TiDBストレージ
ストレージとKey-Valueの基礎知識
はじめに
データベース、オペレーティングシステム、コンパイラは、コンピュータソフトウェアを構築する主要な基盤である。データベースはアプリケーション層に近く、ビジネスを支えるシステムとして数十年にわたり開発が続けられており、日々進化している。
多くの人がさまざまな種類のデータベースを利用してきたと思うが、データベース、特に分散データベースの開発経験がある人はごく少数だと思う。データベース実装を知ることはスキル向上につながるだけでなく、他のシステム構築にも役立ち、データベースをよりうまく活用できる。
技術理解を深める最良の方法は、その分野のオープンソースプロジェクトに没頭することだと筆者は考える。データベース分野にも多くの優れたオープンソースプロジェクトがある。このプロジェクトを通じて、特に有名なMySQLやPostgreSQLのソースコードを見たことがある人も多いだろう。分散データベース分野ではTiDBも評価されている数少ないプロジェクトであり、上記製品と同様にソースコードを読むことができる。
しかし、分散データベースは複雑であるため、多くの技術者にとってプロジェクト全体を理解するのは難しいようだ。そのため、筆者はTiDBの技術を分かりやすく解説する記事をまとめることにした。オープンソースから読めるテクニックだけでなく、SQLインターフェースの背後に隠れている実装時のテクニックも多数紹介する。
データ保存
データベースの最も基本的な機能であるデータ保存について説明する。データを保存する方法はいくつもある。最も簡単な方法は、メモリ上にデータ構造を構築し、ユーザーから送られたデータを保存する方法である。たとえば、配列を使ってデータを保存し、データを受け取ると配列に新しい項目を追加できる。このソリューションは単純で基本的な要求を満たし、性能も優れている。しかし、これらの利点を上回る欠点がある。最大の問題は、すべてのデータがメモリに保存されるため、サーバーが停止または再起動したときにデータが失われることである。
データ永続性を実現する手段として、ディスクのような不揮発性ストレージにデータを保存する方法がある。ディスクにファイルを作成し、データを受け取るとファイルに新しいデータを追加する。これは永続的なストレージソリューションだが、これだけでは十分ではない。保存したディスクが破損するとデータが失われるためである。したがって、ディスク破損を想定してRAID(Redundant Array of Independent Disks)で冗長化して使用する。しかし、マシンがダウンしたらどうなるだろうか。データにはアクセスできなくなる。
RAIDは安全な保存場所ではない。他にもネットワーク経由でストレージにデータを保存する方法や、冗長ソフトウェアを利用してハードウェアレベルで複製する方法などがある。これらの方法の問題は、複製時に整合性を維持することである。データの完全性と正確性の保護は基本要件であり、これを達成するには次のような難しい問題がある。
- 高速な書き込み速度が必要である。
- 保存時にデータを一貫して読めなければならない。
- 同時変更を処理しなければならない。
- 複数レコードを原子的に変更しなければならない。
これらの問題はいずれも解決が難しいが、すべてを解決できてこそ優れたデータベースストレージシステムといえる。
この背景をもとに、当社はTiDBのデータストア部分であるTiKVを開発した。まずSQLの概念は忘れ、高性能で高信頼の分散Key-ValueストアであるTiKVの実装方法を紹介する。
※ TiKVはKVSとして利用できる。
Key-Value
データストレージシステムの最初の最重要ステップは、データ保存モデルを決めることである。つまり、どの形式でデータを保存するかを決定することである。TiKVは、キーと値がバイト配列で構成された巨大なマップと考えることができる。このマップでは、キーがバイト配列の生のバイナリビットに基づく比較順に配置される。次の点に注意してほしい。
- これはKey-Valueペアで構成された巨大なマップである。
- このマップでは、Key-Valueペアはキーのバイナリシーケンスに従って順序付けられる。ユーザーはキーの位置を探索し、その後に続くKey-Valueペアに対してメソッドを利用できる。これらのKey-Valueペアはすべてそれより大きい。
ここで述べたストレージモデルとSQLテーブルの関係は何か、と疑問に思う人もいるだろう。はっきり言えば、関係はない。
RocksDB、Raft、Regionの概念
前ではデータの格納とKey-Valueを説明した。今回はRocksDB、Raft、Regionを紹介する。
RocksDB
