TiDB 컴퓨팅
앞에서는 TiDB가 데이터를 저장하는 방법을 소개했다. (이것은 TiKV의 기본 개념이기도 하다.) 이번에는 TiDB가 어떻게 하단 레이어의 Key-Value에 데이터를 저장하고 관계형 모델을 Key-Value 모델에 매핑하고 SQL을 수행하는지에 대해 자세히 설명한다.
관계형 모델과 Key-Value 모델 매핑
관계형 모델을 단순화하고 간단한 테이블과 SQL 문만을 생각해 보자. 생각해야 할 것은 테이블 데이터의 저장과 SQL문의 실행을 Key-Value상에서 어떻게 하고 있는가이다. 다음과 같은 테이블을 생각한다.
CREATE TABLE User {...
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
Key idxAge (age)
};
일반적인 SQL 데이터베이스와 Key-Value의 구조에는 큰 차이가 있기 때문에 SQL 데이터베이스를 Key-Value에 매핑하는 방법이 중요하다. 여기에서는 먼저 어떤 매핑 솔루션이 좋은지 결정하기 위해, 데이터를 저장하는 방법의 특징을 설명한다.
테이블에는 세 가지 데이터가 포함되어 있다. (다만, 여기에서는 메타데이터에 대해서는 언급하지 않는다.)
- 테이블에 대한 메타데이터
- 테이블의 행 수
- 인덱스 데이터
데이터는 행 단위 또는 열 단위로 저장할 수 있으며, 어느쪽도 장단점이 있다. TiDB의 주요 목적은 온라인 트랜잭션 처리(OLTP)이며, 데이터 행을 읽고, 저장, 변경, 삭제하는 것을 신속하게 수행하는 것을 목표로 하기 때문에, 행 저장소가 더 좋을 것이다.
TiDB는 Primary Index와 Secondary Index를 모두 지원한다. 인덱스의 기능은 쿼리 가속화, 높은 쿼리 성능 및 제약을 위한 것입니다. 쿼리에는 두 가지 형식이 있다.
- 포인트 쿼리:
select name from user where id = 1;와 같이 기본 키 또는 고유 키와 같은 동등한 조건을 사용하여 인덱스를 통해 데이터의 특정 행을 찾는다. - 범위 쿼리: 예를 들어
select name from user where age > 30 and age < 35;와 같이,idxAge을 사용하여 나이가 30에서 35 사이에 있는 데이터를 쿼리한다. 인덱스에는 Unique Index 와 Non-unique Index 의 2가지 종류가 있지만, TiDB 에서는 모두 지원하고 있다.
저장할 데이터의 특성을 분석한 후에는 Insert/Update/Delete/Select 문과 같은 데이터를 조작하는데 필요한 사항으로 보도록 하자.
- Insert 문: 행 데이터를 Key-Value에 쓰고, 인덱스 데이터를 만든다.
- Update 문: 필요에 따라 행 데이터와 인덱스 데이터를 변경한다.
- Delete 문: 행 데이터와 인덱스를 모두 삭제한다.
- Select 문: 이 4가지 중에 가장 복잡한 상황을 다룬다.
- 데이터의 행을 쉽고 빠르게 읽는다. (이 경우 각 행에는 ID(명시적 또는 암시적으로)가 필요한다.)
Select * from user;와 같이 여러 행의 데이터를 연속적으로 읽는다.- 인덱스를 사용하여 데이터를 로드하고, Point 쿼리와 Range 쿼리에서 인덱스를 활용한다.
글로벌로 분산되고, 정렬된 Key-Value 엔진은 위의 작업 요구 사항을 충족한다. 글로벌로 정렬된 특징은 상당히 많은 문제를 해결하는데 도움이 된다. 다음 2가지 예로 생각해 보자.
- 데이터 행의 신속한 조회: 단일 또는 복수의 키를 작성할 수 있다고 가정히여, 이 행을 찾을 때는, TiKV가 제공하는 Seek 메소드를 사용하여 이 데이터의 행을 신속하게 찾아낼 수가 있다.
- 테이블 전체 스캔: 테이블을 Key의 Range에 매핑할 수 있는 경우는 StartKey에서 EndKey까지 스캔하여 모든 데이터를 검색할 수 있다. 인덱스 데이터를 조작하는 방법도 마찬가지이다.
이제는 이 TiDB에서 어떻게 작동하는지 살펴 보겠다.
