データ指向アプリケーションデザイン | 第04章 エンコーディングと発展
発表者: ファン・ユンホ
アプリケーションは時間の経過とともに必然的に変化する。
新しい製品をリリースしたり、ユーザー要件やビジネス環境が変わったりすると、アプリケーションの機能は追加または変更される。
この変化にはDBの変化も含まれ、カラムやフィールドが追加または削除されることもある。
このようなDB視点の変更はすぐに適用できる。しかし、applicationのコードは多くの場合すぐには適用されない。
Applicationコードがすぐに適用されない理由
- codeのupdate方式はrolling update方式で進められる。
- clientの場合、すぐにアップデートしないユーザーもいるためである。
互換性
- 後方互換性
- 新しいコードは、古いコードが記録したデータを読めなければならない。
- 新しいコードは既存データを知っているため、大きな問題にはなりにくい。
- 前方互換性
- 古いコードは、新しいコードが記録したデータを読めなければならない。
- 新しいバージョンで追加されたものを無視できなければならないため、適用が難しい。
データエンコーディング形式
プログラムは通常、2つの形で表現されたデータを使って動作する。
メモリ上では、オブジェクト、構造体、リスト、配列、ハッシュテーブル、ツリーなどとしてデータが保持される。
このようなデータ構造は、CPUが効率よくアクセスして操作できるように最適化される。
データをファイルに書き込んだりネットワーク経由で送信したりするには、自分自身を含む一連のバイト列の形にエンコードしなければならない。
ポインタは別のプロセスが理解できないため、この一連のバイト列は通常、メモリで使うデータ構造とはかなり異なる。
インメモリ表現からバイト列への変換をエンコーディング、シリアライゼーション、またはマーシャリングという。
その逆をデコーディング、パース、デシリアライゼーション、アンマーシャリングという。
例: Java Serializable、Ruby Marshal、Python pickleなど。
JSONとXML、バイナリ変種
標準化されたエンコーディングとして、JSONとXMLは人気のあるテキスト形式である。
JSONとXMLは広く知られており多くの場所でサポートされているが、その分好みが分かれることもある。
特にXMLは、不要で複雑だと批判される。
強力ではないが、CSVも人気のある言語非依存の形式である。
数値のエンコーディングには多くの曖昧さがある。整数と浮動小数点数を区別せず、精度も指定しない。
この曖昧さは大きな数を扱うときに問題になる。2^53より大きい整数を扱うと不正確になることがある。
JSONとXMLはUnicode文字列をよくサポートするが、バイナリ文字列はサポートしない。
このような欠点があっても、JSON、XML、CSVは十分に使いやすく人気がある。
