データ指向アプリケーションデザイン | 第05章 レプリケーション
発表者: イ・ホジュン、チョ・ソンジク
Part 2. 分散データ
第1部では、単一のマシンにデータを保存する場合のデータシステムを見た。第2部では、複数のマシンが関与する場合を扱う。
データを分散する理由はいくつかある。
スケーラビリティ
データ量や読み書き負荷が1台のマシンで扱える範囲を超える場合、負荷を複数のマシンに分散する。
耐障害性と高可用性
1台のマシンが停止しても、他のマシンがあればアプリケーションは動作を継続できる。
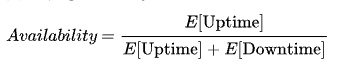
レイテンシ
世界中にユーザーがいる場合、ユーザーに近いデータセンターにデータを置くことで応答時間を短縮できる。
垂直スケーリングと水平スケーリング
垂直スケーリング、つまりスケールアップは、より強力なマシンを使うことである。多くのCPU、メモリ、ディスクを1つのOSイメージにまとめる。共有メモリや共有ディスクのアーキテクチャは有用な場合もあるが、高価であり、耐障害性とスケーラビリティには限界がある。
水平スケーリング、つまりスケールアウトは、独立した多数のノードを使うことである。各ノードは独自のCPU、メモリ、ディスクを持ち、ネットワーク越しにソフトウェアで協調する。コスト効率のよいハードウェアを使え、地理的にデータを分散でき、データセンター全体の障害の影響も減らせる。ただし、分散システム特有の制約とトレードオフも発生する。
レプリケーション
レプリケーションとは、ネットワークで接続された複数のマシンに同じデータのコピーを保持することである。ユーザーに地理的に近い場所へデータを置く、一部のシステムが故障しても動作を継続する、読み取りクエリに答えるマシンを増やして読み取りスループットを上げる、といった目的で使われる。
レプリケーションが難しいのは、データが変更されるからである。中心的な課題は、複製されたデータの変更をどう処理するかである。
代表的なアルゴリズムには、単一リーダー、複数リーダー、リーダーレスのレプリケーションがある。それぞれ長所と短所が異なる。
リーダーとフォロワー
レプリカとは、データベースのコピーを保存するノードである。リーダーベースレプリケーションでは、1つのレプリカがリーダーに指定される。クライアントは書き込みをリーダーへ送り、リーダーは変更をフォロワーへ送る。
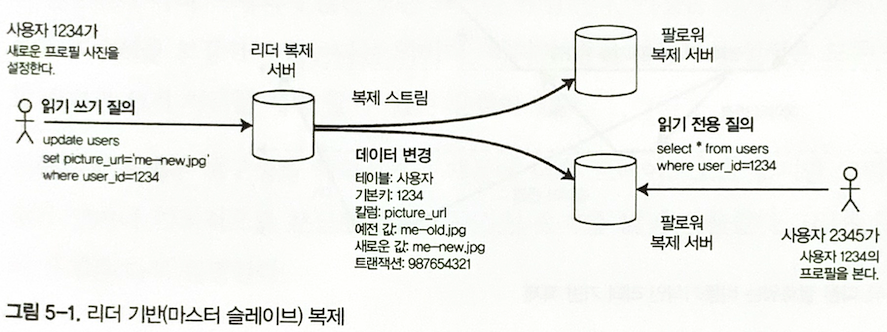
図5-1. リーダーベースレプリケーション。
リーダーはプライマリまたはマスターとも呼ばれ、書き込みと多くの場合読み取りを処理する。フォロワーはリードレプリカ、スレーブ、セカンダリ、ホットスタンバイとも呼ばれ、リーダーの変更ログを受け取ってローカルコピーを更新する。多くのRDBMS、NoSQLシステム、メッセージブローカーがこの方式を使っている。
同期レプリケーションと非同期レプリケーション
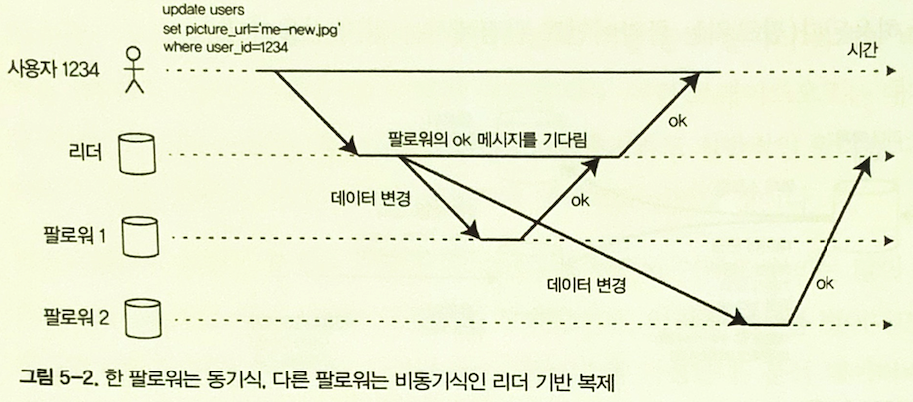
図5-2. 1つのフォロワーは同期式、もう1つは非同期式。
同期レプリケーションでは、リーダーはフォロワーが書き込みを受信したことを確認してからクライアントへ成功を返す。フォロワーが最新データを持つことは保証されるが、フォロワーが遅い、または利用できない場合は書き込みがブロックされる。
