Kafka Streams를 사용한 스트림 처리 어플리케이션 개발
스트림 프로세싱이란?
이벤트 스트림에 대해 데이터가 도착할 때마다 처리를 하여, 계속해서 이어가는 어플리케이션을 가리킨다. Kafka의 에코시스템에 있어서는 Kafka Broker에 Consumer로서 접속하여 무한 루프로 polling를 실행하여, 데이터가 도착할 때마다 짧은 간격(interval)으로 처리를 실시하는 어플리케이션이다.
복수의 레코드를 사용해 집계 처리를 실시하는 경우도 있지만, 일정 기간마다 집계 단위를 구분하여, 1건 마다 집계 결과를 업데이트 하거나, 버퍼링해 두고 일정한 간격을 두고 처리를 실행하여 집계를 하는 등의 형태이다.
Stateless 또는 Stateful
스트림 프로세싱의 처리 내용은 크게 Stateless 또는 Stateful로 나눌 수 있다.
Stateless 처리란, 어느 이벤트 레코드가 도착했을 때, 그 레코드만으로 처리가 완료하는 처리를 말한다. 레코드 A를 레코드 B의 형태로 변환하여 다른 토픽이나 다른 데이터 스토어로 전송하는 처리 등이 일반적이다.
한편, Stateful한 처리란, 도착한 이벤트 레코드나 그것을 기초로 생성한 데이터를 일정 기간 보관 유지해 두고, 그것과 조합하여 결과를 생성하는 처리를 말한다. 일반적으로 이벤트 수를 집계하여 합계, 평균 및 히스토그램(histogram)을 산출하거나, 처리 효율성을 위해 버퍼링하여 정리하여 처리한다거나, 다른 스트림과 데이터 스토어와 데이터를 결합하여 데이터를 질을 높일 수 있게 하는 것을 들 수 있다.
Stateful한 처리에 있어서는 일정량의 레코드를 저장해 두는 데이터 스토어가 별도 필요하게 되는데, 이를 StateStore라고 한다. 스트림 프로세싱에 있어서의 StateStore에는 중요하게 고려해야 할 포인트가 몇개 존재하는데, 이는 이후에 계속해서 설명하도록 하겠다.
Stateful 애플리케이션의 State Store
스트림 프로세싱은 어느 데이터가 도달하면 그 때마다 처리가 행해지므로, 어떤 데이터 스토어를 이용하면 데이터가 올 때마다 데이터의 받거나 보존을 해야 한다.
따라서, 중요한 요소로 낮은 대기 시간이 필요하다. 데이터 양에 따라 Redis와 같은 간단하고 빠른 KVS라도 네트워크 대기 시간이 발생 할수 있기 때문에 충분하다고는 할 수 없다.
그래서 스트림 프로세싱에서는 기본적으로 각 처리 노드의 로컬에 데이터 스토어를 보관 유지하고 레이턴시를 낮게 유지하는 방법을 채택한다.
이후에 설명할 Kafka Streams나 Apache Flink 등의 스트림 프로세싱 프레임워크에서는 RocksDB가 사용되고 있다. RocksDB는 애플리케이션에 통합되는 KVS 유형으로 각 노드의 로컬로 RocksDB를 이동시켜 낮은 대기 시간 상태를 유지한다.
각 노드의 로컬로 이동한다는 것은 노드가 의도하지 않은 사고로 다운되어 복귀 불능이 되면 데이터가 손실될 위험이 있음을 의미한다. 이를 피하기 위해 노드 독립적인 데이터 지속성 메커니즘도 별도로 필요하다. 이 구조에서는 네트워크 통신의 오버 헤드는 불가피하기 때문에 어느 정도의 버퍼링이 필요하다.
또한, Kafka를 이용한 스트리밍 애플리케이션에서는 확장성을 보장하기 위해 애플리케이션을 분산하여 여러 노드에서 실행할 수 있다. 이러한 경우에는 노드 갯수의 증가에 따라 처리하는 파티션의 할당이 바뀔 가능성이 있다. 앞장에서 설명했듯이 Kafka Consumer는 동일한 Consumer Group에서는 하나의 파티션을 처리할 수 있는 것은 하나의 클라이언트뿐이다. 대수가 증감하면 그 할당이 재배치되게 되어, 처리 대상이 다른 노드에 이동하는 것을 고려하지 않으면 안된다. 처리가 다른 노드로 이동하게 되었을 때에 그때까지 각 노드의 로컬로 보관 유지하고 있던 데이터를 어쨌든 새롭게 처리가 할당할 수 있었던 노드에 옮겨놓지 않으면, 지금까지 유지하고 있던 StateStore의 데이터가 이용 할 수 없게 된다. 예를 들어, 노드가 늘어난 순간에 집계된 카운트가 갑자기 0으로 돌아가게 되는 것이다. 이를 피하기 위해 처리 노드의 전환에 맞게 StateStore를 재배치하는 메커니즘이 필수적이다.