特にデータ交換形式として非常に適している。
Binary Encoding(バイナリエンコーディング)
JSONやXMLと比べて、より少ない領域で済み、より簡潔で、パースも高速である。データセットが小さければ大きな意味はないが、テラバイト級になると話は変わる。
JSONもバイナリ形式と比べるとより多くの領域を使う。
この観点から、JSONで利用できるMessagePack、BSON、BJSON、BISON、Smileなどのバイナリエンコーディングが開発された。
ただし、JSONほど使われてはいない。
例4-1:
{ //1 byte
"userName" :"Martin", // 20 byte
"favoriteNumber" :1337, // 22 byte
"interests":["daydreaming", "hacking"] // 37 byte
} // 1 byte
JSONをバイナリエンコードしても、オブジェクトのフィールド名を含めなければならない。これは81バイトになる。
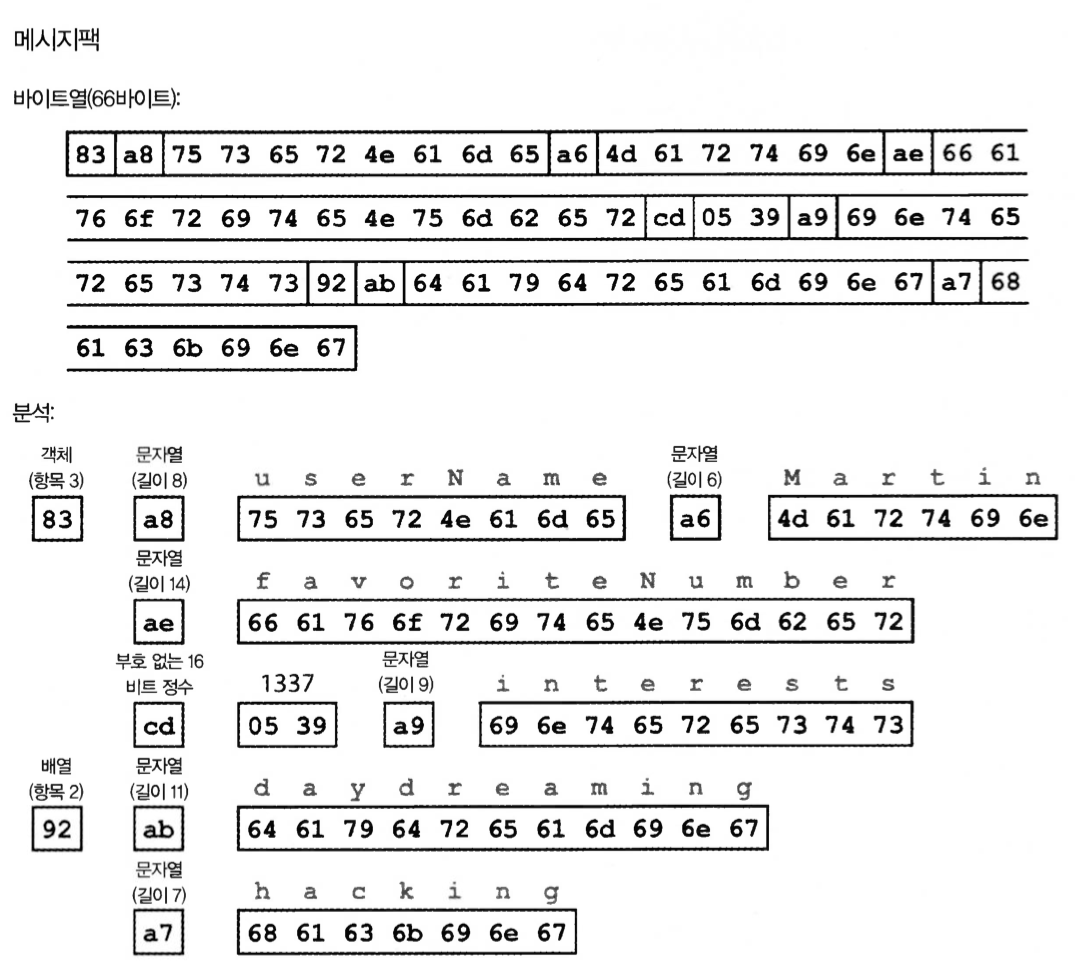
図4-1. MessagePackでエンコードしたサンプルレコード(例4-1)
JSONバイナリエンコーディングは66バイト、16進数。
参考:
- 0x83 = 0x80(オブジェクト)、0x03(フィールド): 3つのフィールドを持つオブジェクト
- 0xa8 = 0xa0(文字列)、0x08(8バイト)
- cd = 16バイトの数値、16^2 * 5 = 1280。16 * 3 = 48。9 = 1337
ASCII - 위키백과, 우리 모두의 백과사전 msgpack/spec.md at master | msgpack/msgpack | GitHub
ThriftとProtocol Buffers
Apache ThriftとProtocol Buffersは、同じ原理に基づくバイナリエンコーディングライブラリである。
Protocol BuffersはGoogleが開発し、ThriftはFacebookが開発した。現在はいずれもオープンソースである。
どちらもエンコードするデータのためのスキーマが必要である。
# Thrift schema
struct Person {
1:required string userName,
2:optional i64 favoriteNumber,
3:optional list<string> interests
}
# Protocol Buffers schema
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
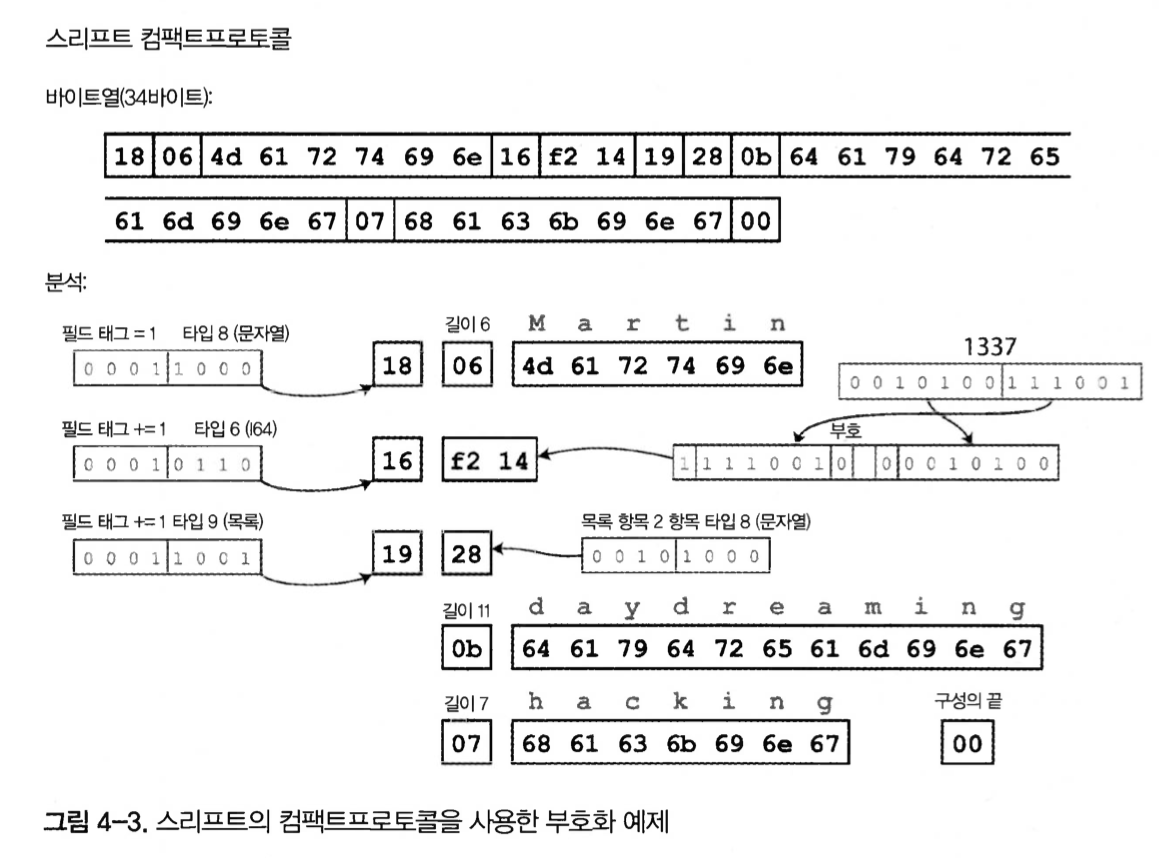
図4-3. ThriftのCompact Protocolを使ったエンコーディング例
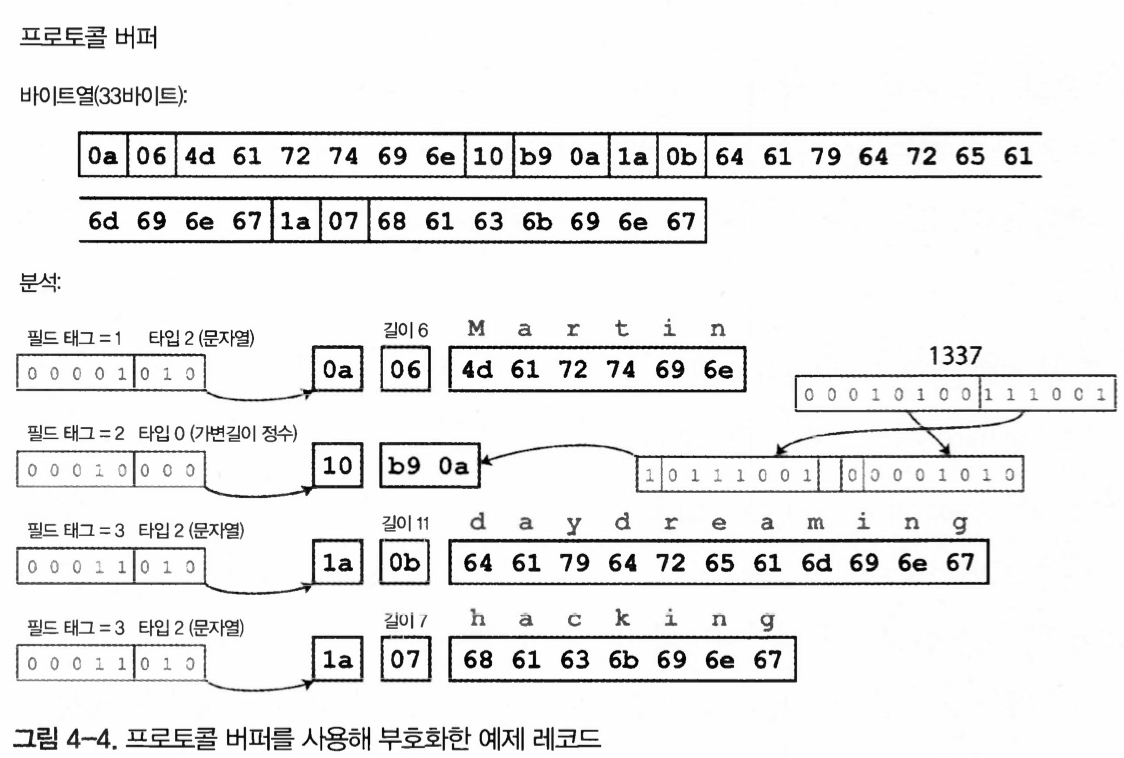