非同期レプリケーションでは、リーダーはフォロワーを待たない。レイテンシが低く可用性も高いが、変更がフォロワーへ届く前にリーダーが失敗すると、確認済みの書き込みが失われる可能性がある。
半同期構成では、1つのフォロワーを同期式にし、残りを非同期式にする。同期フォロワーが使えなくなれば別のフォロワーを同期式にできる。完全な非同期レプリケーションは、多数のフォロワーや地理的に分散したノードがある場合によく使われるが、耐久性の保証は弱くなる。
新しいフォロワーの設定
読み取り能力を増やす場合や故障ノードを置き換える場合、新しいフォロワーが必要になる。単にデータファイルをコピーするだけでは不十分である。コピー中にも書き込みが続くためである。データベースをロックすれば可用性を損なう。
一般的な手順は、書き込みを止めずにリーダーの一貫したスナップショットを取得し、それを新しいフォロワーへコピーし、その後スナップショット以降のすべての変更をリーダーへ要求することである。バックログを処理し終えれば、フォロワーは追いついた状態になり、以後の変更を処理できる。
ノード停止の処理
フォロワー障害はキャッチアップ復旧で処理する。フォロワーは受信した変更ログをローカルに保存する。再起動または再接続後、最後に処理したトランザクション以降の変更をリーダーへ要求し、それらを適用する。
リーダー障害ではフェイルオーバーが必要になる。フォロワーの1つを新しいリーダーへ昇格させ、クライアントはそこへ書き込みを送り、他のフォロワーは新リーダーから変更を受け取る。フェイルオーバーは手動でも自動でも行える。
自動フェイルオーバーでは、リーダー障害を検出し、新しいリーダーを選び、クライアントとフォロワーを再設定する必要がある。障害検出にはタイムアウトがよく使われるが、誤検出も起こり得る。
フェイルオーバーの問題
非同期書き込みが古いリーダーで確認済みだが新しいリーダーへ複製されていなかった場合、フェイルオーバーでデータが失われる可能性がある。死んだと判断された旧リーダーが戻ってくると、2つのリーダーが書き込みを受け付けるスプリットブレインが発生することもある。短すぎるタイムアウトは不要なフェイルオーバーを起こし、長すぎるタイムアウトは停止時間を延ばすため、設定は難しい。
レプリケーションログの実装
レプリケーションはいくつかの方法で実装できる。
- 文ベースレプリケーションはSQL文をフォロワーへ送るが、非決定的関数、自動採番、トリガー、副作用によって不整合が起こり得る。
- write-ahead logの配送はストレージエンジンの低レベルなログレコードを送る。この方式はレプリケーションをストレージ形式に強く結び付ける。
- 論理ログレプリケーションは挿入、更新、削除された行を表す行レベルのレコードを使う。バージョン間の互換性を保ちやすい。
- トリガーベースレプリケーションはアプリケーションコードで変更を捕捉して複製するが、複雑で遅くなりやすい。
レプリケーションラグの問題
非同期レプリケーションでは、フォロワーがリーダーより遅れるレプリケーションラグが発生する。その結果、ユーザーが古いデータを読むことがある。