TiDB는 각 테이블에 TableID, 각 인덱스에 IndexID을, 각 행에 RowID을 할당한다. 테이블에 정수 기본 키가 있으면 해당 값이 RowID로 사용된다. TableID는 클러스터 전체에서 고유하며 IndexID/RowID는 테이블 내에서 고유한다. 이러한 ID는 모두 int64 이다.
각 행의 데이터는 다음 규칙에 따라 키-값 쌍으로 인코딩된다.
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
Key의 tablePrefix/recordPrefixSep는 특정 문자열 상수이며, Key-Value 공간에서 다른 데이터를 구별하는데 사용된다. 인덱스 데이터는 다음 규칙에 따라 Key-Value 쌍으로 인코딩된다.
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
위의 인코딩 규칙은 Unique Index에는 적용되지만, Non-Unique Index에서는 Unique Key를 만들 수 없다. 그 이유는 인덱스의 tablePrefix{tableID}_indexPrefixSep{indexID}가 동일하기 때문이다. 또한 여러 줄의 ColumnsValue도 동일할 수 있다. 그래서 Non-unique Index를 인코딩하기 위해 몇 가지 변경을 했다.
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null
이 방법으로 각 행의 데이터에 고유한 키를 만들 수 있다.
위의 규칙에서 키의 xxPrefix는 모두 문자열 상수이며, 다른 유형의 데이터 간의 충돌을 피하기 위해 네임 스페이스를 구별하는 기능을 가지고 있다.
var(
tablePrefix = []byte{'t'}
recordPrefixSep = []byte("_r")
indexPrefixSep = []byte("_i")
)
행과 인덱스의 키 인코딩 솔루션 모두 동일한 접두사를 가진다. 특히 테이블의 모든 행은 동일한 접두사를 가지며, 인덱스의 데이터도 동일한 접두사를 갖는다. 이러한 동일한 접두사를 가진 데이터는 TiKV의 키 공간에 함께 배치된다. 즉, 접미사의 부호화 방법을 신중하게 설계하고 비교 관계가 변화하지 않도록 하면 행이나 인덱스의 데이터가 가지런히 질서있게 TiKV에 저장되게 된다. 따라서 인코딩 전후에 비교 관계가 변경되지 않는 것을 Memcomparable 이라고 한다. 어떠한 값이라도 encode 전의 2개의 오브젝트의 비교 결과는 encode 후의 바이트 배열의 비교 결과와 일치한다(주: TiKV 의 키와 밸류는 모두 프리미티브인 byte 배열이다). 자세한 내용은 TiDB의 코덱 패키지를 참조하여라. 이 인코딩 방법을 채택하면 테이블의 모든 행 데이터가 RowID 순서에 따라 TiKV의 키 공간에 배치된다. 또한, 특정 인덱스의 데이터도 인덱스의 ColumnValue 순서로 배치된다.
이제 지금까지 요구 사항과 TiDB 매핑 솔루션을 고려하여, 솔루션의 실현 가능성을 확인한다.
- 먼저, 매핑 솔루션을 통해 행과 인덱스 데이터를 Key-Value 데이터로 변환하고 각 행과 각 인덱스 데이터에 고유한 키가 있는지 확인한다.
- 그런 다음 Point 쿼리와 Range 쿼리를 모두 지원하므로 이 매핑 솔루션을 사용하여 행과 인덱스의 일부에 해당하는 키를 쉽게 만들 수 있다.
- 마지막으로 테이블에 몇 가지 제약 조건을 확보하는 경우, 해당 제약 조건이 충족되는지 확인하기 위해 특정 키를 만들고 해당 키의 존재를 확인할 수 있다.
지금까지 테이블을 Key-Value에 매핑하는 방법을 설명하였다.
다음으로 같은 테이블 구조를 가진 또 다른 경우를 소개한다. 테이블에 3행의 데이터가 있다고 가정한다.
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
먼저, 데이터의 각 행은 Key-Value 쌍으로 매핑된다. 이 테이블에는 Int의 기본 키가 있으므로, RowID의 값은 이 기본 키의 값이다. 이 테이블의 TableID가 10이고, 그 행 데이터가 다음과 같이 가정한다.
t10_r1 --> ["TiDB", "SQL Layer", 10].
t10_r2 --> ["TiKV", "KV Engine", 20].
t10_r3 --> ["PD", "Manager", 30].
이 테이블에는 기본 키 외에 인덱스가 있다. 인덱스의 ID는 1이고, 그 데이터는 다음과 같이 가정한다.
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
앞에서 설명한 인코딩 규칙은 위의 예를 이해하는데 도움이 된다. 우리가 이 매핑 솔루션을 선택한 이유와 그 목적을 이해해 주길 바란다.
