ビッグデータ分析基盤とは?データパイプライン構築
ビッグデータとは
ここでは、ビッグデータを可視化、分析することを目標にする。
Excelや従来のRDBのような小規模データ向けソフトウェアでビッグデータを処理できない理由は、CPU、メモリ、ストレージといったハードウェアリソースに限界があるためである。ビッグデータを処理するには、並列処理に対応したソフトウェアと複数のコンピュータを利用する。
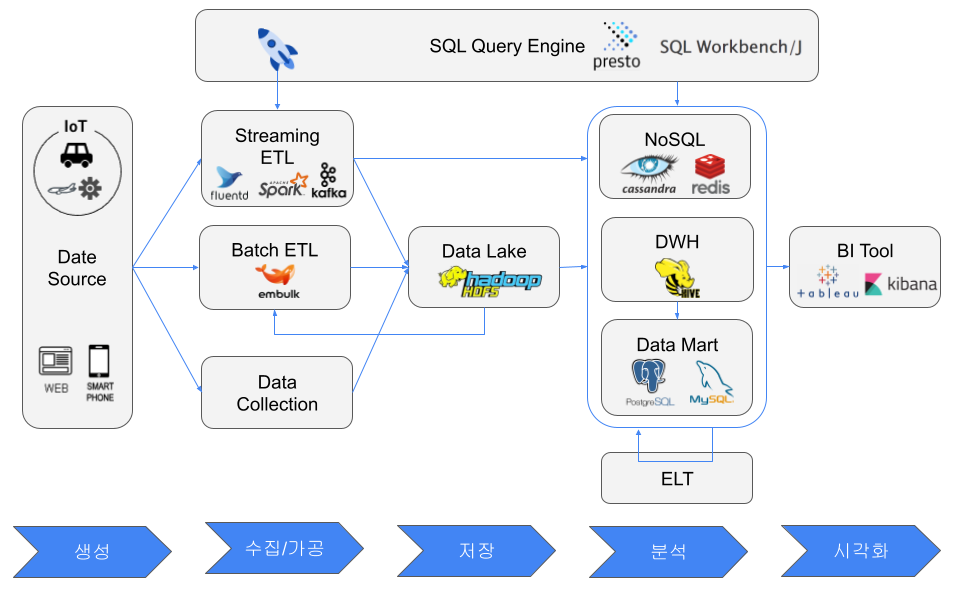
データソース
例として、Webサーバー、工場や自動車センサーなどのIoT機器、スマートフォンなどのモバイル機器がある。データソースという言葉が指す対象は立場によって変わる。BIツールから見れば、NoSQL、DWH、データマートがデータソースになることもある。
データは、構造化データ、非構造化データ、半構造化データに分けられる。
構造化データ
構造化データはRDBとSQLで扱いやすい。一方で、行と列を事前に定義する必要があり、保存前に固定スキーマへ変換しなければならず、ネストしたデータは通常JOINで扱う。
非構造化データ
例として、音楽、写真、テキストログがある。
<6>Feb 28 12:00:00 192.168.0.1 fluentd[11111]: [error] Syslog test
非構造化データはそのまま保存しやすいが、スキーマがないためRDBとSQLでは扱いにくい。
半構造化データ
例としてJSON、XML、AVRO、Parquet、ORCがある。ログ行は、各要素に名前を付けることでJSONへ変換できる。