永続的なストレージエンジンはデータをディスクに保存する。TiKVも例外ではない。しかしTiKVはディスクに直接データを書き込まない。まずTiKVがRocksDBにデータを保存し、RocksDBがデータ保存を実行する。スタンドアロンのストレージエンジン、特に高性能なスタンドアロンエンジンの開発には相当なコストがかかるためである。さまざまな最適化処理に近づく必要がある。
PingCAP社は、RocksDBがすべての要件を満たす優れたオープンソースのスタンドアロンストレージエンジンであることを発見した。Facebookチームがこのエンジンの最適化に取り組んでいる間、PingCAP社は大きな困難なしに改善が進む強力なスタンドアロンエンジンを利用できる利点がある。もちろんPingCAP社もRocksDBへ多少のコード提供はしているが、このプロジェクトのさらなる改善を期待するのは難しい。簡単に言えば、RocksDBはスタンドアロンのKey-Valueマップと見ることができる。
Raft
この複合プロジェクトの最初の重要なステップは、安定して効果的なローカルストレージソリューションを見つけることだった。次は、1台のコンピュータが停止したとき、データの完全性と正確性をどう保護するかという比較的難しい課題である。効果的なのは、データを複数台のコンピュータへ複製する方法である。
そうすれば1台のコンピュータがクラッシュしても、別のコンピュータのレプリカを使用できる。しかし、レプリケーションソリューションは、無効なレプリカがある状況に対応できる安定的で効果的なものでなければならない。難しそうだが、Raftを利用すれば実現できる。RaftはPaxosより理解しやすい、Paxosと同等のコンセンサスアルゴリズムである。Raftに関心があれば、Raftの論文を読むと詳細を確認できる。この外部Raftレポートは基本的なソリューションだけを提示しており、このレポートを厳密に守ると性能が低くなることを指摘しておく。PingCAPはRaftを実装するためにさまざまな最適化を行った。
Raftはコンセンサスアルゴリズムであり、次の三つの重要な機能がある。
- リーダー選出
- メンバーシップ変更
- ログ複製
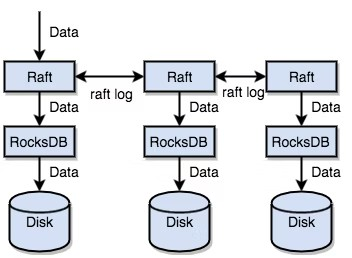
TiKVはRaftを使用してデータを複製する。各データ変更はRaftログとして記録される。データはRaftのログ複製機能を通じて、Raftグループの複数ノードへ安全かつ安定的に同期される。
まとめると、スタンドアロンRocksDBを使えばデータをディスクへ高速に保存できる。Raftを使えば、システム障害に備えて複数システムへデータを複製できる。データはRocksDBへ直接ではなく、Raftインターフェースを通じて記録される。Raft実装のおかげで分散Key-Valueシステムを利用できるようになり、コンピュータ障害を心配する必要がなくなる。
Region
このセクションでは、非常に重要な概念である「Region」について紹介する。Regionは一連のメカニズムを理解するうえで基礎となる。この概念を考える前にRaftを忘れ、すべてのデータにレプリカが一つだけある状況を想像してみよう。
前述のように、TiKVは順序付けられた巨大なKey-Valueマップと見ることができる。ストレージの水平拡張性を得るには、複数システムへデータを分散しなければならない。
Key-Valueシステムには、複数コンピュータへデータを分散する二つの一般的なソリューションがある。一つはハッシュを作り、ハッシュ値に基づいて該当ストレージノードを選ぶソリューションである。もう一つは範囲を使い、連続したキーセグメントをストレージノードに保存するソリューションである。TiKVは二つ目のソリューションを選び、キー値空間全体を複数セグメントに分割する。各セグメントは隣接したキー集合で構成される。これらのセグメントを当社は「Region」と呼ぶ。各Regionが保存できるデータサイズには上限がある。デフォルトは64MBで、このサイズは設定可能である。各Regionは、StartKeyからEndKeyまでの左開右閉区間で表現できる。
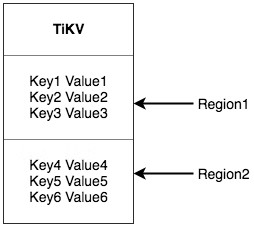
ここで述べているRegionはSQLのテーブルとは何の関係もない。 今はSQLをしばらく忘れ、Key-Valueに集中しよう。
データをRegionに分割した後、次の二つの重要な作業を行う。
- クラスタのすべてのノードにデータを分散し、Regionをデータ移動の基本単位として使用する。各ノードのRegion数がほぼ同じであることを確認する必要がある。
- RegionでRaftによる複製とメンバーシップ管理を行う。
この二つの作業は非常に重要なので、一つずつ説明する。
