データ指向アプリケーションデザイン | 第06章 パーティショニング
発表者: パク・ヒョンド、イ・スンイク
パーティショニング
データセットが非常に大きい場合、またはクエリ処理量が非常に高い場合、レプリケーションだけでは不十分で、データをパーティションに分割する必要がある。この作業をパーティショニング、またはシャーディングと呼ぶ。
パーティションを分けるときは、通常、各データ単位(レコード、行、ドキュメント)が一つのパーティションに属するようにする。データベースが複数のパーティションを同時に扱う操作をサポートする場合もあるが、結果的に各パーティションはそれ自体が小さなデータベースになる。
つまり、テーブルは論理的には一つのテーブルだが、物理的には複数のテーブルに分離して管理できるようにする機能である。
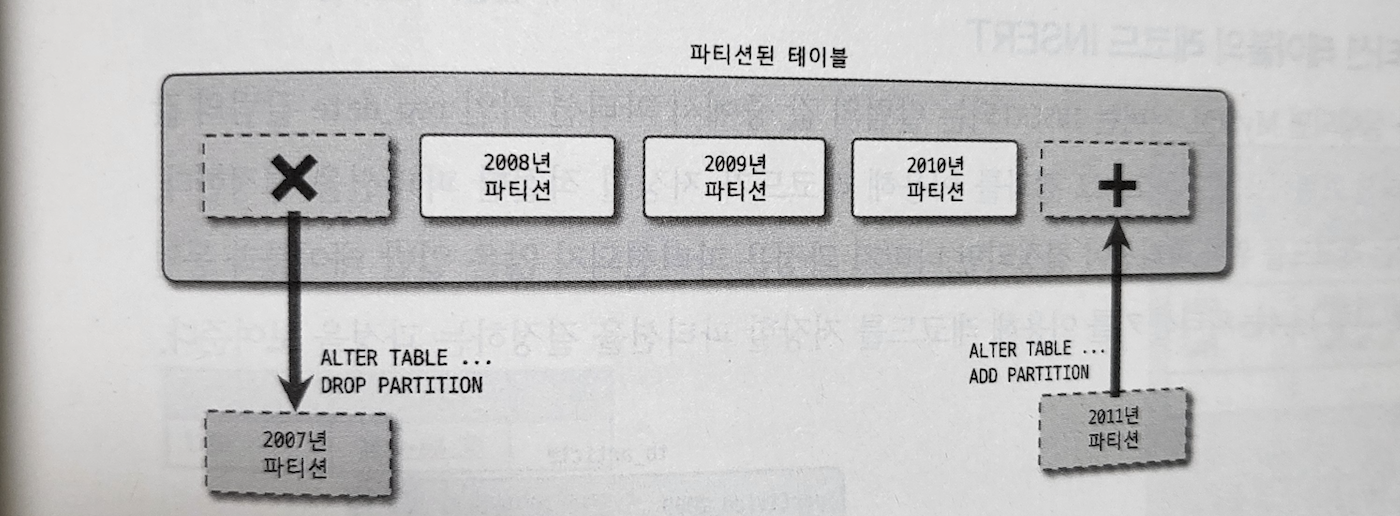
出典: Real MySQL 8.0
パーティショニングを行う主な理由
- スケーラビリティ
- シェアードナッシングクラスタでは、異なるパーティションを異なるノードに保存できる。そのため、大容量データセットを複数のディスクに分散でき、クエリ負荷を複数のプロセッサに分散できる。
- 単一パーティションで実行されるクエリを考えると、各ノードは自分のパーティションに該当するクエリを独立して実行できるため、ノードを追加することでクエリ処理量を増やせる。大きく複雑なクエリははるかに難しいが、複数ノードで並列実行できる。
- 履歴データの効率的な管理
- 不要なデータ削除作業は、単にパーティションを追加または削除する方式で簡単かつ高速に解決できる。
- 例: ログデータは短期間に大量に蓄積され、一定期間が過ぎると不要になるデータであり、削除やバックアップ時に高負荷な作業になる。
パーティショニングとレプリケーション
通常、レプリケーションとパーティショニングを組み合わせて、各パーティションのコピーを複数ノードに保存する。各レコードは正確に一つのパーティションに属していても、それを複数の別ノードに保存することで耐障害性を保証できるという意味である。
一つのノードに複数のパーティションを保存することもできる。リーダー・フォロワーレプリケーションモデルを使用する場合、パーティショニングとレプリケーションの組み合わせは次のような形になる。
各パーティションのリーダーは一つのノードに割り当てられ、フォロワーは別のノードに割り当てられる。
各ノードは、あるパーティションではリーダーであり、別のパーティションではフォロワーになることができる。
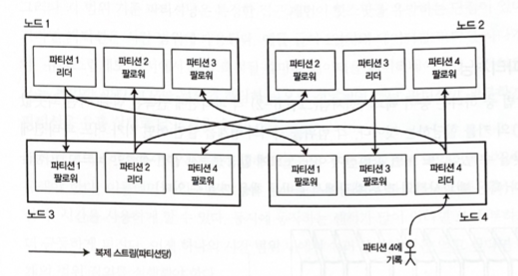
キー・バリューデータのパーティショニング
- skewed(偏り): パーティショニングが均等に行われず、他のパーティションより多くのデータを持つ、または多くのクエリを受けるパーティションがある場合。
- hotspot(ホットスポット): 不均衡に負荷が高いパーティションを指す用語。
キー範囲によるパーティショニング
各パーティションに連続したキー範囲を割り当てる方式である。これにより、各範囲の境界を把握でき、どのキーがどのパーティションに属するかを簡単に見つけられる。また、どのパーティションがどのノードに割り当てられているか分かれば、適切なノードへ直接リクエストを送れる。
例: ある最小値から最大値まで。
CREATE TABLE employees (
id INT NOT NULL,
first_name VARCHAR(30),
last_name VARCHAR(30),
reg_date DATE NOT NULL DEFAULT '1970-01-01',
....
