データ指向アプリケーションデザイン | 第03章 ストレージと検索
発表者: キム・ギョンチョル、キム・ミンギュ
この章では、データベースがデータをどのように保存し、要求されたときにどのように探し出すのかを扱う。特定のワークロードでよい性能を得るには、ストレージエンジンの内部で行われている処理を大まかに理解しておく必要がある。
主に、ログ構造化ストレージエンジンと、Bツリーのようなページ指向ストレージエンジンを比較する。
データベースを強力にするデータ構造
最も単純なキー・バリューストアは、次の2つのシェル関数で実装できる。
#!/bin/bash
db_set() {
echo "$1, $2" >> database
}
db_get() {
grep "^$1," database | sed -e "S/^$1,//" | tail -n 1
}
db_setはキーと値をファイル末尾に追記する。db_getはファイル全体を走査し、指定されたキーの最新値を返す。追記は速いが、検索はファイル全体を読む必要があるため遅い。計算量で表すと検索コストはO(n)である。
そのためデータベースにはインデックスが必要になる。インデックスは主データから派生した追加のメタデータであり、レコードを効率よく見つけるために使われる。インデックスは読み取りを速くする一方で、書き込みのたびに更新が必要になるため書き込みを遅くする。どのインデックスを作るかは、アプリケーションの典型的なクエリパターンに基づくトレードオフである。
ハッシュインデックス
キー・バリューデータでよく使われる方法は、キーからデータファイル内の最新値のバイトオフセットへの対応を、メモリ上のハッシュマップとして保持することである。
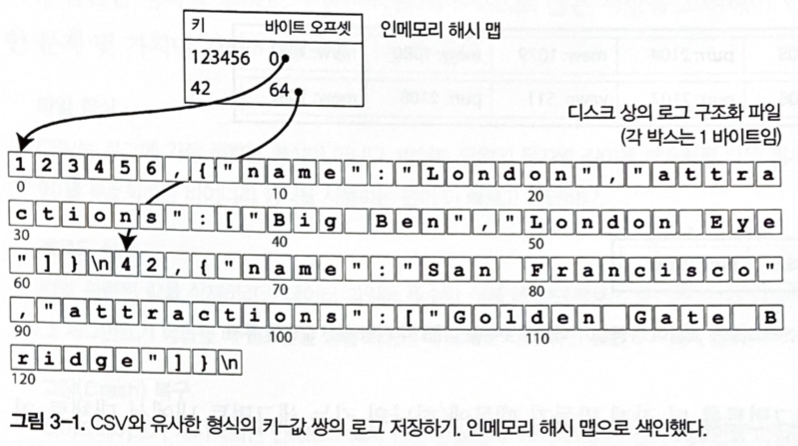
図3-1. CSVに似た形式のキー・バリューペアのログを、メモリ上のハッシュマップでインデックス化する。
新しいキー・バリューペアを追記すると、直前に書き込んだオフセットでハッシュマップを更新する。読み取りでは、メモリ上のハッシュマップでオフセットを探し、その位置から値を読む。RiakのBitcaskストレージエンジンはこの方式を使っている。すべてのキーがRAMに収まり、値が頻繁に更新される用途に向いている。
ログを追記し続けるだけでは、いずれディスク容量が不足する。一般的な解決策はログをセグメントに分割し、定期的にコンパクションすることである。コンパクションでは重複キーの古い値を捨て、各キーの最新値だけを残す。
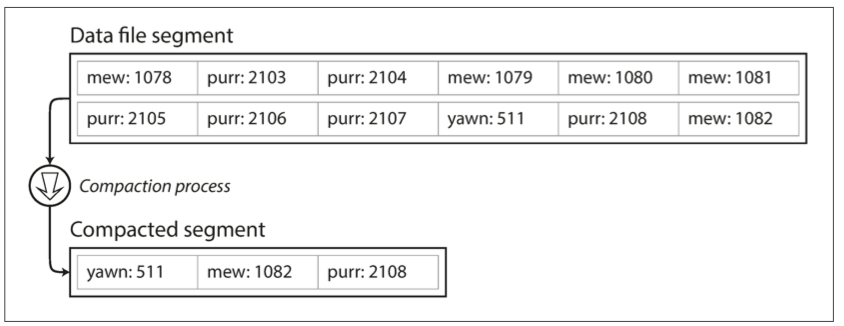
図3-2. キー・バリュー更新ログをコンパクションし、各キーの最新値だけを残す。
セグメントはバックグラウンドでマージすることもできる。古いセグメントは不変なので、新しい圧縮済みセグメントを作成している間も読み書きを継続できる。

図3-3. コンパクションとセグメントマージを同時に行う。
実装では、ファイル形式、削除を表すトゥームストーン、クラッシュ復旧、部分的に書き込まれたレコード、チェックサム、並行性制御などを考慮する必要がある。追記専用ログは、逐次書き込みが速く、不変セグメントにより復旧が単純になり、マージによって断片化を抑えられるため有用である。