図4-4. Protocol Buffersを使ってエンコードしたサンプルレコード
どちらのプロトコルも、スキーマを使うことでバイト数が大幅に減る。
最も大きな違いは、フィールド名の代わりにフィールドタグ、つまり1、2、3を含める点である。
この数字はスキーマ定義に現れる数字である。
フィールドタグとスキーマ発展
スキーマは時間の経過とともに必然的に変化する。これをスキーマ発展という。
どのように前方互換性と後方互換性を維持しながら変更するのか。
- 前方互換性(古いコードは現在のデータを読めなければならない)
- 新しいコードで記録したデータを読もうとするとき、認識できるtag番号かどうかだけを確認し、認識できなければ自然に無視する。
- 後方互換性(現在のコードは古いコードで生成したデータを読めなければならない)
- 最初のデプロイ後はrequiredとしてfieldを追加できない。古いコードで生成したデータを読めなくなるためである。
- optional fieldだけを削除できる。
Avro
Apache Avroは、Protocol BuffersやThriftとは異なるが、それらに対抗できるもう一つのバイナリエンコーディング形式である。
ThriftがHadoopのユースケースに合わなかったため、2009年にHadoopのサブプロジェクトとして始まった。
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null","long"], "default": null},
{"name": "interests","type": {"type": "array","items": "string"}}
]
}
図4-5. Avroを使ってエンコードしたサンプルレコード
32バイトで最も短い。
- フィールドやデータ型を識別するための情報がない。
- Avroを使ってparsingするには、schemaを先に読み、各フィールドのデータ型を覚えておく必要がある。
書き込みスキーマと読み取りスキーマ
- file、db、networkを通じて送信する目的でエンコードするために使う。
- applicationをビルドする間にスキーマを生成する。
- 書き込みと読み取りのスキーマは異なっていてもよい。また、フィールドの順序が違っても問題ない。
- 存在しないフィールドを作る場合、このフィールドを無視した後、デフォルト値で埋める。
Avroのスキーマ発展ルール:
- 前方互換性
- 新しいバージョンの書き込みスキーマと、古いバージョンの読み取りスキーマを持てる。
- フィールド名は変更できない。
- 後方互換性(古いデータを現在も読める)
- 新しいバージョンの読み取りスキーマと、古いバージョンの書き込みスキーマを持てる。
- フィールド名の変更を追跡できるため、フィールド名の変更が可能である。
この互換性を維持するため、defaultがあるフィールドだけを追加・削除できる。
