TiDBコンピューティング
前回はTiDBがデータを保存する方法を紹介した。これはTiKVの基本概念でもある。今回は、TiDBが下位レイヤーのKey-Valueにどのようにデータを保存し、リレーショナルモデルをKey-Valueモデルへマッピングし、SQLを実行するのかについて詳しく説明する。
リレーショナルモデルとKey-Valueモデルのマッピング
リレーショナルモデルを単純化し、簡単なテーブルとSQL文だけを考えてみよう。考えるべきことは、テーブルデータの保存とSQL文の実行をKey-Value上でどのように行うかである。次のようなテーブルを考える。
CREATE TABLE User {...
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
Key idxAge (age)
};
一般的なSQLデータベースとKey-Valueの構造には大きな違いがあるため、SQLデータベースをKey-Valueへマッピングする方法が重要である。ここではまず、どのマッピングソリューションがよいかを決めるために、データ保存方法の特徴を説明する。
テーブルには三つのデータが含まれる。ただし、ここではメタデータについては触れない。
- テーブルに関するメタデータ
- テーブルの行数
- インデックスデータ
データは行単位または列単位で保存でき、どちらにも長所と短所がある。TiDBの主な目的はオンライン・トランザクション処理(OLTP)であり、データ行の読み取り、保存、変更、削除を高速に行うことを目標にしているため、行ストアのほうがよい。
TiDBはPrimary IndexとSecondary Indexの両方をサポートする。インデックスの機能はクエリ高速化、高いクエリ性能、制約のためである。クエリには二つの形式がある。
- ポイントクエリ:
select name from user where id = 1;のように、主キーまたは一意キーのような等価条件を使って、インデックス経由で特定のデータ行を探す。 - 範囲クエリ: たとえば
select name from user where age > 30 and age < 35;のように、idxAgeを使って年齢が30から35の間にあるデータをクエリする。インデックスにはUnique IndexとNon-unique Indexの2種類があり、TiDBではどちらもサポートする。
保存するデータの特性を分析した後は、Insert/Update/Delete/Select文のようにデータ操作に必要なものを見る。
- Insert文: 行データをKey-Valueに書き込み、インデックスデータを作成する。
- Update文: 必要に応じて行データとインデックスデータを変更する。
- Delete文: 行データとインデックスの両方を削除する。
- Select文: この4つの中で最も複雑な状況を扱う。
- データ行を簡単かつ高速に読む。この場合、各行にはID(明示的または暗黙的)が必要である。
Select * from user;のように複数行のデータを連続して読む。- インデックスを使用してデータをロードし、ポイントクエリと範囲クエリでインデックスを活用する。
グローバルに分散され、ソートされたKey-Valueエンジンは上記の作業要件を満たす。グローバルにソートされた特徴は、多くの問題を解決する助けになる。次の二つの例で考えよう。
- データ行の高速照会: 単一または複数のキーを作成できると仮定すると、この行を探すときはTiKVが提供するSeekメソッドを使って、このデータ行を高速に見つけられる。
