Kafkaの詳細概念 | そもそもKafkaとは?
そもそもKafkaとは?
Kafkaはイベントストリーミングプラットフォームと呼ばれるミドルウェアである。もともとはストリームバッファと呼ばれていたかもしれない。
公式ドキュメントには次のように書かれている。
Kafka combines three key capabilities so you can implement your use cases for event streaming end-to-end with a single battle-tested solution:
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner.
つまり、イベントストリームを書き込んだり読み取ったりでき、他システムから継続的にimportしたりexportしたりできる。それを一定期間、または無期限に保持でき、イベント発生時に即時処理するだけでなく、過去にさかのぼって以前のデータを処理することもできるプラットフォームである。また、分散処理が可能で、スケール可能だとされている。
プラットフォームの構成要素は次のとおりである。
- Kafka Broker:ミドルウェア本体
- Kafka Client:ミドルウェアと通信するためのクライアントライブラリ
- 上記クライアントによって実装された管理コマンド群
- Kafka StreamsとKafka Connect:アプリケーション開発のためのフレームワーク
イベントストリームとは?
絶え間なく続くデータの流れをいう。
システム的には、データベースやモバイルデバイスなどによって発生したデータの動きをリアルタイムにキャプチャしたデータの流れといえる。それぞれのデータの発生や変化をイベントと呼び、それが絶え間なく連続して続くものをイベントストリームと呼ぶ。このイベントストリームを高速に処理できれば、システムはユーザーへ即座に最新の結果を届けられる。
イベントストリームは連続的に存在し、その目的上リアルタイムに近い間隔で処理することが求められるため、基本的には1件単位で処理を行う。集計など複数レコードにまたがる処理については、開発者自身が必要なデータ範囲を定義し、情報を蓄積しておくストレージを別途用意する必要がある。
Kafkaのエコシステムには、このようなストリーム処理で現実的なユースケースを実現するために必要なライブラリも用意されている。
Kafkaでは複数のイベントストリームを扱うことができ、これをTopicと呼ぶ。Topicは名前を付けて管理できるようにしたイベントストリームである。
TopicとPartition
各Topicは1つ以上のPartitionに分割される。またTopicにはreplication factorが設定され、各Partitionの複製がいくつ存在するかを設定できる。replication factorが3であれば、1つのPartitionのデータ複製がクラスター内部に3つ存在することを意味する。
1つのPartitionにある複製は1つのノードによって保持される。
たとえば、「TopicA」のPartition数が8でreplication factorが3の場合、クラスターに属する各ノードに合計24個のPartitionデータが分散して配置される。
kafkacat(kcat)コマンドの出力は次のようになる。ノード数は5台である。
topic "TopicA" with 8 partitions:
partition 0, leader 5, replicas: 5,3,1, isrs: 1,5,3
partition 1, leader 3, replicas: 3,4,2, isrs: 4,2,3
partition 2, leader 1, replicas: 1,4,2, isrs: 1,4,2
partition 3, leader 4, replicas: 4,2,5, isrs: 4,2,5
partition 4, leader 2, replicas: 2,5,3, isrs: 2,5,3
partition 5, leader 5, replicas: 5,2,3, isrs: 2,5,3
partition 6, leader 3, replicas: 3,5,1, isrs: 1,5,3
partition 7, leader 1, replicas: 1,5,3, isrs: 1,5,3
Topicに保存するデータの1行1行をRecordと呼び、Recordはキーと値のペアで構成される。Kafka Brokerにとってキーと値は単なるバイト列であり、クライアントがどの形式のデータであるかを区別する。たとえばJSONでシリアライズされたデータ、AvroやProtocol Buffersでバイナリシリアライズされたデータ、単なる文字列、バイト列をそのまま数値として利用する場合など、形式はシリアライズ方式に依存する。
なぜKafkaが必要なのか?