古いスキーマにない値が読み取りスキーマにある場合は、デフォルト値に置き換える。
Avroはスキーマが動的に変更される可能性を考慮して設計されている。
コード生成と動的型付け言語
- ThriftとProtocol Buffersはコード生成に依存する。
- Java、C++、C#のような静的型付け言語で有用である。
- スキーマが変更されると再コンパイルが必要である。 Avroはこの観点から、コンパイル言語とインタプリタ言語を選択して使える。
スキーマの利点
- Protocol Buffers、Thrift、Avroはスキーマを使ってバイナリエンコーディング形式を記述する。
- このスキーマ言語はXMLやJSONスキーマよりはるかに単純で、より詳細な検証ルールをサポートする。
- エンコードされたデータではフィールド名を省略できるため、dataサイズをJSONより小さくできる。
- schema databaseを使えば、前方互換性と後方互換性を確認できる。
データフローモード
あるプロセスから別のプロセスへデータを渡す方法:
- DBを通じて
- サービス呼び出しを通じて
- 非同期メッセージ送信を通じて
データベースを通じたデータフロー
- データベースに記録するプロセスはデータをエンコードし、読むプロセスはデコードする。
- 単一プロセスでDBにアクセス
- DBに保存することは、未来の自分にメッセージを送ることである。
- 後方互換性が明らかに必要である。
- さまざまなプロセスがDBにアクセス
- 一般的なapplicationやサービスの方式である。
- ローリング方式でデプロイする場合、新しいバージョンをデプロイしているいくつかのinstanceは、古いコードでデータを保存し更新している可能性がある。
- 前方互換性が必要である。
- エンコーディングは知らないフィールドを触らないが、DB視点ではデータが失われることがある。
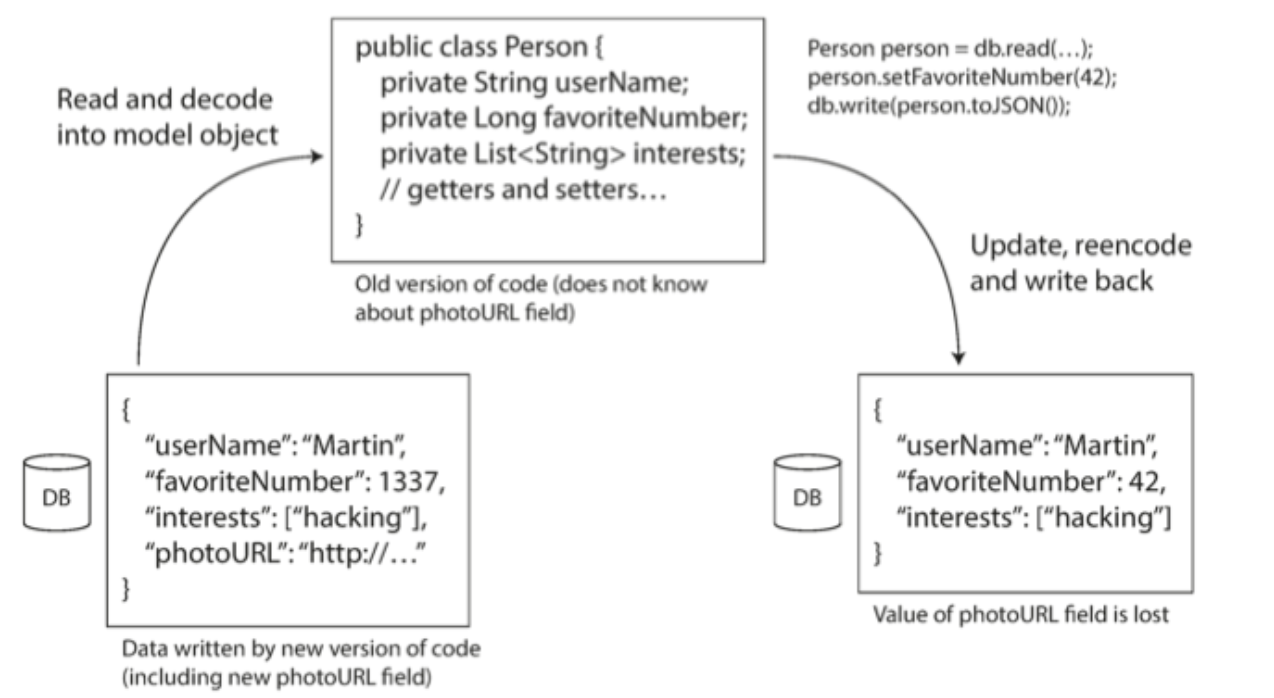
図4-7. 新しいバージョンのアプリケーションが記録したデータを古いバージョンのアプリケーションが更新した場合、注意しないとデータが失われることがある。
注意しないと、このようにデータ更新時に新しいフィールドのデータが失われることがある。
さまざまな時点に記録されたさまざまな値
- DBはいつでもデータを更新できる。
- このデータは5年前のデータかもしれないし、5ミリ秒前に記録されたものかもしれない。
- DBで特別な機能を実行しなければ、元のエンコーディングのまま保持されているはずである。
- データを新しいスキーマで再記録することはできるが、マイグレーション作業には大きな費用がかかる。
アーカイブ保存
- バックアップ目的やデータウェアハウスへのロードのため、データベースのスナップショットを随時作成する。
- この場合、最新スキーマを使ってエンコードする。
