Apache Kafkaの概念紹介
Kafkaとは?
Kafkaは分散メッセージングシステムと呼ばれ、メッセージ(データ)の送信者と受信者を仲介するシステムである。大容量、大規模なメッセージデータを高速に処理するために開発されたメッセージプラットフォームであり、Pub-Subモデルのメッセージキューでもある。また、分散環境に特化した特徴を持っている。
「ビッグデータ」や「IoT」がトレンドになる中で、LinkedInではサービス拡張によって複数のメッセージキューシステムを管理することが難しくなり、社内プロジェクトとしてKafkaの開発が始まった。2011年初めにはApacheの公式オープンソースとして公開された。現在はオープンソースソフトウェアとして開発されており、Confluent、LinkedIn、Uber、中国のAlibabaなど、多くの企業やコミュニティで利用されている。
メッセージングシステムとは?
メッセージングシステムとは広い意味を持つ言葉であり、「送信者からデータをいったん受信し、適切なタイミングで受信者へデータを送るシステム」を指す。
たとえば、Webサイトのログを収集する場合、複数のWebサーバーからログを中継サーバーへ送り、中継サーバーがバッチ処理でデータベースなどへログを送る構成を考えられる。これもメッセージングシステムといえる。これだけでは不十分なので、Pub-Subメッセージングモデルを例に図で説明する。
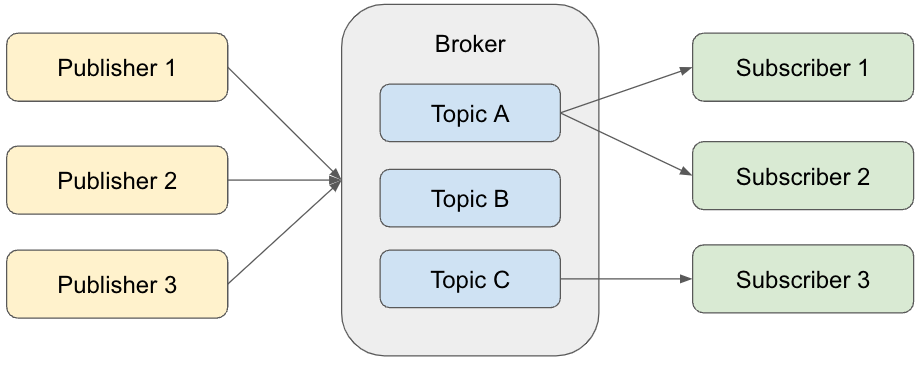
Pub-Subメッセージングモデルでは、Publisher(送信者)がBrokerへメッセージを送り、Subscriber(受信者)はBrokerからメッセージを受け取る。PublisherがSubscriberへ直接メッセージを送るのではなく、常にBrokerを介する。Publisherが送ったメッセージはBrokerのTopicに保存される。Topicは複数存在し、メッセージの内容に応じて、どのTopicに保存するかをPublisherが指定する。一方、各Subscriberは特定のTopicからだけ選択的にメッセージを受け取る。この構成になる理由は日常生活を考えると理解しやすい。世の中のサービスや製品は、ある程度ターゲットが決まっていても基本的には誰でも利用できる形で作られるが、利用者は当然すべてを利用するわけではなく、自分の興味や関心に応じて選択する。Pub-Subメッセージングモデルもこれと同じである。
なぜBrokerが仲介するのか?
PublisherからSubscriberへデータを送ることが目的なら、一見Brokerは不要に思える。しかしBrokerの存在は次の2つの観点で非常に重要である。
1. Publisher/SubscriberはBrokerとだけ通信すればよい
もしBrokerがなければ、PublisherはそれぞれのSubscriberをすべて把握していなければならない。逆にSubscriberは、データを送るそれぞれのPublisherをすべて把握する必要がある。Brokerがあることで、PublisherはSubscriberを意識せず、とにかくBrokerへメッセージを送ればよい。
2. メッセージングモデルを変更しやすい
Brokerだけと通信する構成にすると、Publisher/Subscriberの追加や削除が容易になる。Brokerがなければ、追加や削除のたびにすべてのPublisher/Subscriberを考慮しなければならず、作業が難しくなる。
Publish/Subscribeとは?
メッセージングシステムによってPublish/Subscribeの用語は少しずつ異なるが、概ね同じ意味として次のように整理できる。
- メッセージの生成(送信)
- Publisher
- Producer:Kafkaではこの用語を使う
- Writer
- メッセージの消費(受信)
- Subscriber
- Consumer:Kafkaではこの用語を使う
- Reader
メッセージキューイングシステムとは何が違うのか?