) PARTITION BY RANGE( YEAR(hired) ) (
PARTITION p0 VALUES LESS THAN (2000),
PARTITION p1 VALUES LESS THAN (2010),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
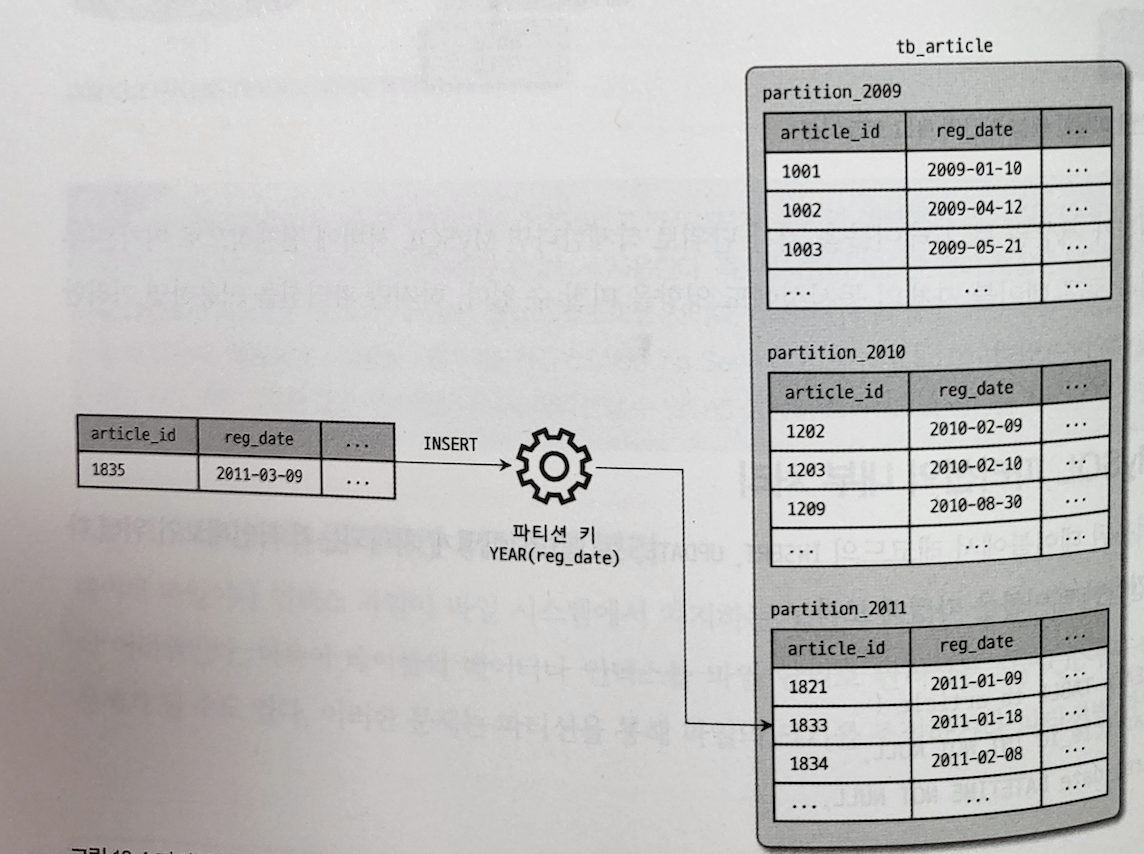
出典: Real MySQL 8.0
利点
- 各パーティション内ではキーをソート順に保存できる。これにより範囲スキャンが容易になり、キーを連結インデックスとみなして、一つのクエリで関連レコードを複数読み取るために利用できる。
- 例: アプリケーションで
reg_dateカラムのdate typeをキーとして使う場合、範囲スキャンは有用である。範囲スキャンを使えば、特定年のすべてのデータを簡単に読める。
欠点
- 特定のアクセスパターンがホットスポットを引き起こす。
reg_dateがキーなら、パーティションは年の範囲に対応する。たとえば1年分のデータを一つのパーティションが担当する形である。- データを更新するたびにデータベースへ記録するため、書き込み操作がすべて同じパーティション、つまり該当するyearへ送られ、そのパーティションだけが過負荷になり、他のパーティションはアイドル状態のままになる可能性がある。
キーのハッシュ値によるパーティショニング
ハッシュパーティションは、特定のハッシュ関数によってレコードを保存するパーティションを決定する方法である。
パーティショニング用のハッシュ関数は暗号学的に強力である必要はない。たとえばCassandraとMongoDBはMD5を使い、VoldemortはFowler-Noll-Vo関数を使用する。MySQLは式の結果値をパーティション数で割った余りで、保存先パーティションを決定する。
例: 文字列を入力として受け取る32ビットハッシュ関数があるとする。この関数に文字列を入れると、見かけ上は0から2の32乗-1までのランダムな数値を返す。入力文字列がほぼ同じでも、ハッシュ値は数値範囲内で均等に分散される。
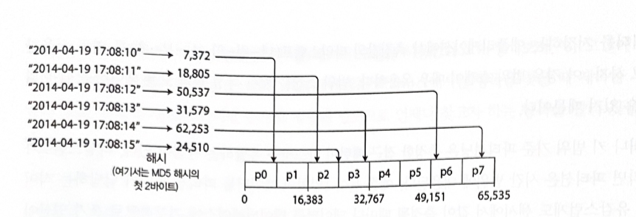
図6-3. キーのハッシュ値によるパーティショニング
利点
- 偏りとホットスポットの危険を減らし、偏ったデータを入力として受け取って均等に分散させる。
欠点
- 範囲クエリを効率的に実行できるキー範囲パーティショニングのよい性質を失う。