サービスを通じたデータフロー: RESTとRPC
- ネットワークを通じて通信しなければならないプロセスがあるとき、その通信を配置する方法はいくつかある。
- 最も一般的な方法は、クライアントとサーバーという2つの役割に配置することである。
- サーバーがネットワークを通じてAPIを公開し、クライアントはこのAPIにリクエストを作ってサーバーへ接続する。
- サーバーが公開したAPIをサービスという。
Webは次のように動作する。
- クライアントはWebサーバーへリクエストを送る。
- GETリクエストを送り、HTML、CSS、JS、Imageなどを受け取る。
- サーバーはデータ送信のためにPOSTリクエストを受け取る。
- WebでWebブラウザだけが唯一のclientではない。
- モバイルデバイスやデスクトップネイティブアプリもサーバーへネットワークリクエストを送れる。
- サーバー自体が別のサービスのクライアントになることもある。
- 例えば、あるサービスが別のサービスの一部機能やデータを必要とするなら、そのサービスにリクエストを送る。
- このapplication開発方式は伝統的にサービス指向設計(SOA)と呼ばれた。
- 最近ではこれをさらに改善し、マイクロサービス設計という名前で再登場した。
サービスとDatabaseはいくつかの面で似ている。ただし違いは、serviceはビジネスロジックに基づいて入出力を制限し、定められた入出力だけを許可してAPIを公開することである。
MSA、SOAの目標は、サービスをデプロイと変更に対して独立させ、applicationの保守をより簡単にすることにある。
つまり頻繁な変更に対応するためのものであり、新しいバージョンのリリースが速いためAPI間の互換性が必要である。この点が本章の核心である。
Webサービス
- サービスと通信するための基本プロトコルとしてHTTPを使う場合、これをWebサービスという。
- Webサービスには、RESTとSOAPという2つの代表的な方式がある。
REST
- HTTPの原則を基に設計した原則である。
- 単純なデータ型を重視する。
- URLを使ってResourceを識別し、キャッシュ制御、認証、コンテンツタイプネゴシエーションを行う。
- SOAPより人気がある。
SOAP
- ネットワークAPIリクエストのためのXMLベースのプロトコルである。
- 一般的にはHTTP上で使うが、HTTPとは独立しておりHTTP機能を使わない。
- その代わり、多様な機能を追加した広範囲で複雑な関連標準を提供する。
- 人が読めないように設計されており、ツールやIDEに大きく依存する。
- 多くの場合、RESTful APIによる単純なアプローチが好まれる。
リモートプロシージャ呼び出し(RPC)の問題
- Webサービスは、network上でAPIを呼び出すいくつかの技術のうち、最も新しい形にすぎない。