Kafka Streams란?
Kafka Streams는 Apache Kafka 개발 프로젝트에서 공식적으로 제공되는 스트림 프로세싱 프레임워크이다. Java로 구현되어 있다.
앞에서 설명한 대로 Stateful한 어플리케이션을 구현하려고 하면, 그 상태 관리에 상당히 복잡한 구조가 요구된다. Kafka Streams를 이용하면 프레임워크가 이러한 복잡성을 간소화 할수 있다. 또, Consumer 클라이언트의 polling loop나 다른 토픽에 레코드를 전송하기 위한 Producer 클라이언트의 집계 등도 복잡해지기 때문에, Stateless인 어플리케이션이라도 대폭으로 코드를 간략화할 수 있다.
기본적으로 여기에서 설명하는 것은 Confluent가 제공하는 문서에 대략적으로 작성되어 있다. 더 상세를 알고 싶다면 참조하여라.
cf. Confluent | Streams Concepts
주요 특징
Kafka의 개발에 주요한 역할을 담당하고 있는 Confluent의 문서에 따르면 다음과 같은 특징이 있다.
Powerful
- Makes your applications highly scalable, elastic, distributed, fault-tolerant
- Supports exactly-once processing semantics
- Stateful and stateless processing
- Event-time processing with windowing, joins, aggregations
- Supports Kafka Streams Interactive Queries to unify the worlds of streams and databases
- Choose between a declarative, functional API and a lower-level imperative API for maximum control and flexibility
고기능
- 애플리케이션에 높은 확장성, 탄력성, 분산성, 내결함성을 구현
- “엄밀히 한번"의 처리 시멘틱스 지원
- Stateful와 stateless 프로세싱
- 윈도우, 조인, 집계를 사용한 이벤트 시간 프로세싱
- 스트림과 데이터베이스를 통합하기 위해 Kafka Streams의 대화형 쿼리를 지원
- 높은 제어성과 유연성을 위해 선언형으로 함수형 API와 하위 레벨의 명령형 API 중에서 선택할 수 있다.
Lightweight
- Low barrier to entry
- Equally viable for small, medium, large, and very large use cases
- Smooth path from local development to large-scale production
- No processing cluster required
- No external dependencies other than Kafka
가벼운 기능
- 도입에 진입 장벽이 낮음
- 소규모, 중규모, 대규모, 특대규모의 사례에 대응
- 로컬 개발 환경에서 대규모 프로덕션 환경으로 원활하게 전환
- 처리 클러스터 필요 없음
- Kafka 이외의 외부 종속성 없음
이 중에서도 가장 중요하다고 생각되는 점은 Kafka 이외의 외부 의존관계가 없다는 점이다. 이러한 분산 처리 프레임워크의 경우, YARN과 같은 리소스 매니저나 다른 데이터 스토어가 필요한 경우도 종종 있지만, Kafka Streams에는 필요하지 않는다. 이는 도입의 진입 장벽을 크게 낮춰준다.
Tutorial 코드
Kafka Streams으로 응용 프로그램을 만들려먼 다음과 같은 코드를 작성해야 한다. (공식 문서로부터의 인용을 조금 변경한 것이다.)
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.kstream.StreamsBuilder;
import org.apache.kafka.streams.processor.Topology;
// Use the builders to define the actual processing topology, e.g. to specify
// from which input topics to read, which stream operations (filter, map, etc.)
// should be called, and so on. We will cover this in detail in the subsequent
// sections of this Developer Guide.
StreamsBuilder builder = new StreamsBuilder();
builder
.stream(inputTopic, Consumed.with(stringSerde, stringSerde))
.peek((k,v) -> logger.info("Observed event: {}", v))
.mapValues(s -> s.toUpperCase())
.peek((k,v) -> logger.info("Transformed event: {}", v))
.to(outputTopic, Produced.with(stringSerde, stringSerde));
Topology topology = builder.build();
//
// OR
//
topology.addProcessor(...); // when using the Processor API
// Use the configuration properties to tell your application where the Kafka cluster is,
// which Serializers/Deserializers to use by default, to specify security settings,
// and so on.
Properties props = ...;
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start(); // non blocking
이처럼 Kafka Streams는 DSL을 연결하거나 Processor API라는 특정 인터페이스의 규칙에 맞게 Java 클래스를 구현하는 것만으로 Kafka에 접속하는 Consumer나 Producer를 만들 수 있고, 처리 스레드의 시작 등도 간략화할 수 있다.
Kafka Streams 애플리케이션 모델
Kafka Streams는 Source Node, Processor Node, Sink Node를 조합하여 Topology라는 단위를 만들어 애플리케이션을 구축한다. 각각 어떤 의미를 가지는지 설명해 보도록 하겠다.