- 以前は隣接していたキーが、すべてのパーティションに散らばるため、ソート順が維持されない。
- MongoDBではハッシュベースのシャーディングモードを有効化すると、範囲クエリをすべてのパーティションへ送信する必要がある。Riak、Couchbase、Voldemortでは主キーに対する範囲クエリがサポートされない。
Θ Cassandra
Cassandraは二つのパーティショニング戦略の間で妥協する。Cassandraでテーブルを宣言するとき、複数カラムを含む複合主キーを指定できる。
キーの最初の部分だけにハッシュを適用してパーティション決定に使い、残りのカラムはCassandraのSSTableでデータをソートする連結インデックスとして使う。
つまり、複合キーの最初のカラムについては値範囲で検索するクエリを使えないが、最初のカラムに固定値を指定すれば、キーの他のカラムについては範囲スキャンを効率的に実行できる。
例: ソーシャルメディアサイトで、一人のユーザーが編集した複数の文書を投稿する場合がある。
特定のユーザーが特定の時間区間で編集したすべての文書を、タイムスタンプ順にソートして読み取れる。別のユーザーが編集した情報は別パーティションに保存される場合もあるが、一人のユーザーが編集した情報は一つのパーティション内でタイムスタンプ順に保存される。
主キー: (user_id, update_timestamp)
偏ったワークロードとホットスポットの緩和
前述のように、キーをハッシュしてパーティションを決めるとホットスポットの削減に役立つ。しかし、ホットスポットを完全に取り除くことはできない。常に同じキーを読み書きする極端な状況では、すべてのリクエストが同じパーティションに集中する。
例: ソーシャルメディアサイトで、数百万人のフォロワーを持つ有名人が何かをすると、大きな反応が発生する。その有名人が行った操作により、同じキーへ膨大な量のデータを書き込む必要があるかもしれない。
キーはおそらく有名人のユーザーID、または人々がコメントするアクションのIDである。同じIDのハッシュ値は同じなので、ハッシュは役に立たない。
本で提案されている解決策:
- 各キーの先頭または末尾にランダムな数値を付ける。ランダムな10進数を2桁付けるだけでも、一つのキーへの書き込み作業が100個の別キーに均等に分散され、それらのキーは別パーティションへ分散され得る。
- しかし、別キーに分割して書くと、読み取り時に追加作業が必要になる。100個のキーに該当するデータを読んで組み合わせる必要があるためである。追加で保存すべき情報もある。