- Webサービスは、1970年代から使われてきたリモートプロシージャ呼び出し(RPC)の考え方を基盤にしている。
- RPCモデルは、リモートnetworkサービスへのリクエストを、同じprocess内で特定のmethodを呼び出すかのように使えるようにする。
- RPCは最初は便利に見えるが、RPCアプローチには根本的な欠陥がある。
- ローカル関数呼び出しは、結果を返すことも、例外を返さないこともある。
- 失敗したネットワークリクエストを再試行するとき、実際にはリクエストが処理され、応答だけが失われた可能性がある。
- ローカル関数を呼び出すたび、通常ほぼ同じ実行時間がかかる。
- ローカル関数を呼び出す場合、参照、つまりポインタをローカルメモリ上のオブジェクトに効率よく渡せる。
- クライアントとサービスは異なるプログラミング言語で実装できる。
RPCの現在の方向 このような問題にもかかわらずRPCは消えておらず、ここまで述べたバイナリエンコーディングの上にRPCフレームワークが開発されている。
- Thrift、AvroはRPCサポート機能を内蔵している。
- gRPCはProtocol Buffersを使ってRPCを実装した。
- FinagleはThriftを使い、Rest.liはHTTP上でJSONを使う。
データエンコーディングとRPCの発展
- 発展性を持たせるには、RPC clientとサーバーを独立して変更し、デプロイできなければならない。
- データベースを通じたデータフローと比べると、発展性に関する仮定を単純化できる。
- すべてのサーバーを先に更新し、その後すべてのクライアントを更新しても問題ないと仮定する。
- すると、リクエストには後方互換性だけが必要で、レスポンスには前方互換性だけが必要になる。
APIバージョン管理が必ずどの方式で動作すべきかについて合意はないが、一般的にはHTTP Acceptヘッダーにバージョン番号を使う方式がよく使われる。
メッセージ送信データフロー
- メッセージ送信データフローは、RPCとデータベースの間にある非同期メッセージ送信システムである。
- クライアントリクエストを低いレイテンシで別のプロセスへ渡すという点でRPCに似ている。
- メッセージを直接ネットワーク接続で送信しない。
- 一時的にメッセージを保存するメッセージブローカーを利用する。
- または、メッセージ指向ミドルウェアという中間段階を経由して送信する。
Message brokerを使ったときの利点:
- 受信者が利用できない、または過負荷状態なら、メッセージブローカーがバッファのように動作できる。
- 死んだプロセスにメッセージを再送信できるため、メッセージ損失を防げる。
- 送信者は受信者のIPアドレスやポート番号を知る必要がない。
- 1つのメッセージを複数の受信者へ送信できる。
- 論理的に送信者は受信者から分離されているだけで、誰が消費するかを気にしない。