Topology
Topology 라는 단어는 기본으로 수학 용어로 위상 기하학을 나타낸다. 수학도가 아니어서 자세하게는 설명할 수 없지만, 물건의 형상이 가지는 성질에 초점을 맞춘 학문과 같은 것이다. 거기에서 파생되어 네트워크 토폴로지라는 네트워크 그래프가 어떤 구성을 하고 있는지의 형상 패턴을 가리키는 용어가 있다. Kafka Streams의 Topology는 이 네트워크 토폴로지와 동일하다고 생각할 수 있다.
Kafka Streams는 특정 역할을 가진 노드를 연결하여 그래프 구조를 구축하고 Topology를 형성하고 동작한다. 이 Topology는 2개 이상의 하위 토폴로지에 의해 형성될 수 있다.
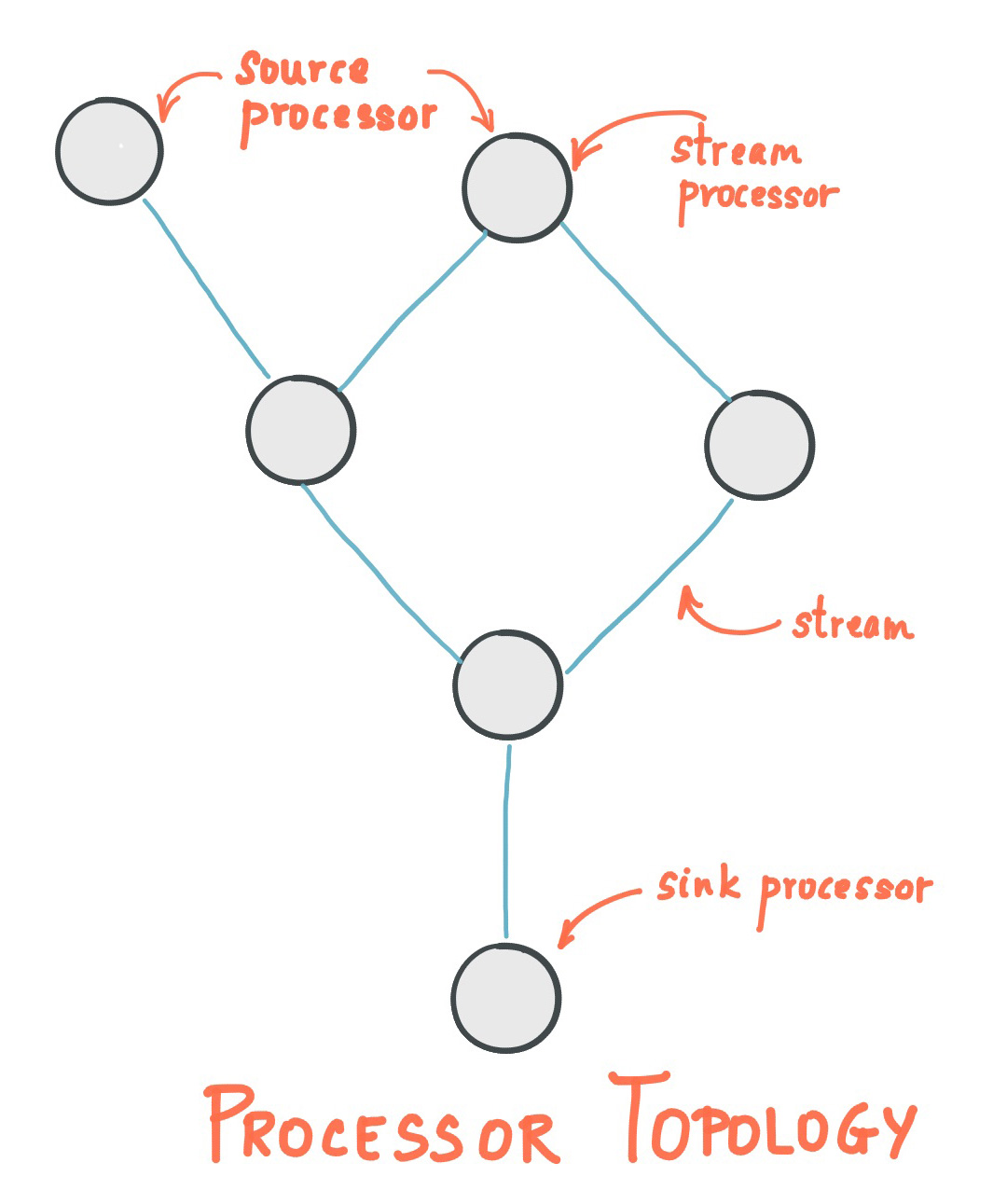
이미지 : Confluent | Streams Architecture
이러한 그래프 구조를 하나 이상 보관 유지하는 객체가 Kafka Streams의 Topology이다.