- この技法はリクエストが集中する少数のキーだけに適用するのが妥当である。書き込み処理量が低い大多数のキーにも適用すると不要なオーバーヘッドが生じる。そのため、どのキーが分割されたか追跡する方法も必要である。
パーティショニングとセカンダリインデックス
基本的にレコードへ主キーでのみアクセスするなら、キーからパーティションを決定し、それを使って該当キーを担当するパーティションへ読み書きリクエストを送れる。
しかし、特定の値が発生した項目を検索する手段であるセカンダリインデックスが関係すると複雑になる。
セカンダリインデックスはパーティションにきれいに対応しないという問題があるためである。
ドキュメント基準のセカンダリインデックスパーティショニング
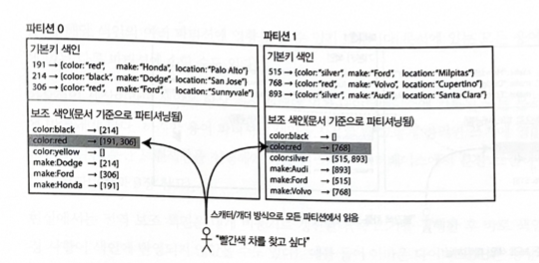
各パーティションに属するドキュメントだけを担当し、完全に独立して動作するインデックス方法をローカルインデックス(Local Index)という。
データベースにドキュメント追加、削除、更新などの書き込み作業を実行するときは、書き込もうとするドキュメントIDを含むパーティションだけを扱えばよい。他のパーティションにどのデータが保存されているかを気にしない。
例: 中古車を販売するWebサイトを運営する。各項目にはDocument IDという固有IDがあり、データベースをドキュメントID基準でパーティショニングする。Document ID 0〜499はパーティション0、Document ID 500〜999はパーティション1である。
colorとmakeにセカンダリインデックスを作成する必要がある。インデックスを宣言すると、データベースが自動でインデックスを生成できる。たとえば赤い車がデータベースに追加されると、データベースパーティションは自動的にそれをcolor:redインデックス項目のドキュメントID一覧へ追加する。
注意点
- ドキュメントIDに特別な処理をしなければ、特定の色または特定メーカーの車が同じパーティションに保存される保証はない。
- 上の画像を見ると、赤い車はパーティション0にもパーティション1にもある。
- したがって赤い車を探したい場合、すべてのパーティションにクエリを送り、得られた結果をすべて集めなければならない。
パーティション化されたデータベースにこのようにクエリを送る方法は、scatter/gatherとも呼ばれる。セカンダリインデックスを使って読み取るクエリは大きなコストがかかる。