- テーブル全体スキャン: テーブルをKeyのRangeにマッピングできる場合、StartKeyからEndKeyまでスキャンしてすべてのデータを検索できる。インデックスデータの操作方法も同じである。
ここから、これがTiDBでどのように動くかを見る。
TiDBは各テーブルにTableID、各インデックスにIndexID、各行にRowIDを割り当てる。テーブルに整数主キーがある場合、その値がRowIDとして使用される。TableIDはクラスタ全体で一意であり、IndexID/RowIDはテーブル内で一意である。これらのIDはすべてint64である。
各行のデータは次の規則に従ってKey-Valueペアとしてエンコードされる。
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
KeyのtablePrefix/recordPrefixSepは特定の文字列定数であり、Key-Value空間で別のデータを区別するために使用される。インデックスデータは次の規則に従ってKey-Valueペアとしてエンコードされる。
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
上記のエンコード規則はUnique Indexには適用されるが、Non-Unique IndexではUnique Keyを作成できない。理由は、インデックスのtablePrefix{tableID}_indexPrefixSep{indexID}が同一だからである。また複数行のColumnsValueも同一になる場合がある。そのため、Non-unique Indexをエンコードするためにいくつか変更した。
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null
この方法で各行のデータに一意なキーを作成できる。
上記の規則で、キーのxxPrefixはすべて文字列定数であり、異なる種類のデータ間の衝突を避けるために名前空間を区別する機能を持つ。
var(
tablePrefix = []byte{'t'}
recordPrefixSep = []byte("_r")
indexPrefixSep = []byte("_i")
)
行とインデックスのキーエンコードソリューションはどちらも同じ接頭辞を持つ。特にテーブルのすべての行は同じ接頭辞を持ち、インデックスのデータも同じ接頭辞を持つ。これらの同じ接頭辞を持つデータはTiKVのキー空間にまとめて配置される。つまり、接尾辞の符号化方法を慎重に設計し、比較関係が変化しないようにすれば、行やインデックスのデータは整然とTiKVに保存される。したがって、エンコード前後で比較関係が変わらないことをMemcomparableという。どの値でも、encode前の二つのオブジェクトの比較結果は、encode後のバイト配列の比較結果と一致する。注: TiKVのキーとバリューはどちらもプリミティブなbyte配列である。詳細はTiDBのcodecパッケージを参照してほしい。このエンコード方法を採用すると、テーブルのすべての行データはRowID順にTiKVのキー空間へ配置される。また、特定インデックスのデータもインデックスのColumnValue順に配置される。
ここまでの要件とTiDBのマッピングソリューションを考慮し、ソリューションの実現可能性を確認する。
- まず、マッピングソリューションによって行とインデックスデータをKey-Valueデータに変換し、各行と各インデックスデータに一意なキーがあることを確認する。
- 次に、ポイントクエリと範囲クエリの両方をサポートするため、このマッピングソリューションを使って行とインデックスの一部に対応するキーを簡単に作成できる。