ただしハッシュインデックスには制約がある。キーをメモリに保持する必要があり、範囲検索には向かない。範囲検索では個々のキーをすべて調べなければならない。
SSTableとLSMツリー
SSTable(Sorted String Table)は、キー・バリューペアをキー順に並べて保存する。マージされたセグメント内では各キーは一度だけ現れる。ソートされているため、効率的なマージ、疎なメモリ上インデックス、圧縮ブロックが可能になる。

図3-4. 複数のSSTableセグメントをマージし、各キーの最新値だけを残す。
キーがソートされていれば、すべてのキーをインデックスに持つ必要はない。目的のキーが2つのインデックス項目の間にあると分かれば、その小さな範囲だけをスキャンすればよい。
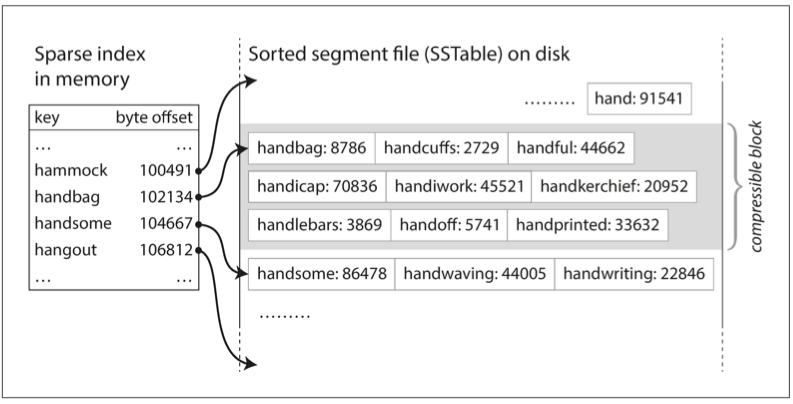
図3-5. メモリ上インデックスを持つSSTable。
書き込みはまずmemtableと呼ばれるメモリ上の平衡木に挿入される。memtableが一定サイズに達すると、SSTableとしてディスクに書き出される。読み取りではmemtable、新しいセグメント、古いセグメントの順に確認する。バックグラウンドコンパクションはセグメントをマージし、上書き済みまたは削除済みの値を除去する。
この系統の技術はLSMツリーとして知られる。LevelDB、RocksDB、Cassandra、HBase、Lucene、Elasticsearch、Solrなどは関連する設計を使っている。存在しないキーに対する不要なディスク読み取りを避けるため、Bloomフィルタもよく使われる。
Bツリー
Bツリーはリレーショナルデータベースで最も広く使われるインデックス構造である。データを通常4KB程度の固定サイズページに分け、親ページから子ページへの参照を保持する。
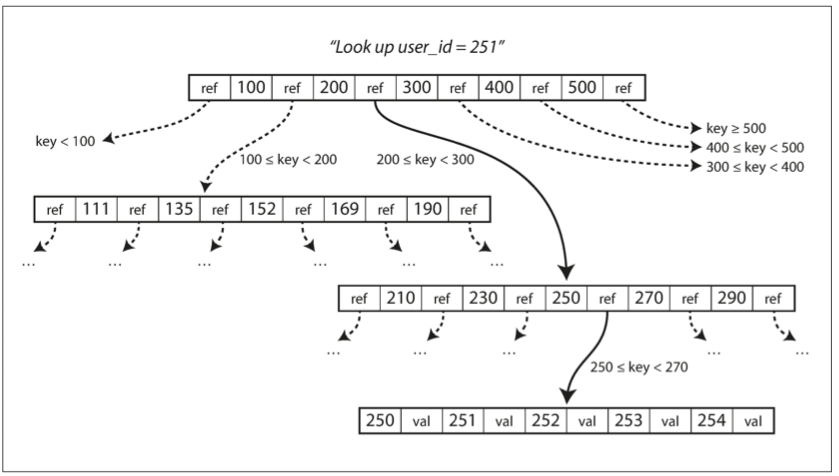
図3-6. Bツリーインデックスでキーを探す。
値を更新するには、データベースがリーフページを探して変更する。ページが満杯であれば分割し、親ページを更新する。Bツリーは木のバランスを保つため、大規模なデータでも検索が効率的である。
更新はページをその場で上書きするため、クラッシュ復旧は複雑になる。多くのデータベースは、途中で中断された操作を再実行できるようにwrite-ahead logを使う。並行性についても、読み手が不整合な木を観測しないように慎重なラッチが必要になる。
BツリーとLSMツリーの比較
LSMツリーはランダム書き込みを逐次書き込みに変換し、バックグラウンドでコンパクションするため、一般に書き込みスループットが高い。圧縮しやすく断片化も避けやすいが、コンパクションは前面の読み書きと競合することがあり、コンパクションが終わるまで同じキーが複数セグメントに存在することもある。
Bツリーは、キーが明確に1つの場所にあるため、読み取り中心のワークロードで有利なことが多い。同じキーが同じインデックス位置に対応するので、トランザクション分離も実装しやすい。