두개 이상의 하위 토폴로지가 어떻게 생성되는지에 따라, 하나의 응용 프로그램이 여러 소스 토픽에서 데이터를 받아오도록 정의되었고, 소스 토픽에 의존하는 Processor Node 또는 Sink Node에 직접 종속성이 없는 경우이다. 즉, Source Node에서 추적하여 하나의 그래프가 구축되도록 의존관계가 연결되어 있는 범위가 하나의 서브 토폴로지이다. 위의 예에서는 Source Node가 여러 개 있지만, 아래 Processor가 양쪽의 Source Node에 의존하고 있기 때문에 그래프가 하나에 연결되어 있는 것을 알 수 있다. 이 경우 서브 토폴로지는 하나이다. 만약, 왼쪽의 Source Node가 그 외의 전체와 독립해 어떤 것도 연결되어 있지 않은 Processor Node에만 의존하고 있는 경우는 2개의 서브 토폴로지가 될 수 있게 된다.
Source Node
Kafka 토픽서 데이터를 받아오는 처리를 수행하는 노드를 Source Node라고 한다. Kafka Streams에는 세 가지 유형의 데이터 받아오는 패턴이 있다. 자세한 내용은 DSL 섹션에서 설명하겠다. 위의 샘플 코드의 DSL에는 stream가 그에 해당한다.
Processor Node
Source Node에서 받은 데이터를 실제로 처리하는 노드를 가리킨다. 실제로 개발자가 구현하는 것은 거의 이 노드가 된다. Processor Node는 여러개를 연결할 수 있다. 처리 과정을 분할하는 것으로 보기 좋게 구현할 수 있다. 위의 샘플 코드의 DSL 에서는 peek와 mapValues가 이에 해당된다.
Sink Node
다른 Kafka 토픽에 데이터를 전송하는 처리를 수행하는 노드를 가리킨다. 위의 샘플 코드의 DSL은 to가 이에 해당한다.
이와 같이 Source Node가 어떠한 토픽으로부터 데이터를 받아와 Processor Node로 어떠한 처리를 실시하여 데이터를 가공하거나 일시적으로 보존하거나 다른 데이터 스토어에 저장하거나, 필요하다면 그 데이터를 또 다른 토픽으로 내보내어 다른 처리에 연결해 간다. Kafka Streams 응용 프로그램은 이렇게 구축된다.
Task
Kafka Streams는 당연히 여러 머신에서 분산 처리를 할 수 있도록 설계되어 있다. Kafka Streams에는 서브 토폴로지가 polling 대상으로 하는 소스 토픽의 파티션 수에 해당하는 작업(Task)라는 단위로 클라이언트에 처리를 할당한다.
예를 들어, 토폴로지 A에 서브 토폴로지 A-1과 서브 토폴로지 A-2가 있고, 서브 토폴로지 A-1가 토픽 B-1을 서브 토폴로지 A-2가 토픽 B-2를 참조한다고 가정한다. 이 때 토픽 B-1의 파티션 수가 8이고 토픽 B-2의 파티션 수가 10이면, 1_0 ~ 1_7이라는 태스크와 2_0 ~ 2_10이라는 태스크가 작성된다. 태스크의 총 수는 18이다. 이 18개의 작업을 현재 Consumer Group에 속한 클라이언트에 할당한다. 할당 전략에는 몇 가지 패턴이 있지만 이러한 동작에 대한 자세한 내용은 다음 번부터 설명하겠다.
DSL
위에서 설명한 토폴로지를 쉽게 구축하기 위해 Kafka Streams는 편리한 DSL을 제공한다. DSL을 사용하면, Lambda를 메서드 체인으로 연결하는 인터페이스로 스트림 응용 프로그램을 쉽게 작성할 수 있다.
이에 관해서는 전체를 알고 싶다면 공식 문서을 참조하여라.
이후에는 중요한 DSL에 대해서만 설명하도록 하겠다.
KStream, KTable, GlobalKTable
Kafka Streams의 DSL에는 토픽에서 데이터를 받아오는 방법으로 세 가지 패턴을 제공한다. 이 3가지 입력을 나타내는 객체에 대해 메서드 호출을 연결하는 것으로 DSL을 설명한다.
KStream
간단한 Kafka 토픽의 입력 스트림을 가리킨다.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Long> wordCounts = builder.stream(
"word-counts-input-topic", /* input topic */
Consumed.with(
Serdes.String(), /* key serde */
Serdes.Long() /* value serde */
);
이와 같이 입력을 할 때에 Serde(Serializer/Deserializer)를 지정한다. (실제 입력에서는 Deserializer만 이용되지 않는다.)