複数パーティションでクエリを並列実行しても、scatter/gatherはテールレイテンシ増幅が発生しやすい。それでもセカンダリインデックスをドキュメント基準でパーティショニングする場合は多い。
例: MongoDB、Riak、Cassandra、Elasticsearch、SolrCloud、VoltDB。
MySQLの場合、パーティションテーブルのインデックスはすべてローカルインデックスに該当する。パーティションに関係なく、テーブル全体単位でグローバルに一つの統合インデックスをサポートしない。
そのため、WHERE条件に一致するレコードをソート順に読みながら、優先順位キュー(Priority Queue)に一時保存する。そして優先順位キューから再び必要な順序でデータを取り出す。
結果として、パーティションテーブルでインデックススキャンによりレコードを読むとき、MySQLサーバーは別途ソート作業を行わない。通常テーブルのインデックススキャンのように結果を直接返すのではなく、内部的にキュー処理が一度必要になる。
用語基準のセカンダリインデックスパーティショニング
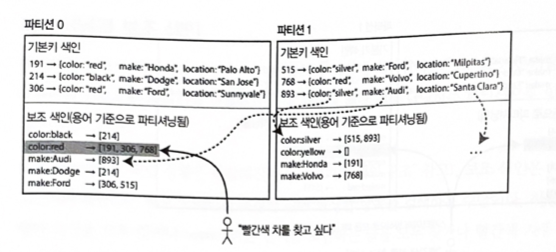
ローカルインデックスとは異なり、すべてのパーティションのデータを担当するインデックスをグローバルインデックス(Global Index)という。
この方法で一つのノードだけにインデックスを保存すると、そのノードがボトルネックになり、パーティショニングの目的を損なうため、複数ノードに分けて保存する。
検索したい用語によってインデックスのパーティションが決まるため、このようなインデックスは用語基準でパーティショニングされた(term-partitioned)という。ここではcolor:redが用語の例である。
例: すべてのパーティションにある赤い車の情報は、インデックスのcolor:red項目に保存されるが、色インデックスはaからrまでの文字で始まる色をパーティション0に、sからzまでの文字で始まる色をパーティション1に保存するようにパーティショニングされる。
自動車メーカーインデックスも同じようにパーティショニングされる。
特徴
- 前と同様、インデックスをパーティショニングするとき、用語そのものを使うことも、用語のハッシュ値を使うこともできる。用語そのものでパーティショニングすると範囲スキャン、たとえば車の販売希望価格のような数値属性に有用であり、用語のハッシュ値を使うと負荷がより均等に分散される。