메타데이터 관리 및 SQL의 실현 방법
앞에서 관계형 모델과 Key-Value 모델의 매핑을 설명하였다. 이번에는 메타데이터 관리 및 SQL의 실현 방법을 소개하겠다.
메타데이터 관리
이전 섹션에서는 테이블의 데이터와 인덱스가 Key-Value에 매핑되는 방법을 설명하였다. 여기에서는 메타데이터를 저장하는 방법을 소개한다.
데이터베이스와 테이블 모두 정의와 다양한 속성을 나타내는 메타데이터를 가지고 있다. 이러한 모든 정보는 TiKV에 저장되어야 한다. 데이터베이스나 테이블에는 각각 고유의 ID가 설정되어 있어, 이 ID가 고유의 식별 정보가 된다. Key-Value로 인코딩할 때는, 이 ID를 키에 접두사로 m_붙여 인코딩한다. 이런 식으로 키가 생성되고 해당 Value에는 serialize된 메타데이터가 저장된다.
이 외에도 특수한 Key-Value는 현재 스키마 정보의 버전을 저장한다. TiDB는 Google F1의 Online Schema change algorithm을 채택하고 있다. 백그라운드 스레드는 항상 TiKV에 저장된 스키마 버전이 변경되었는지 여부를 확인한다. 변경이 있는 경우는 일정 기간내에 변경 정보를 받을 수 있도록 관리하고 있다.
Key-Value형 SQL 아키텍처
아래 다이어그램은 TiDB의 전체 아키텍처를 보여준다.
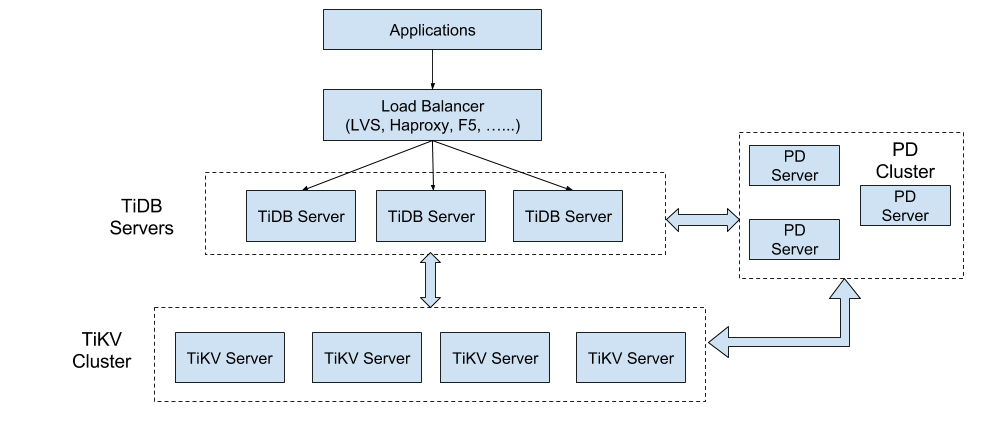
TiKV 클러스터의 주요 기능은 데이터를 저장하는 Key-Value 엔진이다. (이는 이전에 소개하였다.) 여기서는 SQL 계층, 즉, TiDB 서버에 중점을 둔다. 이 계층의 노드는 데이터를 저장하지 않는 스테이트리스(Stateless)이며, 각각은 완전히 동일하다. TiDB 서버는 사용자의 요청을 처리하고, SQL 조작 로직을 수행하는 역할을 담당한다.
SQL 컴퓨팅
SQL에서 Key-Value로의 매핑 솔루션은 관계형 데이터를 저장하는 방법을 보여준다. 다음은 이러한 데이터를 사용하여 쿼리 요청을 충족하는 방법을 이해해야 한다. 즉, 질의문이 최하위 계층에 저장된 데이터에 어떻게 액세스하는지에 대한 프로세스이다.
가장 간단한 방법은 이전 섹션에서 소개한 매핑 솔루션을 사용하여 SQL 쿼리를 Key-Value 쿼리에 매핑하고 일부 작업을 수행하기 전에 Key-Value 인터페이스를 사용하여 해당 데이터를 검색하는 것이다.
Select count(*) from user where name= "TiDB";라는 쿼리문에 대해서는 테이블의 모든 데이터를 읽은 다음 Name 필드에 TiDB가 있는지 확인해야 한다. 그렇다면 이 행을 반환한다. 이 조작은 다음 Key-Value 조작 프로세스로 마이그레이션 된다.