이 Serde를 통해 Kafka Streams는 Java 객체와 바이트 배열을 자동으로 변환한다.
KTable, GlobalKTable
테이블과 같이 취급할 수 있는 입력 스트림을 가리킨다. 테이블처럼 취급할 수 있다는 것은 로드 시작부터 현재에 이르기까지 Kafka Broker에 입력된 모든 레코드를 로컬로 유지하고 있어 다른 스트림과 결합하거나 KVS처럼 사용할 수 있음을 의미한다.
이는 입력 레코드의 상태를 보관 유지하고 있는 것이고, KTable를 사용하는 것은 Stateful인 어플리케이션이다.
KTable은 각 파티션의 내용이 할당된 클라이언트에만 유지되지만, GlobalKTable은 모든 노드가 한 항목의 모든 파티션의 데이터를 계속 유지된다. 따라서 입력 토픽의 데이터 양을 주의해서 활용해야 한다.
GlobalKTable<String, Long> wordCounts = builder.globalTable(
"word-counts-input-topic",
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(
"word-counts-global-store" /* table/store name */)
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Long()) /* value serde */
);
KTable에는 저장소 이름과 저장할 데이터의 Serde가 필요하다. 이 저장소 이름을 사용하면 각 노드에 RocksDB 데이터베이스 파일이 만들어지고 여기에 데이터가 모인다. 이 데이터 스토어를 StateStore라고 한다. 위에 예이 있는 Materialized.as라는 메서드를 이용해 스토어명이나 Serde를 전환하거나, 그 외 인수의 건네주는 방법으로 인메모리의 데이터 스토어를 사용하도록 변경하는 것도 가능하다.
StateStore에 보존된 데이터는 (인메모리 스토어가 아닌 한) 프로세스가 재기동해도 유지되지만, 파티션의 할당이 바뀌어 담당하는 태스크가 전환되면 불필요해 지거나, 새롭게 재작성이 필요하게 될 수 있다. 더 이상 필요하지 않은 RocksDB 데이터는 일정 기간 후에 자동으로 삭제된다.
GroupBy, GroupByKey
KStream이나 KTable을 집계하고 싶을 때, 어느 키를 기본으로 집계할지를 지정하는 DSL이다. count 또는 aggregate의 전제로 호출해야 한다.
KGroupedStream<String, String> groupedStream = stream.groupBy(
(key, value) -> value,
Grouped.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.String()) /* value */
);
groupBy를 이용하면 반드시 데이터의 재 파티션이 이루어 진다. 재 파티션은, 재 파티션용의 토픽이 자동으로 생성되고 해당 토픽으로 레코드를 전송하여 다시 받아오는 처리를 한다. 네트워크 및 스토리지에 중복 부하가 걸리므로 재 파티션 은 최대한 피해야 한다.
재 파티셔닝을 피하려면 groupByKey를 사용한다.
KGroupedStream<String, String> groupedStream = stream.groupByKey(
Grouped.with(
Serdes.String, /* key */
Serdes.String()) /* value */
);
groupByKey는 현재 키를 그대로 사용하여 그룹화를 지정한다. 이 경우는 처리의 과정에서 키가 변경되지 않으면, 재 파티션은 수행되지 않는다. map 등의 변환 처리에 의해 키가 변경되고 있는 경우에는 groupByKey를 사용해도 재 파티션이 실행되어 버린다.
aggregate
DSL 중에서 가장 범용적인 집계 처리를 구현할 수 있는 DSL이다. 이니셜(initial)의 값을 생성하는 이니셜라이저(initialize), 새롭게 레코드가 도착했을 때에 실행되는 가산기(adder), 변경전의 레코드의 정보를 이용해 실행되는 서브 트랙터(subtractor, 옵션)의 3개의 람다를 건네주어 집계 처리를 구현한다.
KTable<byte[], Long> aggregatedTable = groupedTable.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue.length(), /* adder */
(aggKey, oldValue, aggValue) -> aggValue - oldValue.length(), /* subtractor */
Materialized.as("aggregated-table-store") /* state store name */
.withValueSerde(Serdes.Long()) /* serde for aggregate value */
);
집계 결과를 처리 노드의 로컬에 계속 유지하고 있지 않으면, 다음의 레코드가 도착했을 때에 현재의 집계치가 무엇인가 알 수 없다. 따라서 집계 처리는 필연적으로 KTable가 있어야 한다. 집계된 결과는 DSL 이 자동으로 구축한 StateStore에 저장되고 유지된다.