利点
- ドキュメントパーティショニングインデックスに比べ、グローバル(用語パーティショニング)インデックスの利点は読み取りが効率的なことである。
- クライアントはすべてのパーティションにscatter/gatherを実行する必要がなく、目的の用語を含むパーティションにだけリクエストを送ればよい。
欠点
- 単一ドキュメントを書き込むとき、そのインデックスの複数パーティションに影響する可能性があり、書き込みは遅く複雑になる。
- ドキュメント内のすべての用語が、別ノード上の別パーティションに属する場合もある。
理想的には、インデックスは常に最新状態であり、データベースに記録されたすべてのドキュメントはすぐにインデックスへ反映されるべきである。
しかし、用語パーティショニングインデックスでそうするには、書き込みの影響を受けるすべてのパーティションにまたがる分散トランザクションを実行しなければならず、すべてのデータベースが分散トランザクションをサポートしているわけではない。
現実には、グローバルセカンダリインデックスはたいてい非同期で更新される。つまり、書き込みを実行した直後にインデックスを読むと、変更内容がまだインデックスに反映されていない場合がある。
例: Amazon DynamoDBは通常の状況ではグローバルセカンダリインデックスを1秒未満で更新するが、インフラに障害が発生すると反映遅延が長くなる可能性がある。
グローバル用語パーティショニングインデックスの他の使用例として、Riakの検索機能とOracle Data Warehouseがある。Oracle Data Warehouseではローカルインデックスとグローバルインデックスの間で選択できる。
Q. Local IndexとGlobal Indexのどちらが使いやすいか。
A. もちろんサービス構造など多くの点を考慮する必要があるが、一般的にはパーティションの特性上、特定パーティションに該当する作業(追加、削除)を多く行うため、その作業対象パーティションのインデックスだけに影響するローカルインデックスがよく使われる。グローバルインデックスの場合、パーティションに該当する作業をするとき全体的な再調整が必要になるため負荷が大きい。
パーティション再均衡化
概要 データベースの物理機器に変化が発生する。
- CPU、RAM、DISKの追加
- 新しいノードの追加

再均衡化(rebalancing)
- クラスタで一つのノードが担当していた負荷を別ノードへ移す過程。