{
"jsonPayload": {
"priority": "6",
"host": "192.168.0.1",
"ident": "fluentd",
"pid": "11111",
"message": "[error] Syslog test"
}
}
半構造化データは属性を持つため、対応するデータベースでクエリしやすく、後からスキーマを変更できる。関連データをネストして含めることもできる。
ETLとELT
データソース側で変換処理を行わない理由は、本番Webサーバーへ負荷をかけたくないこと、IoT機器に十分なリソースがないこと、モバイル機器が顧客の端末であることなどである。
ETLにはバッチETLとストリーミングETLがある。バッチETLはスループット重視で、毎時や毎晩など一定間隔で実行する。ストリーミングETLはリアルタイム性重視で、データ発生時に実行する。
抽出ツールには、バッチETL向けのEmbulk、ストリーミングETL向けのfluentd、beats、Kafka Producer APIなどがある。ExtractとTransformの間にPub/Subメッセージングシステムを置くと、処理を分散したり、急激なデータ増加を一時的にバッファしたりできる。
TransformはSQL、pandas、fluentd、logstash、Kafka Streams、Spark Streamingなどで行う。変換後のデータは、NoSQL、データレイク、データウェアハウス、データマートへLoadする。
データレイク
例としてHadoop HDFSとAmazon S3がある。データレイクにはさまざまな形式の大量データを保存するため、後から容量を追加しやすいストレージが選ばれる。
NoSQLデータベース
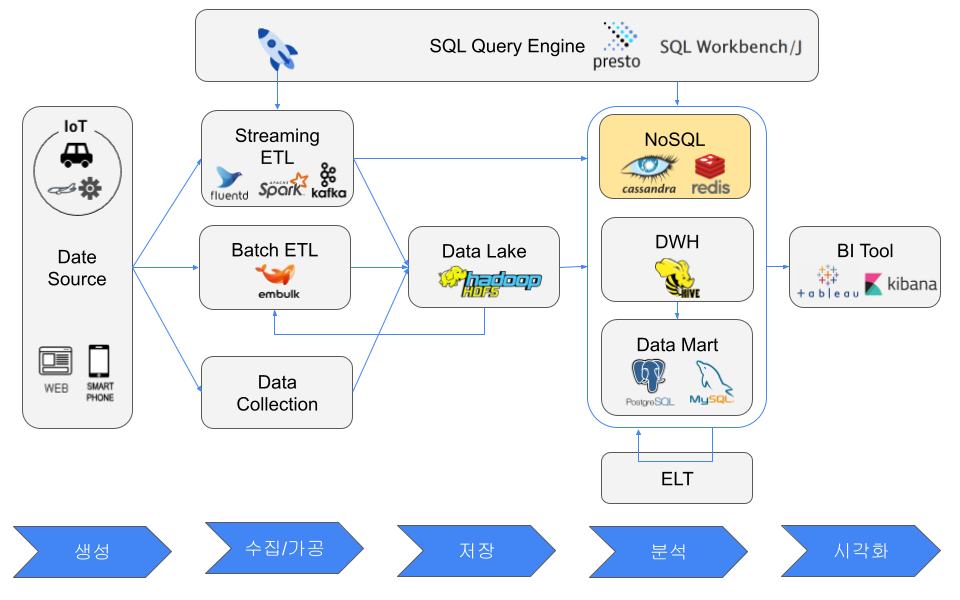
NoSQLは一般に、RDBの一部制約を緩めて性能を追求する。RDBと比べると、低レイテンシ処理を目的とし、Key-Value、ドキュメント、グラフなど柔軟なデータモデルを使い、クライアント側JOINやネストデータを好み、ノード追加でスケールする傾向がある。
代表的なNoSQLモデルには、MemcachedやRedisのようなインメモリKey-Valueキャッシュ、DynamoDBのようなKey-Valueストア、CassandraやHBaseのようなワイドカラムストア、Neo4jのようなグラフデータベース、ElasticsearchやMongoDBのようなドキュメントストアがある。
データウェアハウス
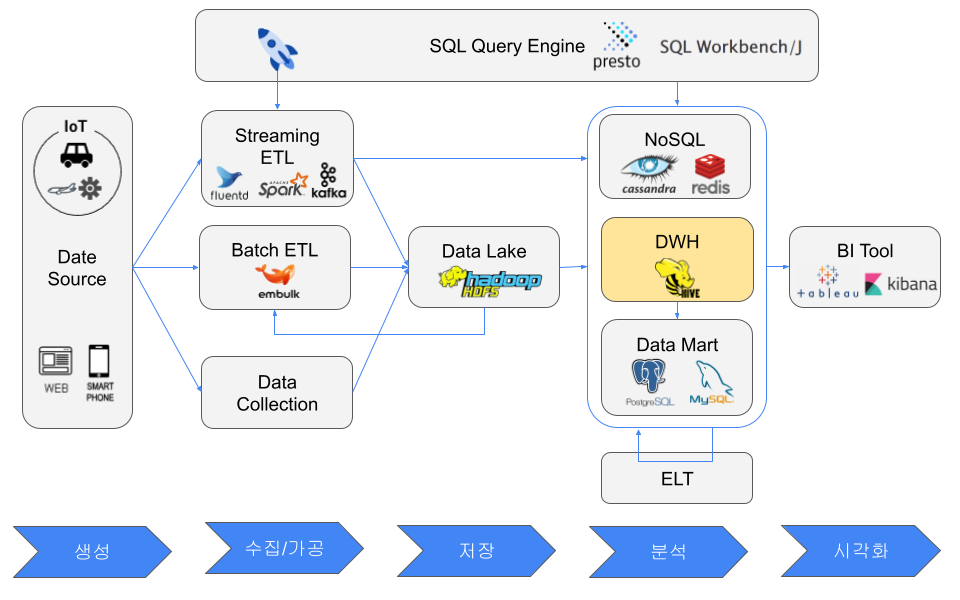
DWHは分析やOLAPに使われ、RDBは一般にトランザクション処理やOLTPに使われる。DWHは列指向ストレージを利用することが多く、大規模分析に向いている。
列指向の保存形式にはORCとParquetがある。列指向データベースは分析時に必要な列だけを読めるため読み取り効率が高い。書き込みは各列ブロックへ値を追加する必要があるため効率が落ちるが、同じ列には似た型や値が並ぶため圧縮率が高い。
例としてSnowflake、Amazon Redshift、ORCやParquetを使うHadoop + Hive/Prestoがある。