どちらが常に優れているわけではない。適切な選択はワークロード、ハードウェア、コンパクションの挙動、レイテンシ要件によって変わる。
その他のインデックス構造
主インデックスは行を識別するが、セカンダリインデックスは別のフィールドによる検索を可能にする。セカンダリインデックスは結合や検索条件に不可欠であり、行を直接指す場合も、該当する行識別子を保持する場合もある。
インデックスはキーだけでなく値も一緒に保存できる。これはカバリングインデックスと呼ばれる。複合インデックスは複数フィールドにまたがるクエリを支援する。全文検索、あいまい検索、地理空間検索、多次元クエリには専用の構造が使われる。
全文検索エンジンは綴りの違いを許容し、関連度で結果を順位付けすることが多い。地理空間インデックスは二次元または多次元の範囲を検索する必要があり、Rツリーや空間充填曲線のような構造が使われる。
すべてをメモリに置く
メモリが安価になるにつれ、ほとんどまたはすべてのデータをRAMに保持するデータベースも増えている。インメモリデータベースは高速になり得るが、耐久性はログ、スナップショット、レプリケーション、ディスクからの復旧に依存する。主な利点は、単にディスクI/Oを避けることではなく、ディスクページに合わせて符号化する必要のないデータ構造を使える点にある。
トランザクション処理と分析
OLTP(online transaction processing)システムは、ユーザー向けの低レイテンシな読み書きを支える。OLAP(online analytical processing)システムは、大量データに対する複雑なスキャンや集計を支える。
分析ワークロードでは、OLTPシステムからデータを抽出、変換、ロードするデータウェアハウスがよく使われる。これにより、本番のトランザクションシステムへ影響を与えずに重い分析クエリを実行できる。
スター、スノーフレーク、列指向ストレージ
データウェアハウスでは、中心に大きなファクトテーブルを置き、その周囲にディメンションテーブルを配置するスター・スキーマがよく使われる。スノーフレーク・スキーマはディメンションをさらに正規化する。
分析クエリは、多数の行に対して少数の列だけを読むことが多い。列指向ストレージは列ごとにデータをまとめて保存するため、I/Oを削減でき、同じ列の値は似ていることが多いので圧縮も効きやすい。
列圧縮、ビットマップ符号化、ベクトル化処理、CPUキャッシュに適した配置は、分析クエリの性能を大きく改善できる。
マテリアライズドビューとデータキューブ
マテリアライズドビューはクエリ結果を事前計算して保存する。データキューブは複数の次元にまたがる事前集計である。事前計算はよく使うクエリを高速化するが、柔軟性を下げ、元データが変わったときのメンテナンスコストを増やす。
まとめ
ストレージエンジンは、読み取り性能、書き込み性能、ディスク配置、メモリ使用量、クラッシュ復旧、クエリの柔軟性のバランスを取る。ログ構造化エンジンとBツリーは異なるトレードオフを持つ。分析システムは、ポイント更新ではなくスキャンと集計に合わせてデータを構成することで、さらに別のトレードオフを選んでいる。