- 最後に、テーブルにいくつかの制約を確保する場合、その制約が満たされるか確認するために特定のキーを作り、そのキーの存在を確認できる。
ここまで、テーブルをKey-Valueにマッピングする方法を説明した。
次に、同じテーブル構造を持つ別のケースを紹介する。テーブルに3行のデータがあると仮定する。
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
まず、データの各行はKey-Valueペアにマッピングされる。このテーブルにはIntの主キーがあるため、RowIDの値はこの主キーの値である。このテーブルのTableIDが10で、その行データが次のようであると仮定する。
t10_r1 --> ["TiDB", "SQL Layer", 10].
t10_r2 --> ["TiKV", "KV Engine", 20].
t10_r3 --> ["PD", "Manager", 30].
このテーブルには主キー以外にインデックスがある。インデックスのIDは1で、そのデータは次のようであると仮定する。
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
前述のエンコード規則は、上の例を理解する助けになる。このマッピングソリューションを選んだ理由と目的を理解してほしい。
メタデータ管理とSQLの実現方法
前ではリレーショナルモデルとKey-Valueモデルのマッピングを説明した。今回はメタデータ管理とSQLの実現方法を紹介する。
メタデータ管理
前のセクションでは、テーブルのデータとインデックスがKey-Valueにマッピングされる方法を説明した。ここではメタデータを保存する方法を紹介する。
データベースとテーブルはどちらも、定義とさまざまな属性を表すメタデータを持つ。これらすべての情報はTiKVに保存されなければならない。データベースやテーブルにはそれぞれ固有のIDが設定されており、このIDが固有の識別情報となる。Key-Valueとしてエンコードするときは、このIDをキーに接頭辞m_を付けてエンコードする。このようにキーが生成され、対応するValueにはシリアライズされたメタデータが保存される。
このほかにも、現在のスキーマ情報のバージョンを保存する特殊なKey-Valueがある。TiDBはGoogle F1のOnline Schema change algorithmを採用している。バックグラウンドスレッドは常にTiKVに保存されたスキーマバージョンが変更されたかどうかを確認する。変更がある場合は、一定期間内に変更情報を受け取れるよう管理している。
Key-Value型SQLアーキテクチャ
次の図はTiDBの全体アーキテクチャを示す。
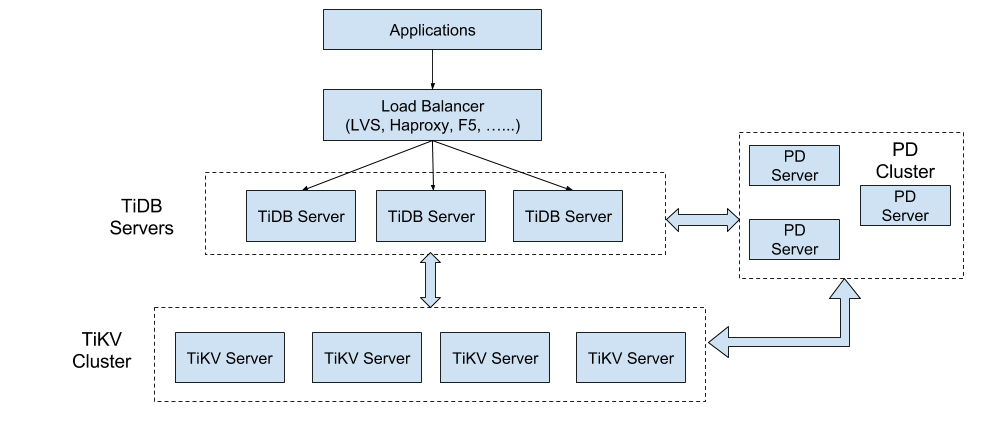
TiKVクラスタの主な機能は、データを保存するKey-Valueエンジンである。これは以前に紹介した。ここではSQLレイヤー、つまりTiDB Serverに注目する。このレイヤーのノードはデータを保存しないステートレス(Stateless)であり、それぞれが完全に同一である。TiDB Serverはユーザーリクエストを処理し、SQL操作ロジックを実行する役割を担当する。
SQLコンピューティング
SQLからKey-Valueへのマッピングソリューションは、リレーショナルデータを保存する方法を示す。次は、このデータを使ってクエリ要求を満たす方法を理解する必要がある。つまり、クエリ文が最下位レイヤーに保存されたデータへどのようにアクセスするかというプロセスである。