再均衡化の要件
- 負荷の均等化
- 瞬断なし
- データ移動の最小化
再均衡化戦略
ハッシュ値にmod N(ノード数)演算


mod N方式の問題点
- ノード数Nが変わると、ほとんどのキーをノード間で移動しなければならないため、再均衡化コストが上がる。
静的パーティショニング(パーティション数固定)
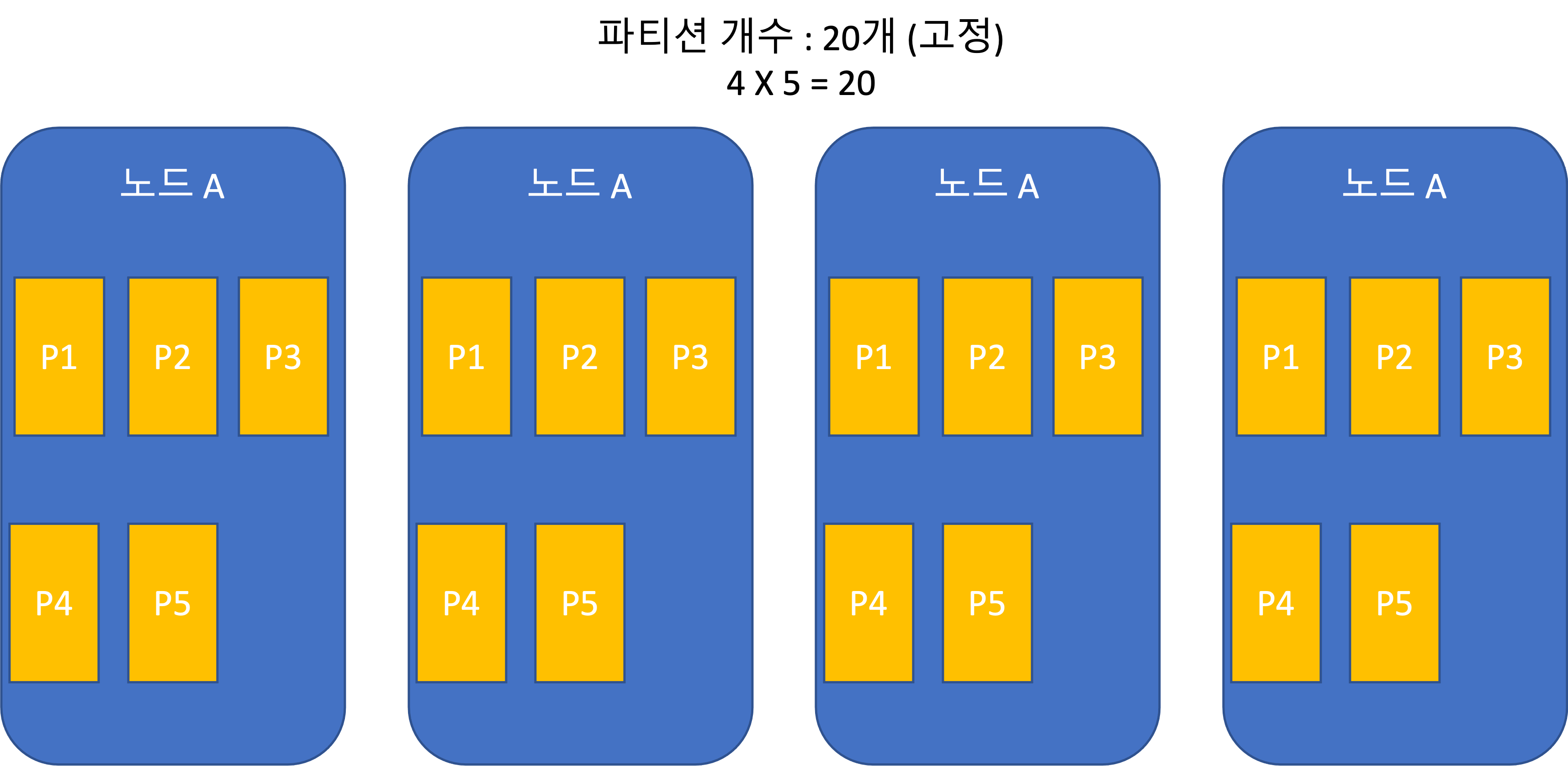
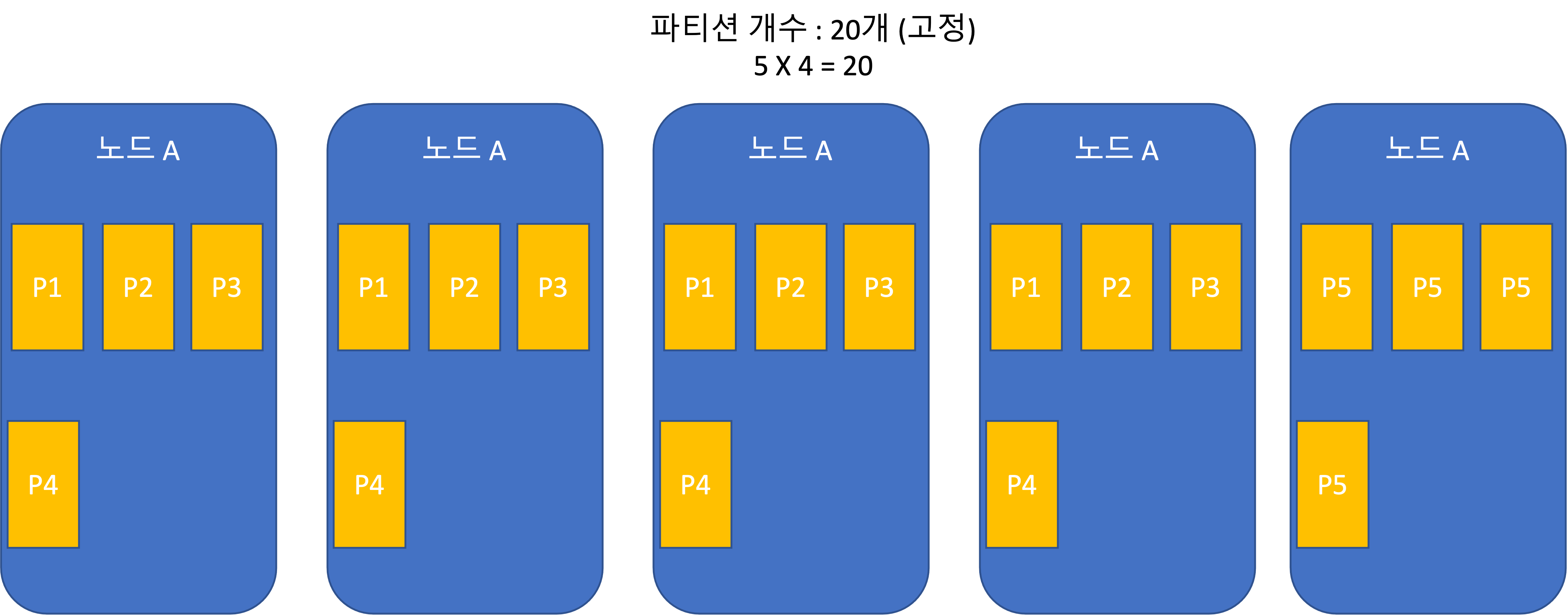
- Riak、Elasticsearch、Couchbase、Voldemortで使用される。
- 全体データセットのサイズ変動が大きい場合、適切なパーティション数を決めるのは難しい。
- パーティションが大きくなりすぎると、再均衡化および障害復旧コストが大きい。
- 適切なサイズを決めるのが最善だが、難しい。
動的パーティショニング リスティング開発チーム > 06. パーティショニング > 動的パーティショニング1.png
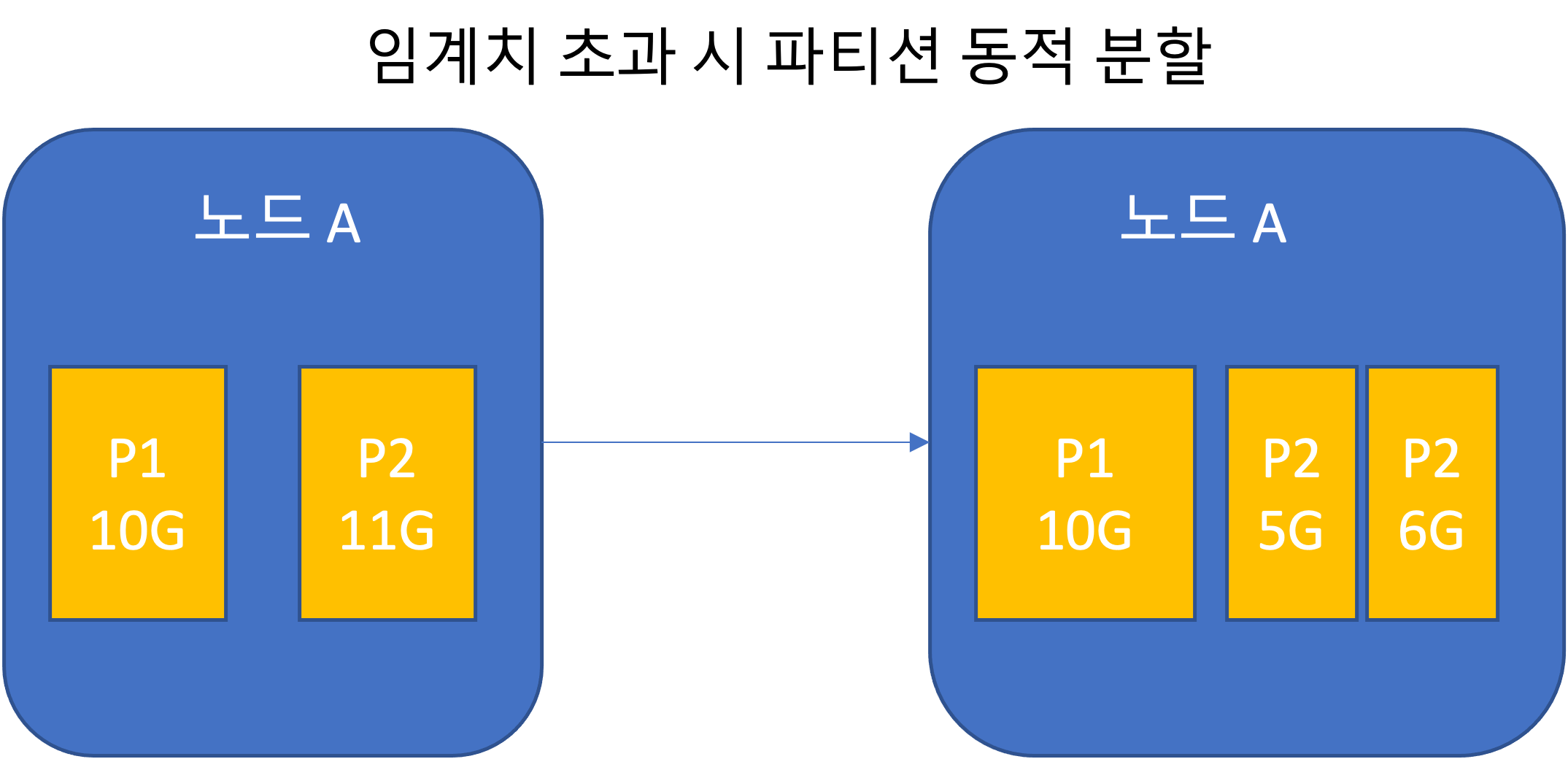
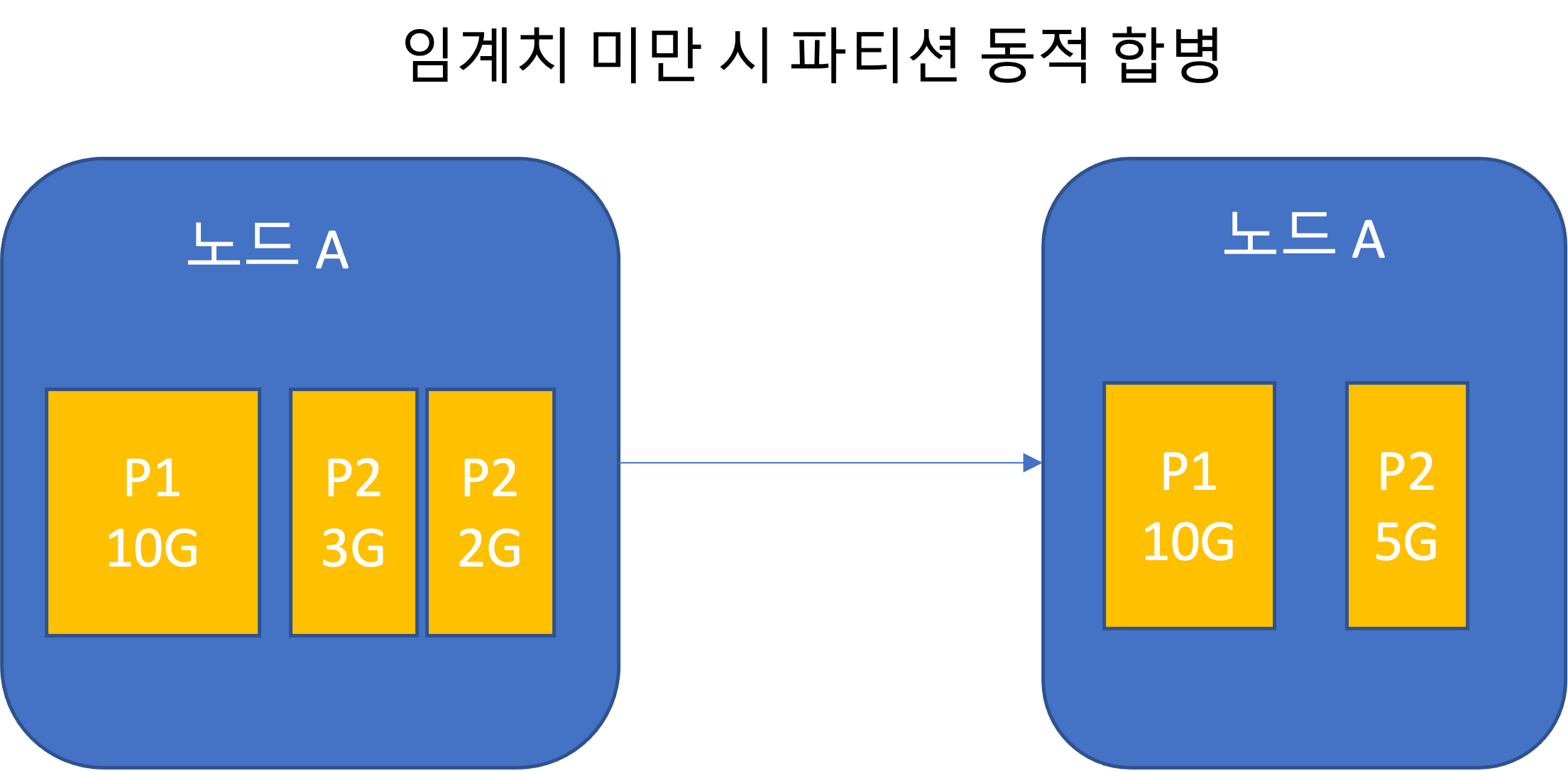
- パーティション数が全体データ容量に合わせて調整される。サイズを制限し、数を増やす。
- 空のデータベースの場合、パーティション境界の設定値に達するまではパーティションが1個である。
- HBaseとMongoDBは空のデータベースに初期パーティション集合を設定できる。これは事前分割(pre-splitting)である。
静的パーティショニングと動的パーティショニングの特徴まとめ
- 静的パーティショニング: パーティションサイズがデータサイズに比例する。
- 動的パーティショニング: パーティション数がデータサイズに比例する。
- どちらもノードとは関係がない。
ノード比例パーティショニング
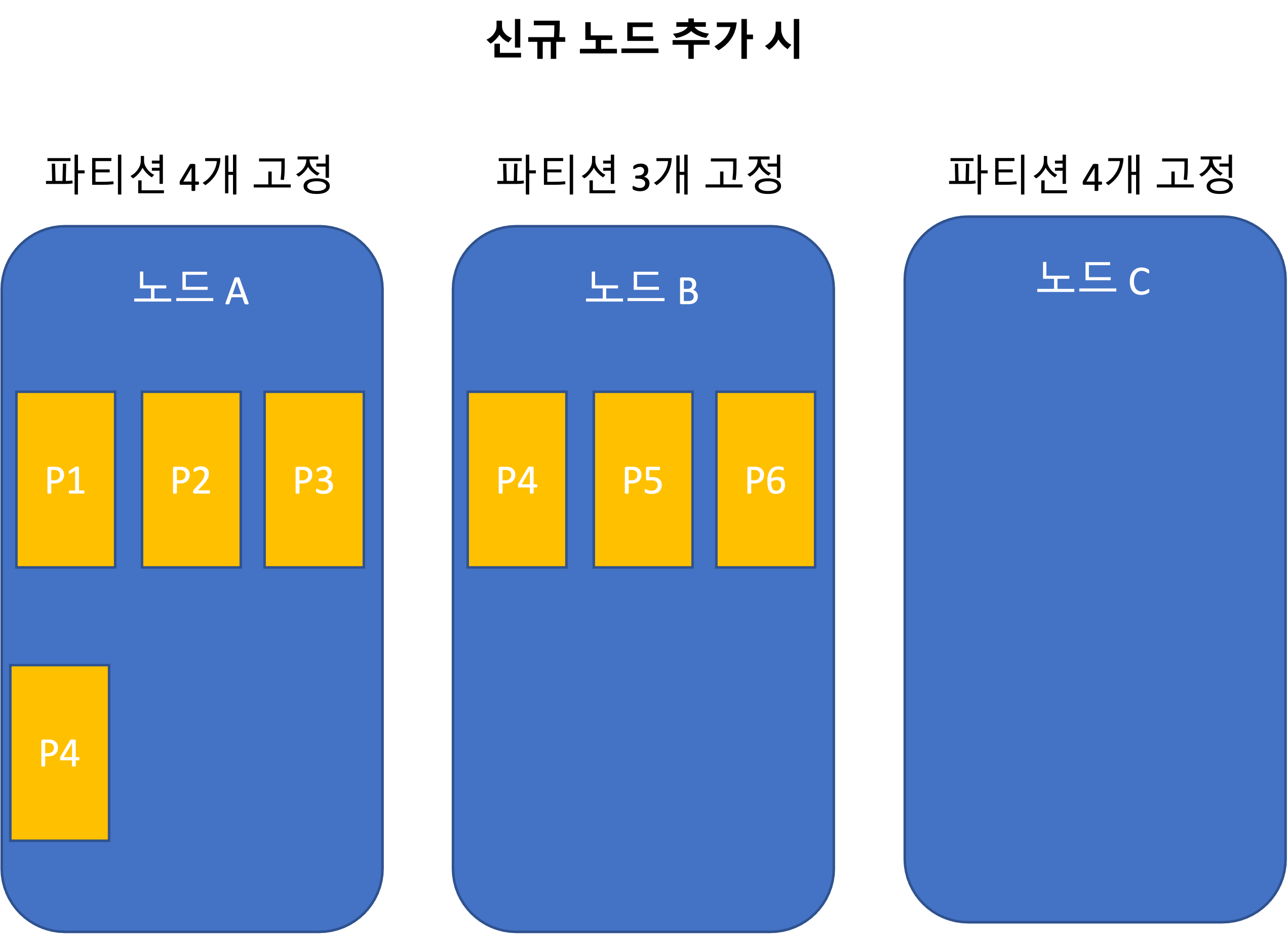
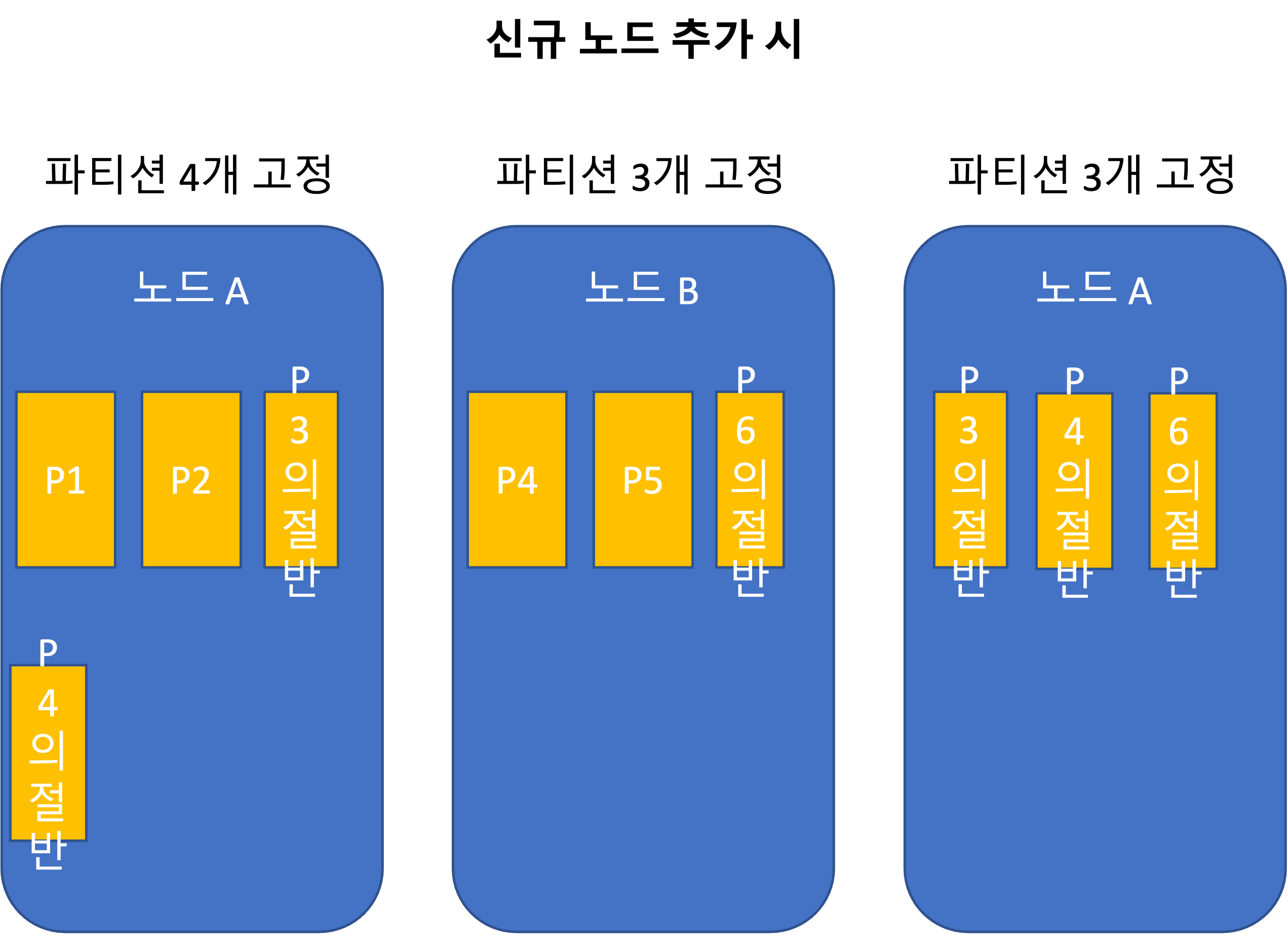
運用: 自動再均衡化と手動再均衡化
完全自動再均衡化
- 管理者の介入なしに、システムが自動で再均衡化する。
完全手動再均衡化
- 管理者が明示的にパーティションをノードに割り当て、管理者が再設定したときだけパーティション割り当てが変更される。
リクエストルーティング
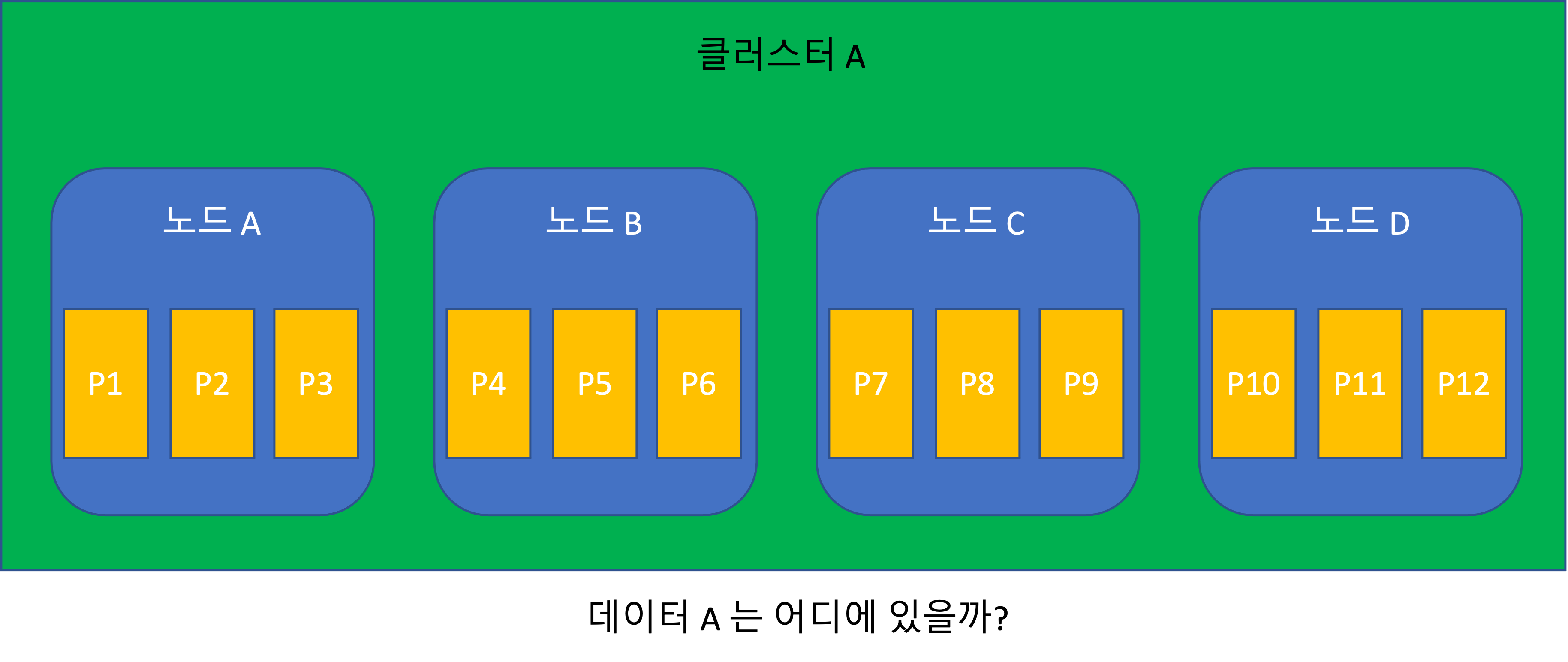