StateStore의 실태에 대해서는 여러가지 알아야 하는 하는 요소가 있기 때문에, 이 후에 정리해 설명하도록 하겠다. 우선 결과가 StateStore라는 위치에 저장된다는 것을 기억하자.
windowedBy
일정 시간마다 집계 범위를 구분할 수 있는 DSL이다. 이 기능을 사용하면 5분마다 합계를 계속 계산하거나, 한 번의 세션에 포함된 이벤트 수를 세는 등의 작업을 할 수 있다. window 처리는 시간축에 의존하는 처리이므로, 레코드의 타임 스탬프와 보존 기간이 중요하다. 경우에 따라 오래된 타임 스탬프의 레코드가 늦게 도착할 수 있으며 오래된 집계 데이터를 언제든지 보유하면 데이터가 무한히 증가하여 스토리지를 압박하게 된다. 이러한 상황에 대응하기 위해 window 처리에는 보관 기간을 별도로 설정할 수 있도록 되어 있다.
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
윈도우 처리에는 그 구분 방법에 따라 Tumbling Window, Sliding Window, Hopping Window, Session Window와 현재 4가지 종류가 있다. 비교적 복잡하기 해서 자세한 내용은 confluent 문서를 참고하길 바란다.
Processor API
Kafka Streams의 low level API 에 해당하는 것으로, 위에 DSL 은 모두 이 Processor API 로 구현되고 있다.
간단히 말해 Processor API 는 단순한 클래스 정의로 사용할 수 있다. init 메서드 ProcessorContext라는 객체가 주어지므로 이를 이용하여 Kafka Streams 정보를 얻고, StateStore에 대한 참조를 하거나 하여 후속 처리에 데이터를 보낼 수 있다. 자세한 내용은 confluent 문서을 참조하여라.
처리의 실태는 process 메서드에 구현하게 되고 있어, 레코드가 도착하게 될때마다 이 처리가 호출된다. 또한 일정 시간마다 스케줄 처리를 할 수도 있다. ProcessorContextl#schedule 메서드에서 Punctuator라는 처리를 등록하여 일정 기간마다 자동으로 실행할 수 있다. 실행 간격의 타임 스탬프를 처리하는 방법에 대해 Kafka Streams는 STREAM_TIME과 WALL_CLOCK_TIME의 두 가지 유형을 제공한다. 각각의 차이에 대해서는 위에 링크에 상세 내용을 참조하여라.
다음은 위 문서에서 인용한 코드 샘플이다. 중요한 부분은 StateStore를 받아오는 부분, 스케줄 처리를 등록하는 부분, 그리고 context.forward를 호출하여 이후에 레코드를 전달하는 부분이다.
public class WordCountProcessor implements Processor<String, String, String, String> {
private KeyValueStore<String, Integer> kvStore;
@Override
public void init(final ProcessorContext<String, String> context) {
context.schedule(Duration.ofSeconds(1), PunctuationType.STREAM_TIME, timestamp -> {
try (final KeyValueIterator<String, Integer> iter = kvStore.all()) {
while (iter.hasNext()) {
final KeyValue<String, Integer> entry = iter.next();
context.forward(new Record<>(entry.key, entry.value.toString(), timestamp));
}
}
});
kvStore = context.getStateStore("Counts");
}
@Override
public void process(final Record<String, String> record) {
final String[] words = record.value().toLowerCase(Locale.getDefault()).split("\\W+");
for (final String word : words) {
final Integer oldValue = kvStore.get(word);
if (oldValue == null) {
kvStore.put(word, 1);
} else {
kvStore.put(word, oldValue + 1);
}
}
}
@Override
public void close() {
// close any resources managed by this processor
// Note: Do not close any StateStores as these are managed by the library
}
}
이를 Kafka Streams 안에 넣으려면, Topology 클래스의 생성자 또는 StreamBuilder#build에서 생성된 topology에 대해 Topology#addProcessor를 호출하여 모든 Processor 클래스를 지정할 수 있다. 또, 이 때 이용하고 싶은 StateStore가 있으면 그 이름을 넘겨 지정한다. 그렇지 않으면 Processor API에서 StateStore를 찾을 수 없다. 이 경우 예외가 발생한다.
Topology builder = new Topology();
// add the source processor node that takes Kafka topic "source-topic" as input
builder.addSource("Source", "source-topic")
// add the WordCountProcessor node which takes the source processor as its upstream processor
.addProcessor("Process", () -> new WordCountProcessor(), "Source")
// add the count store associated with the WordCountProcessor processor
.addStateStore(countStoreSupplier, "Process")
// add the sink processor node that takes Kafka topic "sink-topic" as output
// and the WordCountProcessor node as its upstream processor
.addSink("Sink", "sink-topic", "Process");
StateStore의 실태
공식적으로 제공되고 있는 StateStore는 크게 나누어 RocksDB를 이용한 persistent 스토어와 프로세스가 종료하면 없어지는 휘발성 인메모리 스토어의 2가지 종류가 있는데, 일반적으로 자주 사용되는 것은 persistent 스토어으로 생각된다. 우선 공통의 요소에 대해 설명하도로 하겠다. 덧붙여서, API의 형식에 따라 자체 구현을 하면, 독자적인 StateStore를 정의하는 것도 가능하다.