Kafkaは応用範囲が非常に広いため、一言で説明するのは難しいが、次のように活用できる。
- システムの疎結合化と拡張性向上のためのメッセージブローカー
- Webシステムの行動追跡
- システム負荷などを監視するためのメトリクス記録
- ログ集約
- イベントソーシング
Kafkaはキューではない
Kafkaはキューのように動作でき、分散キューとも呼ばれるが、正確にはキューではない。
Kafkaはイベントストリームを一定期間保持しており、Consumerがそれを処理しても、キューと違って保持しているデータは変更されない。キューの場合、Consumerがデータを処理するとそのデータはキューから削除され、他のWorkerは利用できなくなる。また、基本的には先頭のデータが消えない限り次のRecordは処理されない。たとえばAWS SQSはそのように動作する(visibility timeoutである程度順序は制御できる)。AWSではKinesis(リアルタイムデータ分析処理システム)が比較的Kafkaに近いサービスである。現在はAmazon Managed Streaming for Apache Kafka(MSK)も提供されている。
キューではないことによる利点
Topic共有
データが保持され続けるということは、1つのTopicを複数のシステムで共有できることを意味する。つまり、データソースはKafkaへデータを送信するだけで、複数のマイクロサービスを動作させることができる。データソース側は、下流にどのサービスがあるかを知る必要はない。各サービス側は自分がどのTopicを利用するかだけを知っていればよく、そこからデータを取り出して自分の処理を行えばよいため、データの発生元を知る必要がなくなる。もしデータを利用したいサービスが増えても、データの発生元で宛先を追加する必要はない。Kafkaの本体となるミドルウェアをメッセージブローカーと呼ぶのは、このようにメッセージを仲介してサービス間を疎結合に保つ役割を持てるためである。
耐久性
Consumerがデータを処理してもデータが変更されないということは、Consumerの処理中にエラーが発生して処理ノードごとダウンしても、データが失われないことを意味する。したがってConsumerでエラーが発生しても再キューする必要はなく、別のノードが同じOffsetから処理を続ければ、データを失わずに処理を戻せる。SidekiqのようにRedisを処理待ちキューとして使用する場合、処理中のWorkerがエラー処理を正しく行わなければデータが失われるリスクがある。OOMなどでプロセスが突然死した場合は復旧できない。Kafkaではその心配が不要である。
一方、exactly onceモードを使用しない限り、retryによって二重処理される可能性があるため、冪等性や整合性には別途注意が必要である。
過去データを利用できる
Kafkaは一定期間(デフォルトでは7日間)のデータを保持しているうえ、キューと異なり任意のOffsetからデータを読める。そのため、過去データを利用して処理を開始できる。
たとえば、新しくマイクロサービスを追加したとき、ある程度過去のデータから処理を開始できる。また、一定期間停止しているサービスがあっても、再開時に停止したタイミングまでのデータが残っていれば、安全に処理を再開できる。
キューではないことによる複雑性
Offset記録
キューと異なりデータが削除されないということは、Consumer側で自分がどこまでRecordを処理したかを記憶しなければならないことを意味する。そのためKafkaのConsumerクライアントにはOffsetを記録する場所が必要になる。Kafkaのプロトコルでは、Offset記録場所としてKafka Brokerを利用する。Kafka Brokerは無期限にデータを保持できるため、各クライアントのOffset情報を記録するストレージとしても利用できる。クライアントがどこまで処理したかを示すOffset情報の更新もイベントの1つであり、それが継続的に更新されるイベントストリームでもある。これをKafka Broker自身に保存し、クライアントは起動時にそのOffset情報をTopicから読む。Brokerに残っている最新値が、これまで処理したRecordのOffsetになる。
参考までに、AWS KinesisはこのようなOffset情報をDynamoDBに記録する。
Consumer Group
キューと異なることで発生する複雑性はOffset記録だけではない。Consumerの処理によってBrokerのデータが変化しないため、複数のWorkerが同じTopicを処理しようとすると、Offset記録だけではWorkerの数だけ同じ処理が重複して実行されてしまう。
そのためKafka ConsumerにはConsumer Groupという概念が存在する。Consumer Groupは、どのような目的でKafkaを利用しているかを示す集合であり、Consumerはそれに属してBrokerからデータを得る。
同じConsumer Groupに属している場合、Kafkaは特定TopicのPartitionを、そのGroup内の1つのConsumerでのみ処理できるようにする(1つのConsumerが複数のPartitionやTopicを処理することはできる)。
図で見ると次のようになる。
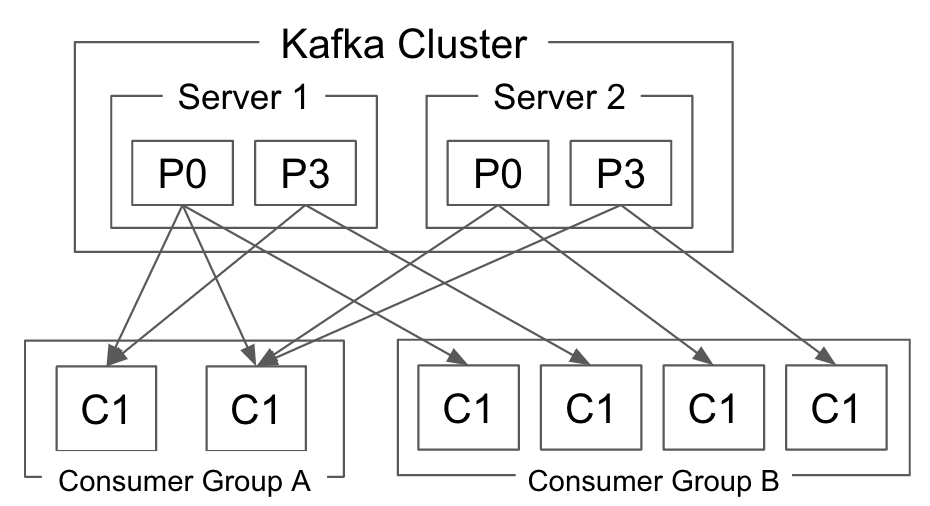
したがって、1つのTopicのPartition総数以上に、そのTopicを処理するConsumerを増やすことはできない。Partition数が30なら、そのTopicを処理できるConsumer数は30に制限される。この数は総インスタンス数であり、同じノードに30個ある場合と、30ノードに1つずつある場合は同じである。
Kafka Brokerはパーティショニングしない