Publish/Subscribeメッセージングシステムでは、メッセージを複数回消費できる(Producerはメッセージを1回送信すればよい)。それに対して、メッセージキューイングシステムではメッセージの消費は1回だけ可能であり、Producerはメッセージを消費する回数分だけ送信する必要がある。これが大きな違いである。
Kafkaの特徴
Kafkaの特徴について見ていく。
1. 大量のデータを高速に処理できる
前述のとおり、Kafkaは「ビッグデータ」や「IoT」といったトレンドを背景に開発された。この背景を考えると、大量のデータを高速に処理できることは非常に重要である。詳細は後述するが、KafkaはPub-Subメッセージングモデルとは少し異なる構成を持ち、複数Broker構成になっているためスケールアウトしやすい。スケールアウトの容易さは処理速度の向上に直結する。
2. 任意のタイミングでデータを利用できる
前述した「高速」とはリアルタイム処理を指すが、必ずしもリアルタイム処理だけではない。Kafkaに接続されるConsumer(Pub-SubメッセージングモデルのSubscriberに相当)は多様であり、バッチ処理を行う場合もある。また、データもすぐに使うとは限らず、Broker内で長期間保存する必要がある場合がある。Kafkaではデータをメモリ上だけでなくディスクにも書き込むことで永続的な保存を可能にしている。これにより、データを自由なタイミングで利用できる。
3. 高速性を維持しながらデータ送信を保証できる
データの配信保証というと、1件ずつデータに対してトランザクション処理を行えば簡単だと思うかもしれない。しかし、それを実行しながら高速にデータを処理するのは非常に難しい。当然、途中でデータが失われることも避けなければならない。最も厳格な配信保証は「1件のデータを確実に1回だけ送る」(Exactly once)だが、Kafkaでは「重複してもよいので、少なくとも1回は確実にデータを送信する」(At least once)を実現することで、高速性と配信保証のバランスを取っている。
4. データ送受信用のAPIが充実している
Kafkaに接続されるProducer/Consumer(ProducerはPub-SubメッセージングモデルのPublisherに相当)は1つだけではなく、別のシステムに属している場合も多い。このような場合、Publisher/SubscriberとKafkaの間の接続用APIが重要になる。接続APIの役割を果たすものとしてKafka Connectと、Kafka Connectに接続するConnectorプラグインが提供されている。APIを利用者側で開発するのは非常に手間がかかるため、豊富なAPIを提供することは開発効率の向上に役立つ。
その他にも次の特徴がある。
- ProducerとConsumerの分離
- Kafkaはメッセージ転送方式のうち、メッセージを送る役割と受け取る役割が完全に分離されたPub-Sub方式を採用している。
- それぞれの役割が完全に分離されるため、片方のシステムで問題が発生しても連鎖的な影響が発生する可能性は非常に低い。
- マルチProducer、マルチConsumer
- Kafkaは1つのTopicに複数のProducerまたはConsumerがアクセスできる構造になっている。
- データ分析や処理プロセスで1つのデータを多様な用途に使いたい要求が増えており、このマルチ機能によりその要求を容易に満たせる。
- ディスクへのメッセージ保存
- メッセージをディスクに保存し、保持する。
- Consumerがメッセージを読み取っても、保存期間中はディスクにメッセージが残る。
- 拡張性
- Kafkaは拡張しやすいように設計されている。1つのKafkaクラスターは3台のBrokerから開始し、多数のBrokerへ拡張できる。
- 拡張作業はKafkaサービスを停止せず、オンライン状態で実行できる。
- 高性能
- Kafkaは高性能を維持するため、内部的に分散処理、バッチ処理などさまざまな技法を使用している。
Kafkaの構成要素
ここまでKafkaの大まかな特徴を説明した。次にKafkaの具体的な構成を見ていく。Kafkaの構成は次の図で表せる。図の用語を順に説明する。
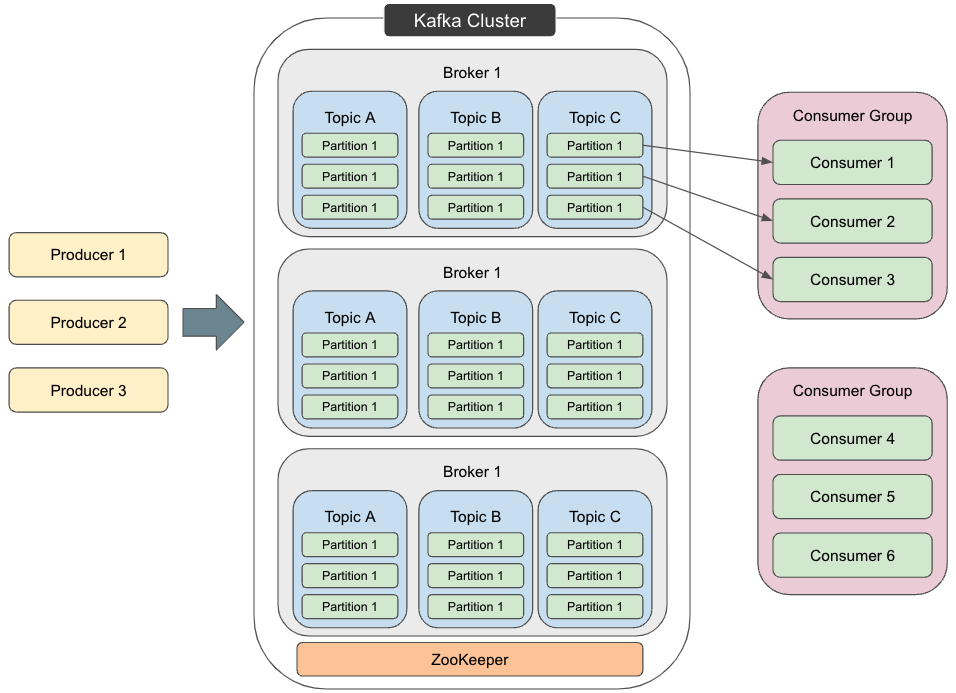
Message