StateStore를 low level API 로 이용하는 경우는 스스로 StateStore를 구축할 수 있다.
// Creating a persistent key-value store:
// here, we create a `KeyValueStore<String, Long>` named "persistent-counts".
import org.apache.kafka.streams.processor.StateStoreSupplier;
import org.apache.kafka.streams.state.StoreBuilder;
import org.apache.kafka.streams.state.Stores;
StoreBuilder countStoreBuilder =
Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("persistent-counts"),
Serdes.String(),
Serdes.Long()
);
이는 Processor API 로 이용하고 싶을 때에는 다음과 같은 형태로 이용한다.
KeyValueStore<String, Long> counterStore = context.getStateStore("persistent-counts");
long count = counterStore.fetch("key");
count++;
counterStore.put("key", count);
이 예에서는 간단한 키의 완전 일치되는 경우를 받아오고 있지만, Kafka Streams가 제공하고 있는 StateStore는 키의 바이트열로 정렬 되고 있기 때문에, range 메서드를 사용해 일정한 범위의 키를 얻을 수도 있다.
StateStore에서 중요한 요소는 다음과 같다.
- KVS이며, 키 순서로 정렬된다.
- 키와 값 모두 실제로 저장되는 값은 바이트 열이며, 애플리케이션과 상호 작용할 때 Serialize/Deserialize를 수행한다.
- changelog 토픽을 이용하여 내구성을 보증한다.
- 읽고 쓰기에 대한 cache의 메커니즘을 가지고 있다.
changelog 토픽
앞에서 가볍게 다뤘지만, StateStore를 사용하면 자동으로 changelog 토픽이라는 것이 Kafka Broker에 작성된다. (인메모리 스토어의 경우는 디폴트 무효)
changelog 토픽는 StateStore에 작성된 변경 사항을 보유하는 토픽이다. StateStore에 데이터가 쓰여지거나 삭제되거나 (null을 넣거나) 할 때마다 changelog 토픽에 레코드가 전송된다.
Kafka Streams에는 이 changelog 토픽를 사용하여 처리 노드 다운 및 태스크 재할당에 대응한다.
Kafka Streams 프로세스가 새로 시작되면, 응용 프로그램이 StateStore를 사용하도록 정의되어 있고, 로컬 저장소에 StateStore 데이터가 없으면 Kafka Streams가 복원 처리를 수행하여 Kafka Broker에 존재한다. changelog 토픽에서 모든 레코드를 검색 하고 로컬 StateStore를 복원한다.
마찬가지로 노드의 증감에 의해 리밸런스가 실행되어 태스크가 재할당되었을 때에도, 자신의 로컬에 할당할 수 있었던 태스크 ID에 대응하는 StateStore가 존재하지 않는 경우, 우선 레스토어 처리가 실행되고 나서 처리가 계속 된다.
Kafka Broker는 production에서 운용하는 경우 보통이면 3개 이상의 복제본을 갖도록 설정되어 있으며, 데이터 자체의 내결함성은 Kafka Broker의 기능에 의해 보장되도록 되어 있다.
복원(restore) 처리의 주의 사항
StateStore를 활용할 때 가장 주의해야 하는 것은 복원 처리이다.
Kafka Streams는 Restore이 필요할 때 처리를 중지한다. 처리가 시작 및 재개되는 것은 복원 처리가 완료된 후이다. 즉, StateStore에 쌓여 있는 데이터량이 매우 많아지면, Restore 처리에 걸리는 시간도 장기화되어, 막상 노드가 다운하거나 증감할 때에 긴 시간 처리가 정지하는 위험이 생긴다.
이를 피하는 것은 현재 매우 어려운 문제이다. 일정 이상 낡은 데이터나 이용 빈도가 낮은 데이터는 네트워크의 오버헤드를 허용해 외부 스토어에 놓치는 등, 데이터량을 삭감하는 구조를 얽히게 쌓을 수 밖에 없다.
changelog 비활성화
StateStore를 만들 었을 때, StoreBuilder의 withLoggingDisabled()를 호출하면 changelog 와의 관계를 무효화 할 수 있다. 인메모리 스토어의 경우 기본적으로 비활성화되어 있다.
changelog 토픽이 사용 불가능하면 복원 처리가 수행되지 않는다. RocksDB 스토어를 사용하는 경우, 동일한 노드에서 동일한 ID의 태스크가 실행되는 한 데이터가 계속 유지된다. 한편, Consumer의 리밸런스에 의해 태스크의 재배치가 행해졌을 경우나 처리 노드가 다운되어 복귀 불가능하게 되었을 경우는 그 데이터는 소멸된다.