- 키 범위 생성 : 테이블의 모든 RowID는
[0, MaxInt64]의 범위에 있으므로 0과 MaxInt64 및 행의 키 인코딩 규칙을 사용하여[StartKey, EndKey]와 같이 왼쪽-닫기-오른쪽-열기의 구간을 만든다. - 키 범위 스캔 : 미리 작성한 키 범위에 따라 TiKV 데이터를 읽는다.
- 데이터 필터링 : 데이터의 각 행을 읽을 때,
name = "TiDB"의 표현을 판단한다. 그 결과가 참이면 이 행으로 되돌아 간다. 그렇지 않은 경우 이 행을 건너뛴다. - Count 판단: 요구 사항을 충족하는 각 행에 대해, Count 값에 더한다.
프로세스는 아래 그림을 보도록 한다.
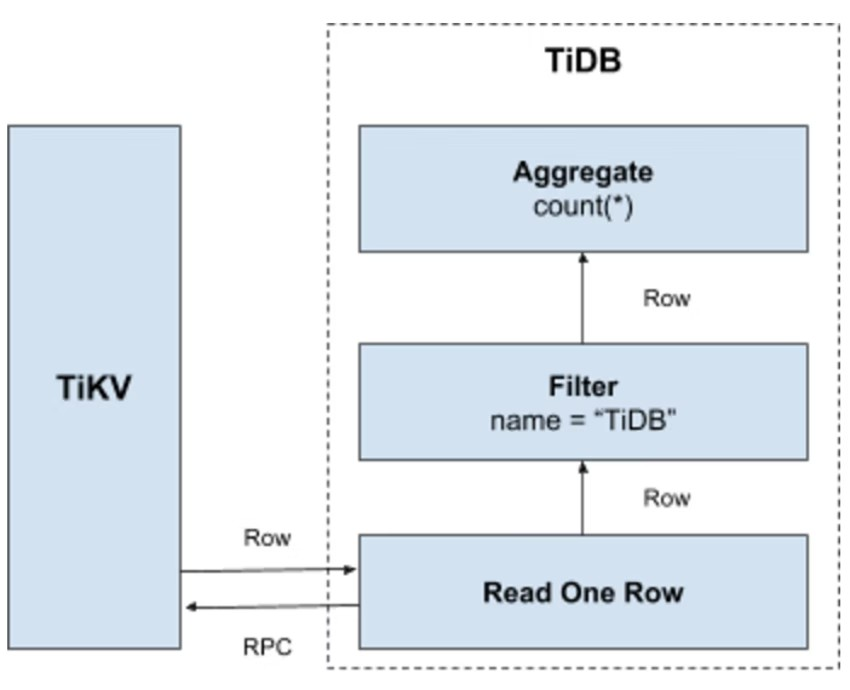
이 솔루션은 효과적이지만 다음과 같은 단점이 있다.
- 데이터를 스캔할 때는 각 행을 TiKV에서 Key-Value 조작으로 읽어야 한다. 따라서 최소한 하나의 RPC 오버헤드가 발생한다. 이 오버헤드는 스캔할 데이터가 많으면 커진다.
- 모든 행에 적용되는 것은 아니다. 조건을 충족하지 않는 데이터는 로드할 필요가 없다.
- 조건을 충족하는 행의 값은 중요하지 않ㅣ다. 여기서 필요한 것은 행 수뿐이다.