構成図には登場しないが、個別のデータをMessage、またはEventと呼ぶ。Messageはkeyとvalueで構成され、KafkaでProducerとConsumerがデータをやり取りする単位である。
Producer
ProducerはKafkaへイベントを投稿するクライアントアプリケーションを意味する。Pub-SubメッセージングモデルのPublisherに相当し、BrokerへMessageを送信する。実際にKafkaと連携するには、APIを利用して通信用アプリケーションを作るか、Producer機能を持つオープンソースソフトウェアを使用する必要がある。
Consumer
ConsumerはTopicを購読し、そこから得られたイベントを処理するクライアントアプリケーションである。Pub-SubメッセージングモデルのSubscriberに相当し、BrokerからMessageを受信する。Kafkaの送信はPull形式であるため、ConsumerからBrokerへ要求を送ることでBrokerからMessageが届く。特徴でも触れたように、Kafkaではデータをディスクに書き込んで永続的に保存しているため、Consumerは任意のタイミングからリクエストを送信できる。Producerと同様に、Kafkaと連携するにはAPIを利用して通信用アプリケーションを作るか、Consumer機能を持つオープンソースソフトウェアを使用する必要がある。
Broker
BrokerはProducer/Consumerからの要求に応じてMessageの受信と転送を実行する。高速処理を可能にするため、図のように複数構成を取るのが一般的である。受け取ったメッセージをディスクに書き込む作業も行う。
Topic
TopicはBroker内のMessage保存領域を意味し、同じ分類のMessageは同じTopicに保存される。各Producerは特定のTopicへメッセージを送り、各Consumerは特定のTopicからMessageを取得して処理する。Topicはファイルシステムのフォルダに似ており、イベントはフォルダ内のファイルに似ている。Topicに保存されたMessageは必要なときに再び読むことができる。
Partition
Topicは複数のBrokerに分散して保存され、このように分割されたTopicをPartitionと呼ぶ。図のように、Topic内のMessageはPartitionという単位に分かれている。これは後で説明するConsumer Groupと関連して重要である。どのMessageがどのPartitionに保存されるかはMessageのkeyによって決まり、同じkeyを持つMessageは常に同じPartitionに保存される。KafkaはTopicのPartitionに割り当てられたConsumerが、そのPartitionのイベントを常に同じ順序で読むことを保証する。
Consumer Group
複数のConsumerが組み合わさってConsumer Groupを形成する。同じConsumer Groupに属するConsumerは同じTopicからMessageを受信する。一方、入力元のPartitionはConsumerごとに異なる。この方式によりKafkaはメッセージの分散処理を可能にする。ここが前述したPub-Subメッセージングモデルとの違いである。Pub-Subメッセージングモデルでは「各Subscriberは特定のTopicからメッセージを受信する」と説明したが、特定のTopicからメッセージを受け取るSubscriberはすべて同じメッセージを受け取る。
ZooKeeper
Topic、Partitionなど、Messageの分散処理に関する情報を保存・管理するためのツールである。図では1つだけだが、複数を利用するのが一般的である。
Kafka Cluster
ZooKeeperとBrokerで構成されるMessage中継システムをKafka Clusterと呼ぶ。
Kafkaの主要概念
- ProducerとConsumerの分離
- ProducerとConsumerは完全に別々に動作する。
- ProducerはBrokerのTopicへメッセージを投稿するだけである。
- ConsumerはBrokerの特定Topicからメッセージを取得して処理するだけである。
- ProducerとConsumerは完全に別々に動作する。
- PushとPullモデル
- 消費済みメッセージの追跡(CommitとOffset)
- Consumer Group
- メッセージ(イベント)配信の概念