最も簡単な方法は、前のセクションで紹介したマッピングソリューションを使用してSQLクエリをKey-Valueクエリへマッピングし、何らかの作業を行う前にKey-Valueインターフェースを使って該当データを取得することである。
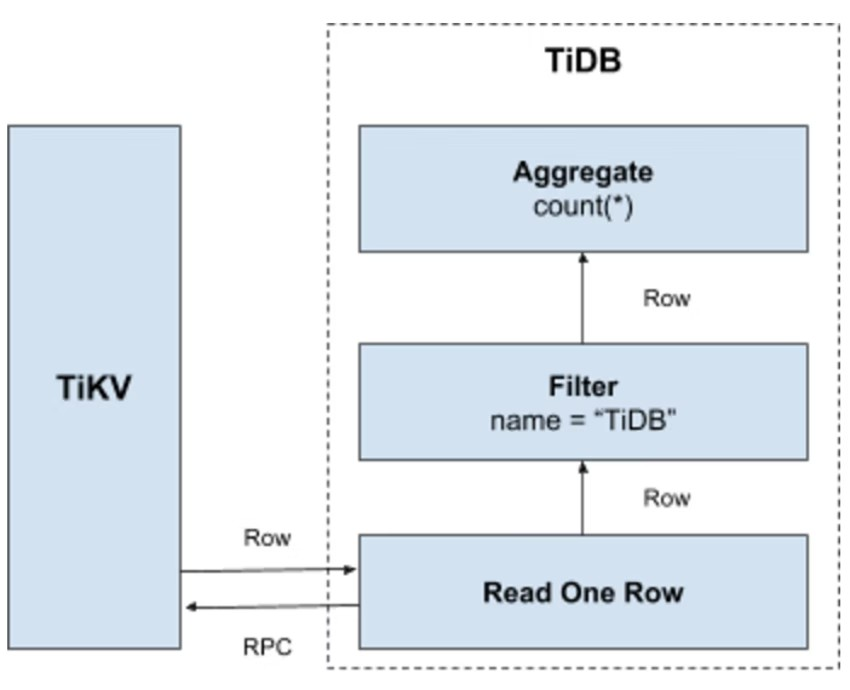
Select count(*) from user where name= "TiDB";というクエリ文では、テーブルのすべてのデータを読み、その後NameフィールドにTiDBがあるか確認する必要がある。そうであればこの行を返す。この操作は次のKey-Value操作プロセスへ移行される。
- キー範囲の生成: テーブルのすべてのRowIDは
[0, MaxInt64]の範囲にあるため、0とMaxInt64および行のキーエンコード規則を使用して、[StartKey, EndKey]のような左閉右開区間を作る。 - キー範囲のスキャン: 事前に作成したキー範囲に従ってTiKVデータを読む。
- データフィルタリング: データの各行を読むとき、
name = "TiDB"の式を評価する。その結果が真ならこの行を返す。そうでない場合、この行をスキップする。 - Count判定: 要件を満たす各行について、Count値に加算する。
プロセスは下の図を参照してほしい。
このソリューションは有効だが、次のような欠点がある。
- データをスキャンするとき、各行をTiKVからKey-Value操作で読む必要がある。そのため少なくとも一つのRPCオーバーヘッドが発生する。このオーバーヘッドはスキャンするデータが多いほど大きくなる。
- すべての行に適用されるわけではない。条件を満たさないデータはロードする必要がない。
- 条件を満たす行の値は重要ではない。ここで必要なのは行数だけである。
分散SQL操作
上記の欠点は簡単に避けられる。
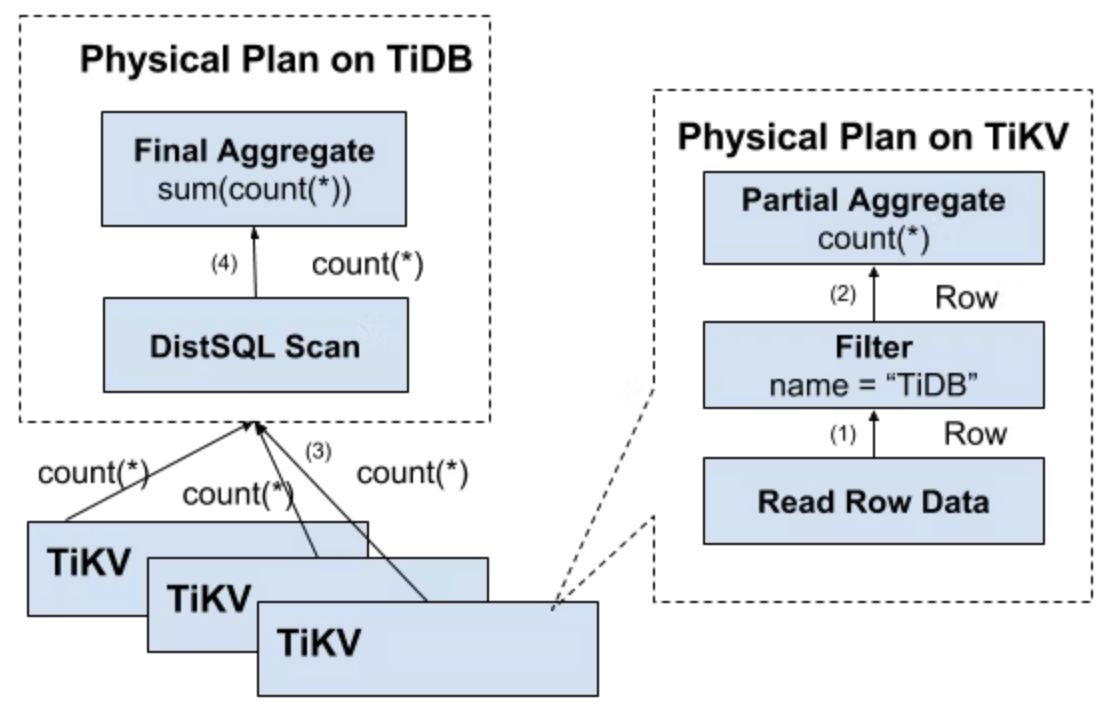
- まず、大量のRPC呼び出しを止めるには、ストレージノードの近くで作業する必要がある。
- 次に、Filterをストレージノードへプッシュダウンする必要がある。この場合、有効な行だけが返され、意味のないネットワーク転送を避けられる。
- 最後に、Aggregate関数とGroupByを押し下げ、事前集計を実行する。各ノードは一つのCount値だけを返すことができ、その後tidb-serverがすべての値を合算する。
次の図は、データがレイヤーごとに戻る様子を示す。
SQLレイヤーアーキテクチャ
前でSQLレイヤーのいくつかの機能を紹介したので、SQL文を処理する方法について基本概念を理解できると思う。実際、TiDBのSQLレイヤーは非常に複雑で、多くのモジュールとレイヤーがある。次の図は、すべての重要なモジュールと呼び出し間の関係を示す。
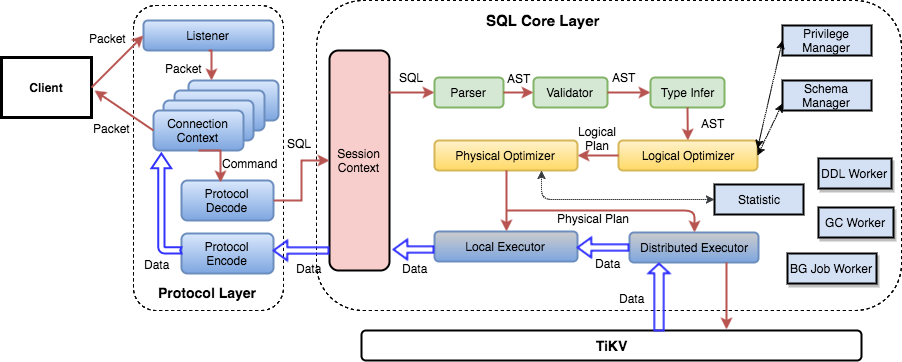
SQLリクエストは直接またはロードバランサー経由でtidb-serverへ送信される。tidb-serverはMySQLプロトコルパケットを解析し、リクエスト内容を確認する。その後、構文解析を行い、クエリ計画を作成して最適化し、計画を実行してデータへアクセスし処理する。すべてのデータはTiKVクラスタに保存されるため、tidb-serverは処理中にデータへアクセスするためtikv-serverと相互作用しなければならない。最後にtidb-serverはユーザーへクエリ結果を返す。
まとめ
ここでは、データがどのように保存され、操作に使われるかをSQLの観点から紹介した。今後は最適化の原理や分散実行フレームワークの詳細など、SQLレイヤーに関する情報を紹介する予定である。次回はPD、特にクラスタ管理とスケジューリングに関する情報を紹介する。