Kafkaの大きな特徴の1つとして、パーティショニングを行う主体がBrokerではない点がある。KafkaではパーティショニングはProducerが行う。
データソースがKafka BrokerへRecordを送るとき、クライアントライブラリの実装によってPartitionが決定される。そのため、クライアントライブラリが異なるとパーティショニングロジックも異なる場合がある。たとえばJava Producerのデフォルトパーティショニングロジックは、キーに対してMurmur2によるハッシュを求め、その結果をPartition総数で割った余りを利用する。一方、Rubyのruby-kafkaという実装ではCRC32でハッシュを求め、同じように余りを利用する。またRubyにはlibrdkafkaというCライブラリのバインディングとして実装されたgemもあり、ハッシュをCRC32、Murmur2、fnv1aなどから選択できる。このように、同じデータを送信してもクライアント実装によってPartition IDが異なることがある。
また厳密にいえば、Recordのキーとパーティショニングには直接的な関連はない。あくまでデフォルト動作としてRecordのキーを利用しているだけであり、クライアントは任意のデータを任意のロジックでパーティショニングし、その結果をRecordに直接指定してBrokerへ送ることができる。
たとえばruby-kafkaを使用していても、内部でMurmur2ハッシュを使って同じハッシュ値を求められれば、それをもとに算出したPartitionをRecordへ直接指定することで、Javaライブラリと同じPartitionへRecordを送ることができる。
パーティショニングロジックを同じにすることは実システムで非常に重要である。
たとえば、あるユーザー(ID:100)の日次アクセス数を集計したい場合、ID:100のユーザーレコードを1つのノードで処理する必要があるかもしれない。Consumer Groupは1つのPartitionのデータが1つのノードでのみ処理されることを保証するため、ID:100のユーザーレコードが一貫して特定のPartitionへ送信されるなら、各ノードは単に受け取ったデータをローカルに集計結果として蓄積すればよい。このとき、新しいProducerが追加され、クライアントライブラリの実装が異なるためにパーティショニング結果が揃わなくなると、集計結果の蓄積場所がばらばらになり、正しく集計できなくなる。
このように、どのキーとどのアルゴリズムによってそのTopicのデータがパーティショニングされているかを把握することは非常に重要である。
基本的には、公式クライアントの実装であるMurmur2を利用したパーティショニングに合わせておくのが最も安全だと考えられる。
Partition数算定の重要性
Kafka Brokerを実際に運用するとき、非常に難しい要素の1つがPartition数を適切に選ぶことである。
前述のとおり、同じConsumer Groupでは1つのTopicの1つのPartitionから1つのクライアントだけがデータを受け取れる。つまり、スケールできるクライアント数の上限はPartition数によって決まる。
それなら後からPartition数を増やせばよいのではないか、と思うかもしれない。しかし実際にはそう簡単ではないケースも多い。前に説明したように、パーティショニングロジックが異なるクライアントへ処理が移動すると集計処理が正しく実行されない可能性があるのと同様に、Partition数が後から変わると同じことが起こる可能性がある。
パーティショニングは基本的にキー値をハッシュし、TopicのPartition総数で割った余りを使用する。Partition総数が変わると、同じデータが割り当てられるPartitionが変わり、最終的に処理しているノードも変化するため、集計処理がずれる事態が発生する。
したがって、後からPartition数を変更することは非常に厄介な作業になる場合がある。実際にこのTopicをどの程度まで拡張したいかをよく考え、Partition数を算定することが非常に重要である。基本的な算定基準は、ネットワークスループット、要件で求められる処理スループット、処理にかかるレイテンシである。
補足すると、処理ノードが変わっても集計処理に影響がないようにアプリケーションを構築すればよいのではないか、と思うかもしれない。しかしストリーム処理における集計では、バッチ処理よりもはるかに多くデータを受け取って書き込む。そのため、ネットワークを介して別ノードにデータを保持する構造は無視できないレイテンシ増加を招くことがあり、本当に必要でなければ避けたい設計である。この点の詳細は後で改めて紹介する。
まとめ
Kafkaは大量のイベントデータをリアルタイムに処理するためのプラットフォームであり、その中核を成すのがKafka Brokerというミドルウェアである。
イベントデータには、ユーザーの行動ログ、システム間のメッセージ交換、データベース変更履歴など、さまざまなものが含まれる。
イベントデータは複数のPartitionに分割されたTopicに保存される。保存されたデータはキーと値で構成されたRecordであり、内容は単なるバイト列である。
Kafka Brokerはキューと異なり、Consumerの処理によってデータが削除されない。そのため、複数のシステムで同じTopicを共有したり、過去にさかのぼってデータを処理したり、retryしたりすることが容易である。
一方、自分がどの範囲のデータを処理する責任を持つかはクライアント自身が認識する必要があり、Offset記録やConsumer Groupなど、キューにはない概念が必要になった。
パーティショニングの責任はクライアントが持つため、Partition結果に依存する集計処理などを実行するときは、クライアントライブラリの実装を把握しておくことが重要である。
参考
この内容の大部分は公式ドキュメントで説明されている。