- パーティションが再均衡化されると、ノードに割り当てられるパーティションが変わる。つまりデータの位置が変わる。
- パーティション割り当て情報をリアルタイムに把握している必要が生じる。
Service discovery
- データベースに限られない一般的な問題。
- 高可用性を目指すソフトウェアならすべて持っている問題。
- 高可用性とは、事実上、分散ネットワークシステムである。
- https://mangchhe.github.io/springcloud/2021/04/07/ServiceDiscoveryConcept
ルーティング判断を行うコンポーネントの位置によるアプローチ ルーティング判断を行うコンポーネントとは、位置情報のことである。
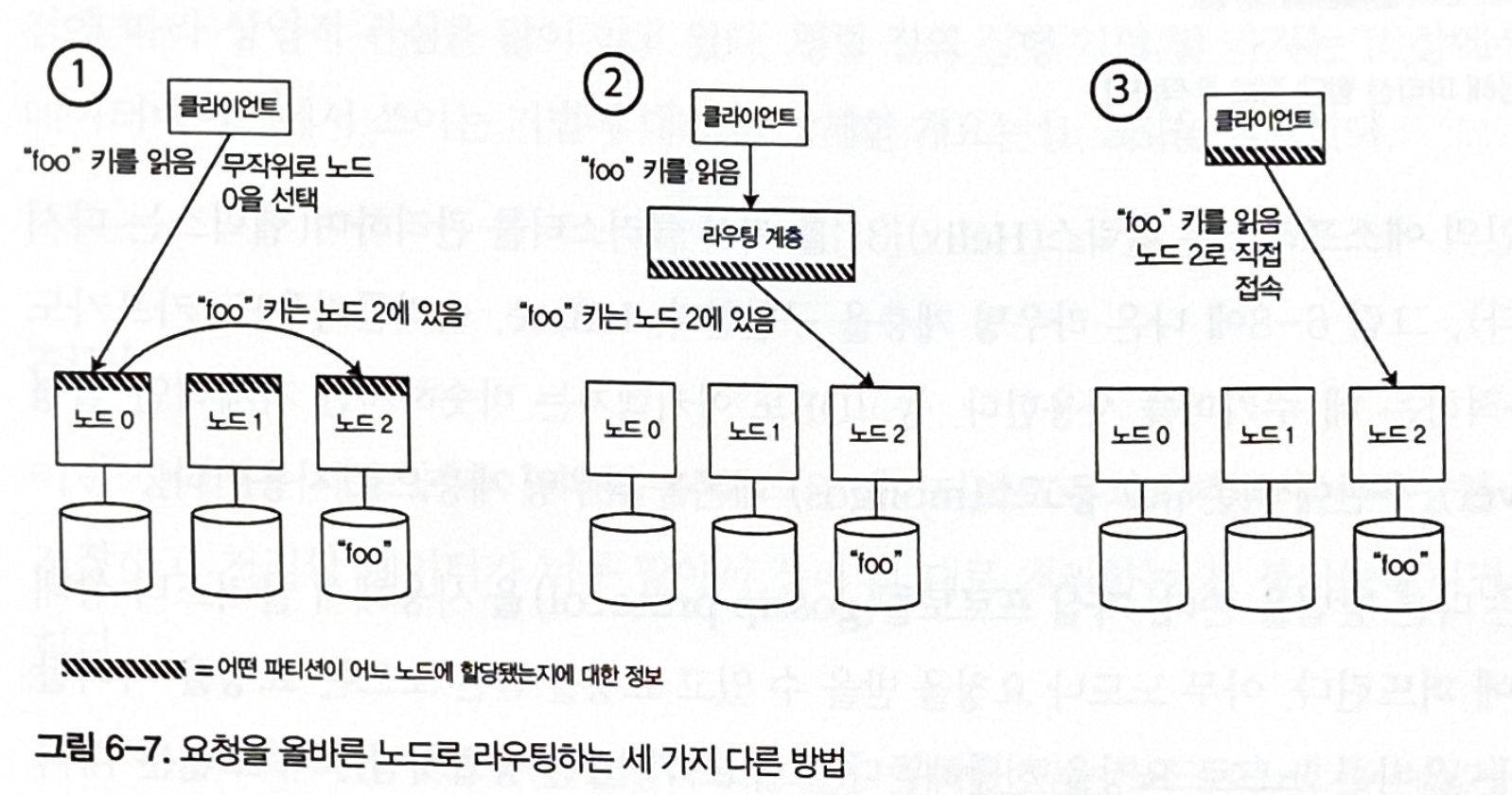
図6-7. リクエストを正しいノードへルーティングする三つの方法
重要情報を管理する方法
すべての場合で重要な問題は、ルーティング判断を行うコンポーネントが、ノードに割り当てられたパーティションの変更をどのように知るかである。
多くのコーディネーションサービスが存在する: https://stackshare.io/service-discovery
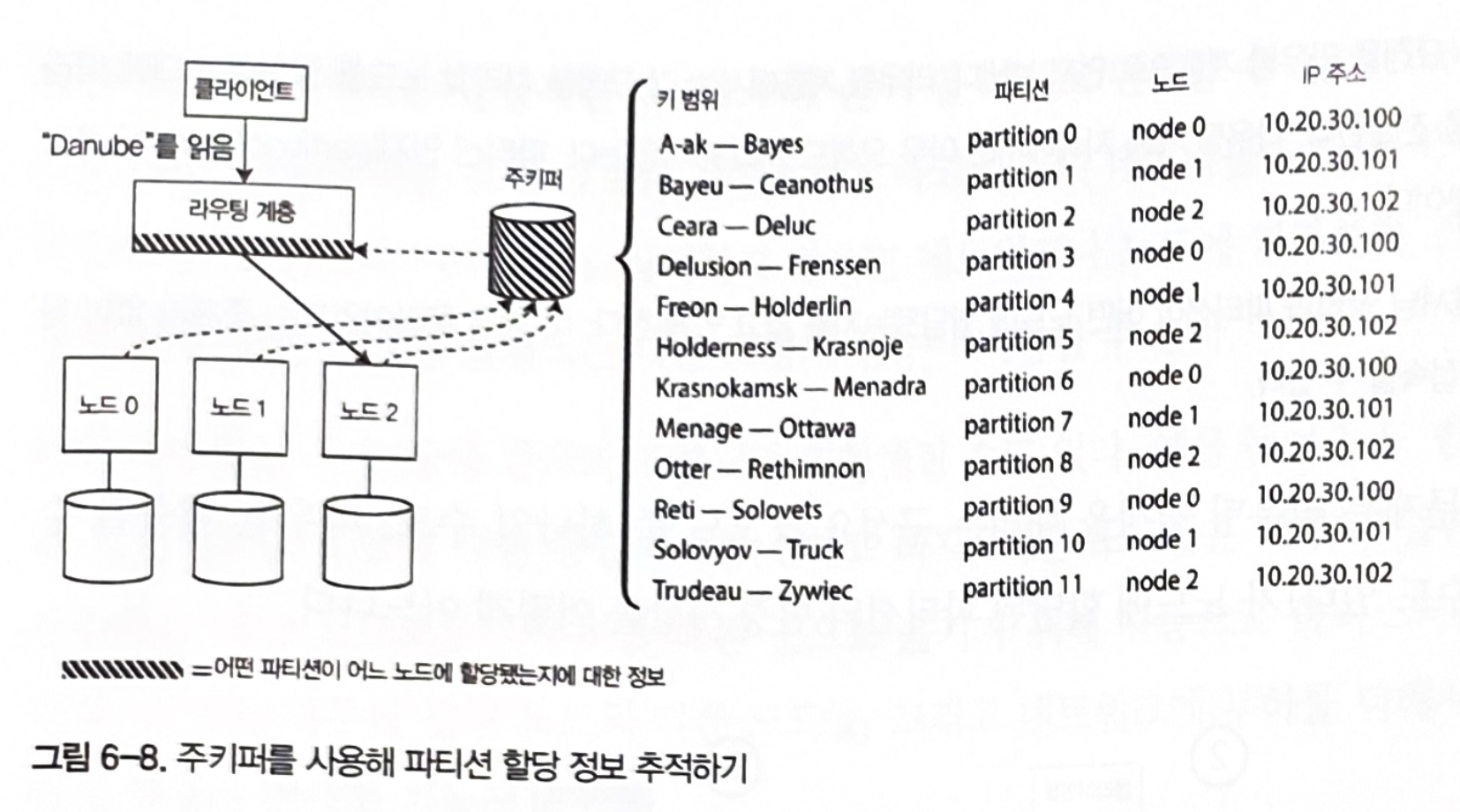
図6-8. ZooKeeperを使ってパーティション割り当て情報を追跡する
データベース別のパーティション割り当て情報へのアプローチ
方法1. 個別ノードがパーティション割り当て情報を持つ。
- Cassandra、Riak
- データベースノードに複雑性を加えるが、外部コーディネーションサービスに依存しない点は利点である。
方法2. ルーティング層がパーティション割り当て情報を持つ。
- HBase、SolrCloud、Kafka、MongoDB
- コーディネーションライブラリ、または独自の設定サーバーを使用する(MongoDB)。
方法3. クライアントがパーティション割り当て情報を持つ。
- 情報提供をお願いします。
並列クエリ実行
- データの大規模化により、大規模データ分析とクエリが重要になる。これによりクラスタ型データベースが使われる。
- 大規模並列処理(massively parallel processing, MPP)をサポートする。
- RDBは結合、フィルタリング、グループ化、集計演算など、複雑な種類のクエリをサポートする。
- MPPクエリはクラスタ内の異なるノードで並列に実行される。