주요 용도는 로컬 캐시이다. 메모리를 극복하지 않는 양이라도 파일 시스템을 이용해 노드 로컬의 캐시로서 이용할 수가 있다.
예를 들어, 불변의 데이터이면 외부의 데이터 스토어에 축적해 두고, 최초의 한번은 네트워크 액세스의 오버헤드가 발생하지만, 그 후에는 로컬의 파일 시스템에 캐시되어 네트워크를 경유한 액세스를 회피 하는 등의 용도로 이용할 수 있다.
StateStore 캐시
스트림 처리는 그 특징상 단기간에 같은 키의 데이터를 몇번이나 읽고 쓰기할 가능성이 높은 것이다. 예를 들어, user_id의 링크를 통해서 숫자 등을 계산하는 경우, 해당 이벤트 레코드가 집중되어 아무 것도 도착하지 않을 수 있다. 이런 상황에서 매번 스토리지에 데이터를 쓰고 changelog 토픽을 변경하는 것은 쓸모없는 오버헤드로 이어질 수 있다.
Kafka Streams에서는 이를 피하기 위해 캐시가 기본적으로 활성화되어 있다. 기입한 내용은 일정 기간 메모리에 유지되어 flush 타이밍으로 실제의 StateStore에 기입 changelog 를 갱신한다.
DSL로 구축된 KTable에서는 이 캐시 기능을 이용하여 forward가 지연된다. 예를 들어 aggregate에서 집계된 결과를 다음 DSL 에서 사용하거나 다른 주제로 보낼 때 기본 동작은 일정 기간 동안 StateStore에 캐시되어 버퍼링된다. 일정 시간이 지나거나 캐시를 위한 메모리 공간을 소모하면 CacheFlushListener가 레코드를 다음 프로세서로 전달된다.
WindowStore의 실태
방금 DSL 설명에서 windowBy라는 DSL에 대해 소개하였다. 이 DSL 을 이용함으로써 일정 시간 윈도우마다 레코드를 집계할 수 있다.
사실 이것은 WindowStore라는 StateStore의 변형에 의해 구현된다. WindowStore를 작성할 때는 다음과 같다. 1분마다의 윈도우 폭으로, 2시간분의 데이터를 보관 유지하는 WindowStore는 아래와 같이 작성한다.
StoreBuilder<WindowStore<String, Long>> counterStoreByMinute =
Stores.windowStoreBuilder(
Stores.persistentWindowStore(
"counter",
Duration.ofHours(2),
Duration.ofMinutes(1),
false),
Serdes.String(),
Serdes.Long());
이는 Processor API 로 이용하고 싶을 때에는 다음과 같은 형태로 이용한다.
WindowStore<String, Long> counterStoreByMinute = context.getStateStore("counter");
long durationMillis = Duration.ofMinutes(1).toMillis();
long currentWindowStart = (context.timestamp() / durationMillis) * durationMillis;
long count = counterStoreByMinute.fetch("key", windowStart);
count++;
counterStoreByMinute.put("key", count, currentWindowStart);
키-값 스토어에 타임스탬프를 맞춰 부여하는 형태로 취득이나 보존을 실시한다. DSL의 뒷면에 있는 경우는 자동으로 timestamp에서 Time Window를 설정해 주지만, WindowStore를 직접 다루는 경우는, TimeWindow의 개시가 되는 타임 스탬프가 어딘가는 수동으로 산출할 필요가 있다. WindowStore에 미리 주어진 Window Duration은 기록된 타임 스탬프를 기준으로 하여 어느 정도의 윈도우인지를 나타내는데 사용된다.
위의 예제는 매우 단순한 형태이었지만 timestamp의 시작과 끝 시간을 전달하여 해당 범위에 포함된 레코드를 순서대로 검색할 수도 있다. 또한 일반 KeyValueStore와 마찬가지로 키의 범위 탐색과 timestamp의 시작과 종료 시간의 범위 탐색을 조합할 수도 있다.
내부 구현으로서, WindowStore는 복수의 RocksDB의 스토어로 구성되어 있어, 기록하는 타임 스탬프 마다 대략의 segment로 분할되어 있다. 저장할 때 타임 스탬프에서 해당 세그먼트를 식별하고 해당 영역에 데이터를 쓴다. 취득할 때는 대상 범위의 segment에서만 데이터를 취득하는 것으로 검색 범위를 작게 하고 있다. 또한 timestamp의 범위에서 segment를 결정할 수 있기 때문에 현재 처리하고 있는 타임스탬프와 비교해 보존 기한을 지난 것은, 정리해 파일 마다 삭제하는 것으로 간단하게 파기할 수 있다.
기입시에는 레코드에 주어진 키 (위의 예에서는 “key"캐릭터 라인)의 말미에 밀리 세컨드 단위의 unix timestamp가 자동적으로 부여되어 기록된다.