분산 SQL 조작
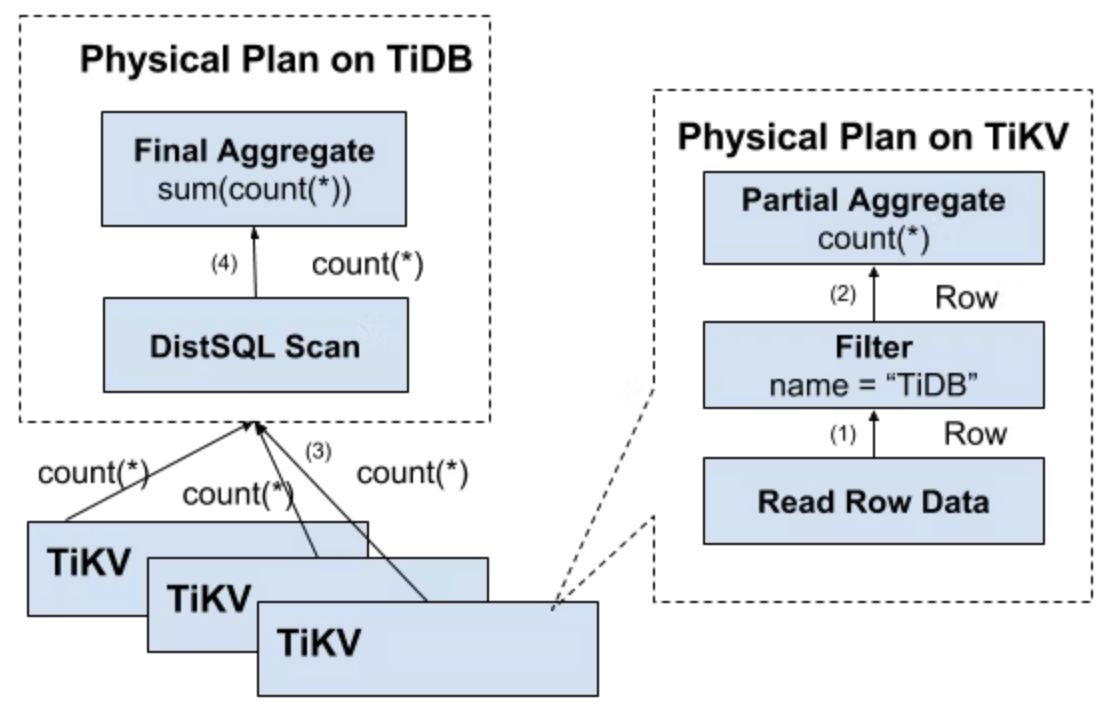
위의 단점은 쉽게 피할 수 있다.
- 먼저, 많은 양의 RPC 호출을 중지하려면 스토리지 노드 가까에서 작업을 해야 한다.
- 그러고, Filter를 스토리지 노드로 푸시다운해야 한다. 이 경우는 유효한 행만 반환되고 무의미한 네트워크 전송은 피할 수 있다.
- 마지막으로 Aggregate 함수와 GroupBy를 누른 다음 사전 집계를 수행한다. 각 노드는 단지 하나의 Count 값을 반환할 수 있으며, 그 후 tidb-server는 모든 값을 합산한다.
다음 그림은 데이터가 계층별로 되돌아오는 모습을 나타낸다.
SQL 계층 아키텍처
앞에서 SQL 계층의 몇 가지 기능을 소개했으므로, SQL 문을 처리하는 방법에 대한 기본 개념을 이해할 수 있다고 생각한다. 사실, TiDB의 SQL 레이어는 매우 복잡하며 많은 모듈과 레이어가 있다. 다음 그림은 모든 중요한 모듈과 호출 간의 관계를 나타낸다.
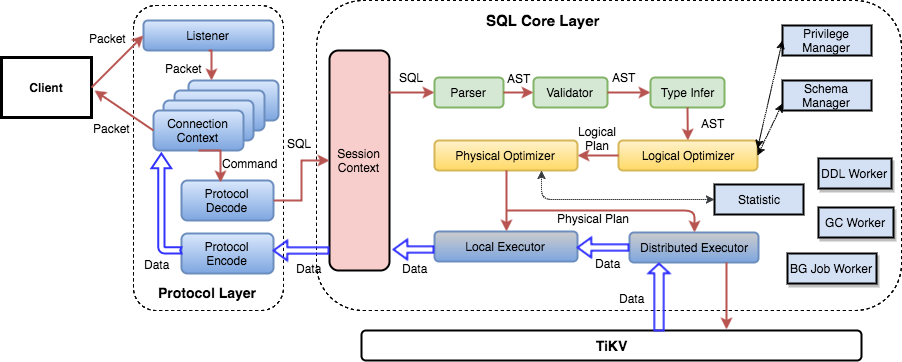
SQL 요청은 직접 또는 로드 밸런서를 통해 tidb-server로 전송되며, tidb-server는 MySQL 프로토콜 패킷을 구문 분석하여 요청 내용을 확인한다. 그런 다음 구문 분석을 수행하고 쿼리 계획을 만들고 최적화하며 계획을 실행하여 데이터에 액세스하고 처리한다. 모든 데이터는 TiKV 클러스터에 저장되므로 tidb-server는 처리 중에 데이터에 액세스하기 위해 tikv-server와 상호작용해야 한다. 마지막으로 tidb-server는 사용자에게 쿼리 결과를 반환해야 한다.
마무리
여기에서는 데이터가 어떻게 저장되고 조작에 사용되는지 SQL 관점에서 소개하였다. 앞으로는 최적화의 원리와 분산 실행 프레임워크의 상세 등 SQL 계층에 대한 정보를 소개할 예정이다. 다음에서는 PD, 특히 클러스터 관리 및 일정에 대한 정보를 소개한다.