithm are used to partition the data in a topic.
In general, aligning with the official client’s Murmur2-based partitioning implementation is likely the safest approach.
The Importance of Estimating Partition Count
One of the most difficult factors when operating Kafka Brokers in practice is choosing an appropriate number of partitions.
As mentioned earlier, only one client in the same Consumer Group can receive data from one partition of a topic. In other words, the upper limit on the number of clients that can scale is determined by the number of partitions.
Then, should you just increase the number of partitions later? In many cases, it is not that simple. As explained earlier, if processing moves because client partitioning logic differs, aggregation may no longer be correct. The same possibility occurs if the number of partitions changes later.
Partitioning basically hashes the key value and uses the remainder after division by the total number of partitions in the topic. If the total number of partitions changes, the partition assigned to the same data changes. As a result, the node performing final processing can also change, and aggregation processing may become inconsistent.
Therefore, changing the number of partitions later can sometimes be very difficult. It is very important to estimate the partition count after carefully considering how much the topic needs to scale. Basic estimation criteria include network throughput, required processing throughput, and processing latency.
As an additional note, you might think the application could be built so aggregation is unaffected even if processing nodes change. However, in stream processing, that is often an undesirable design. Aggregation in stream processing reads and writes data much more frequently than batch processing. A structure that stores data on another node through the network can introduce nontrivial latency, so unless it is truly necessary, it is generally something to avoid. More details on this point will be introduced later.
Summary
Kafka is a platform for processing large volumes of event data in real time, and its core is the middleware called Kafka Broker.
Event data includes user behavior logs, messages exchanged between systems, database change histories, and many other kinds of data.
Event data is stored in topics divided into multiple partitions. Stored data is a record composed of a key and value, and its contents are simply byte arrays.
Unlike a queue, Kafka Broker does not delete data when Consumers process it. This makes it easy for multiple systems to share the same topic, process historical data, and retry processing.
On the other hand, clients must understand which range of data they are responsible for processing, so concepts not found in queues, such as offset recording and Consumer Groups, become necessary.
Because partitioning is the client’s responsibility, it is important to understand the implementation of the client library when performing aggregation or other processing that depends on partitioning results.
Reference
Most of this content is explained in the official documentation.