データレイクと比べると、DWHは現在必要な構造化データを高速に分析するためのもので、データレイクは将来利用する可能性のあるすべてのデータを保存するためのものである。
データマート
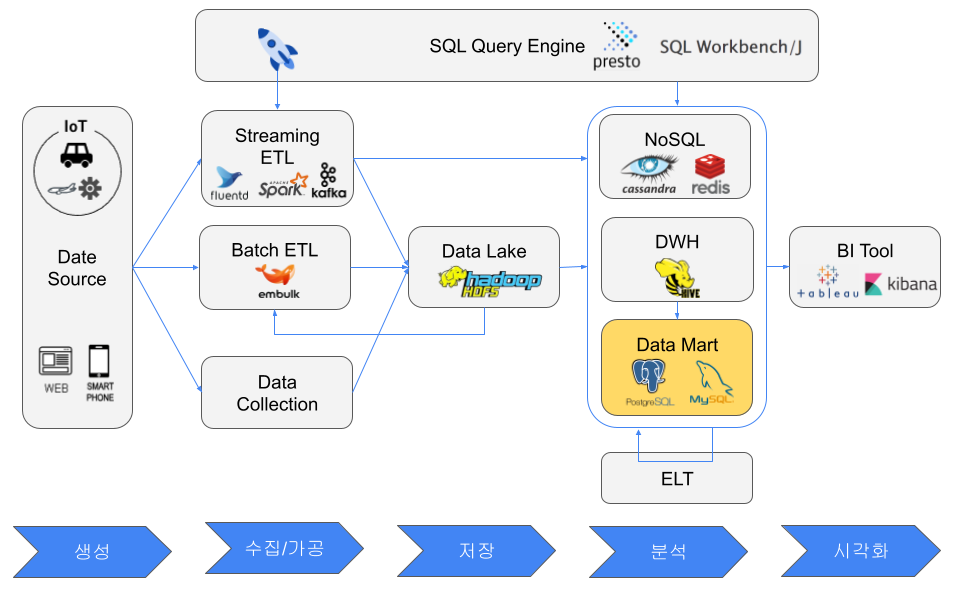
データマートは小規模なデータウェアハウスと考えられる。通常は単一部門向けで、必要なデータだけを含み、小規模な分析では高速である。例としてRDB、小規模なDWHクラスタ、CSVファイルがある。
SQLクエリエンジン
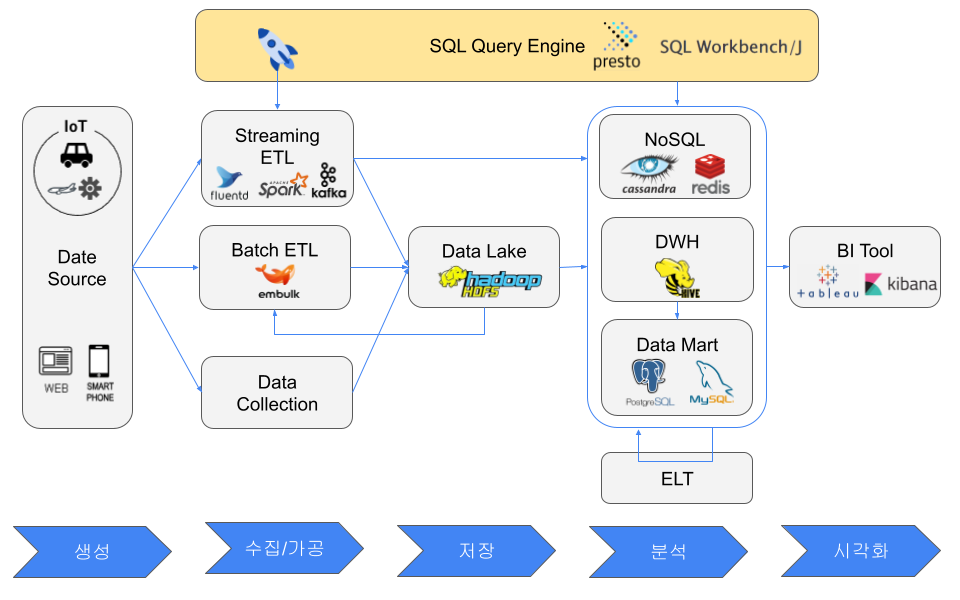
プログラミングせずに簡単にデータを操作したいという要求から、SQLクエリエンジンが生まれた。例としてksqlDB、Apache Flink SQL、Elasticsearch SQL、PartiQL、Presto、Apache Hive、SQL Workbench/J、DBeaverがある。
BIツール
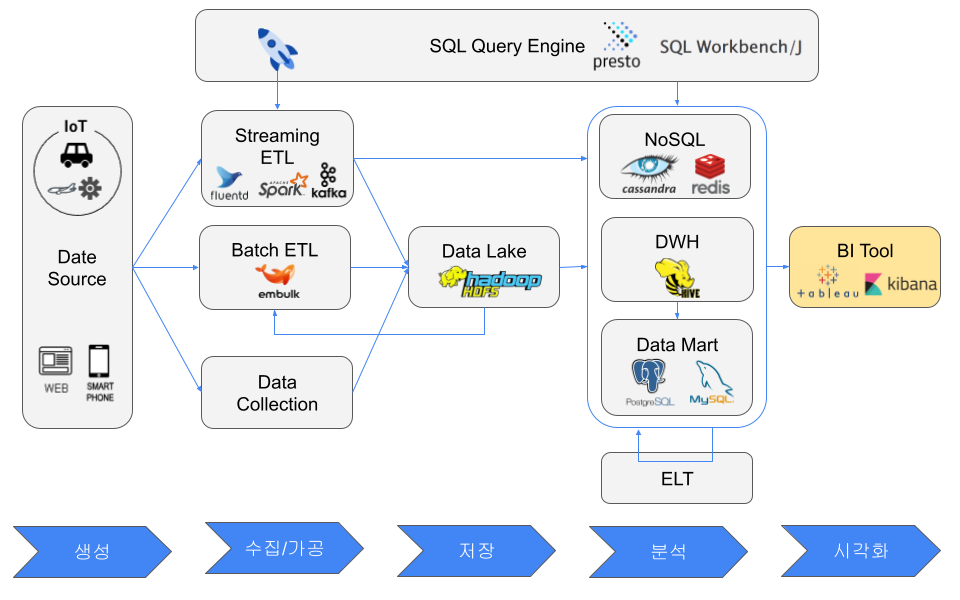
代表的なBIツールにはTableau、Grafana、Kibana、QuickSightがある。
データストアまとめ
RDBは主にトランザクションと固定スキーマの構造化データに使われる。NoSQLは性能重視の用途や柔軟なスキーマで使われることが多い。DWHはOLAPと構造化または半構造化データの分析に使われる。データレイクは、構造化、非構造化、半構造化データを、スキーマレスまたはデータカタログベースで保存する。