最初のタスクでは、キーに基づいてデータを複数Regionに分け、各Regionのすべてのデータを一つのノードに保存する。クラスタノード全体へのRegionの均等分散は、当社システムのあるコンポーネントが担当する。その結果、ストレージ容量の水平拡張性が提供される。新しいノードが追加されると、システムは自動的に他ノードからRegionをスケジュールして処理する。一方で負荷分散も達成される。つまり、あるノードに大量のデータが配置され、別のノードには少量しか配置されない状況は発生しない。同時に、上位クライアントが必要なデータへアクセスできるように、別のコンポーネントが複数ノードにまたがるRegionの分散を記録する。つまり、ユーザーはキーを通じて正確なRegionと、そのRegionが配置されたノードを照会できる。この二つのコンポーネントは後で詳しく説明する。
二つ目の作業へ進もう。TiKVはRegionのデータを複製する。つまり、一つのRegionのデータには「Replica」という名前の複数レプリカがある。レプリカ間のデータ整合性を実現するためにRaftが使用される。一つのRegionの複数レプリカは複数の異なるノードに保存され、Raftグループを構成する。一つのレプリカがグループのリーダーとなり、他のレプリカがフォロワーになる。読み取りと書き込みはどちらもリーダーを通じて行われ、リーダーがフォロワーへ複製する。
次の図はRegionとRaftグループの全体像を示している。
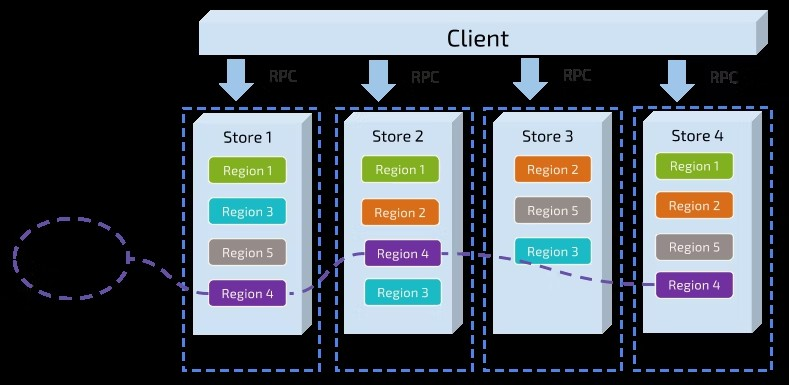
Regionでデータを分散および複製すると、ある程度の災害復旧能力を持つ分散Key-Valueシステムを活用できる。これでユーザーは容量やディスク障害によるデータ損失問題で悩む必要がない。これは素晴らしいが、完全ではない。必要な機能がある。
MVCCとトランザクション
前ではデータ保存、Key-Value、RocksDB、Raft、Regionなどの概念を紹介した。ここではMVCCとトランザクションを紹介する。
MVCC
多くのデータベースは多版型同時実行制御(MVCC: Multi-Version Concurrency Control)を行う。TiKVも例外ではない。MVCCを通さずに二つのクライアントがキー値を同時に更新すると、データがロックされる。分散シナリオでは、この処理は性能問題やデッドロック問題につながる。
TiKVはキーにバージョンを追加してMVCCを実現する。MVCCを行わない場合、TiKVのデータレイアウトは次のようになる。
Key1 -> Value
Key2 -> Value
...
KeyN -> Value
MVCCを行うと、TiKVのキー配列は次のようになる。
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
...
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
...
KeyN-Version2 -> Value
KeyN-Version1 -> Value
...
キーに複数バージョンがあるなら、最も大きい数字を先に配置する。必要であれば、キーとソート済み配列について説明したKey-Valueセクションをもう一度見てほしい。このように、キーにバージョンを追加して値を取得するときは、キーとバージョンを使ったMVCCキー(Key-Version)を構築できる。そしてSeek(Key-Version)を直接実行し、このKey-Version以降の最初の位置を見つけられる。
トランザクション
TiKVのトランザクションはPercolatorモデルを採用しており、多くの最適化が行われている。ここで述べたいのは、TiKVのトランザクションが楽観的ロックを使用するという点である。TiKVのトランザクションは実行プロセス中に書き込み競合を検出しない。競合を検出するのはコミット段階だけである。先にコミットを終了したトランザクションは正常に記録されるが、別のトランザクションは再試行する。その会社の書き込み競合が深刻でなければ、このモデルの性能は非常によい。たとえば、大きなテーブルの複数データ行をランダムに更新する作業にも問題なく対応できる。しかし、書き込み競合が深刻な場合は性能が低下する。カウンターは極端な例だと考えてほしい。多くのクライアントが少数の行を同時に更新する状況は、深刻な競合と多数の失敗した再試行につながる。
まとめ
ストレージ編の記事では、TiKVの基本概念といくつかの詳細、この分散トランザクションKey-Valueエンジンのレイヤー構造、マルチデータセンターの災害復旧を実現する方法などを紹介した。次の記事では、分散データベースTiDBのコンピューティングについて紹介する。