メッセージ送信通信は、一般的に一方向である点がRPCと異なる。つまり、送信プロセスは通常、メッセージへの応答を期待しない。
メッセージブローカー
- 最近ではRabbitMQ、ActiveMQ、HornetQ、Apache Kafkaのようなオープンソース実装が普及した。
- 詳細な配信セマンティクスは実装と設定によってさまざまである。
- しかし、一般的なメッセージブローカーは次のように使う。
- メッセージ名が指定されたキューやトピックへ送信される。
- ブローカーは、そのキューやトピックの1つ以上のコンシューマーまたは購読者へメッセージを配信する。
- 同じトピックに複数の生産者と消費者が存在できる。
- トピックは一方向のデータフローだけを提供する。
分散アクターフレームワーク
- アクターモデルは、単一プロセス内での並行性のためのプログラミングモデルである。
- スレッド競合条件、ロック、デッドロックを直接扱う代わりに、ロジックがアクターにカプセル化される。
- 各アクターは1つのクライアントまたはエンティティを表す。
- アクターはローカル状態を持つことができ、非同期メッセージの送受信によって他のアクターと通信する。
- アクターはメッセージ送信を保証しない。
分散アクターフレームワークはノード間でapplicationを拡張するために使われ、送信者と受信者が同じノードかどうかに関係なく、同じメッセージ送信構造を使う。別のノードであれば、メッセージはエンコードされ、networkを通じて送信される。
アクターモデルはメッセージが失われるという仮定を持つため、位置透過性はRPCよりactorモデルでうまく機能する。つまりローカル通信とリモート通信の不一致を減らす。
まとめ
さまざまなデータエンコーディング形式と互換性の性質:
- プログラミング言語に特化したエンコーディングは単一のプログラミング言語に制限され、前方互換性と後方互換性を提供できない場合がある。
- JSON、XML、CSVのようなテキスト形式は広く使われている。
- これらの互換性はデータ型の使い方に依存するため、スキーマがあれば有用な場合もあるが、逆に不便な場合もある。
- Thrift、Protocol Buffers、Avroのようなバイナリスキーマベースの形式は、短い長さでエンコードされるため効率的である。
- ただし、バイナリエンコーディングを人が読めるようにするにはデコード過程が必要である。
データエンコーディングに関するシナリオ、data flow mode:
- データベースに記録するプロセスがエンコードし、データベースから読むプロセスがデコードするデータベース。
- クライアントがリクエストをエンコードし、サーバーがリクエストをデコードしてレスポンスをエンコードし、最終的にレスポンスをデコードするRPCとREST API。
- 送信者がエンコードし、受信者がデコードするメッセージを互いに送信してノード間通信を行う非同期メッセージ送信。メッセージブローカーやアクターを利用する。