read-after-write一貫性は、ユーザーが自分自身の書き込みを読めることを保証する。単調読み取りは、新しいレプリカを読んだ後に古いレプリカを読んで時間が戻ったように見えることを防ぐ。一貫したプレフィックス読み取りは、因果関係のある書き込みが正しい順序で観測されることを保証する。
読み取りをフォロワーへ分散してスケールさせる場合、レプリケーションラグは特に目立つ。アプリケーションは、より強いユーザー体験上の保証を提供するため、ルーティング、タイムスタンプ、バージョン追跡、セッションアフィニティなどを必要とすることがある。
複数リーダーレプリケーション
複数リーダーレプリケーションでは、複数のノードが書き込みを受け付ける。各リーダーは自分の変更を他のリーダーへ送る。複数データセンター間では、ユーザーが近いデータセンターへ書き込め、別のデータセンターが利用できなくても動作を続けられるため有用である。
主な問題は書き込み競合である。2つのリーダーが同じデータを同時に更新することがある。競合は、レコードごとに同じリーダーへ書き込みを送って回避する、決定的な規則で自動収束させる、競合バージョンをすべて残してアプリケーションに解決させる、または独自の競合解決ロジックを使う、といった方法で処理する。
複数リーダーレプリケーションは、オフライン対応クライアントや共同編集にも使われる。複数のレプリカが独立して変更を受け付け、後で同期するためである。
リーダーレスレプリケーション
リーダーレスレプリケーションでは、クライアントが複数のレプリカへ直接書き込むか、コーディネータが代行する。読み取りも複数のレプリカへ問い合わせ、返されたバージョンを突き合わせる。
レプリカ数をn、書き込みクォーラムをw、読み取りクォーラムをrとすると、w + r > nであれば読み取りは直近の成功した書き込みと重なるはずである。たとえばn = 3、w = 2、r = 2なら、少なくとも1つの読み取りレプリカは最新値を含むはずである。
ただしクォーラムは完全な一貫性保証ではない。同時書き込み、sloppy quorum、ネットワーク分断、遅延した修復によって、古い値や競合する値が生じることがある。
Sloppy quorumとhinted handoff
ネットワーク障害中、クライアントが十分な数の本来のレプリカへ到達できないことがある。sloppy quorumでは、到達可能な別のノードが書き込みを受け付ける。後でhinted handoffにより、その書き込みを本来のレプリカへ戻す。可用性は高まるが、一貫性保証は弱くなる。
同時書き込みの検出
リーダーレスシステムでは、同時書き込みを検出して解決する必要がある。last-write-winsは単純だがデータを失う可能性がある。より安全な方法は、複数のバージョンを保持し、クライアントにマージさせることである。happens-before関係とバージョンベクタは、ある書き込みが別の書き込みを上書きするのか、2つの書き込みが同時なのかを判断する助けになる。
まとめ
レプリケーションは局所性、可用性、読み取りスケーラビリティを改善するが、ラグ、フェイルオーバーの複雑さ、競合処理を持ち込む。単一リーダーレプリケーションは単純だがリーダーのフェイルオーバー問題がある。複数リーダーレプリケーションは地理的可用性を高めるが競合解決が必要である。リーダーレスレプリケーションはクォーラムにより高可用性を提供するが、アプリケーションは同時バージョンを理解し処理しなければならない。