빅데이터 분석 기반이란? 데이터 파이프라인 구축
빅데이터란?
여기서는 빅데이터를 시각화, 분석하는 것을 목표로 한다.
빅 데이터가 소규모(small) 데이터용 소프트웨어(Excel이나 RDB 등)로 처리할 수 없는 이유는 다음과 같이 하드웨어 리소스의 한계가 있기 때문이다.
- CPU 한계: 계산할 데이터가 너무 많아, 업무 시간 내에 처리가 끝나지 않음
- 메모리 한계: 데이터가 너무 많아, 메모리를 극복하지 않으므로 처리할 수 없음
- 스토리지 한계: 데이터가 너무 많아, 스토리지 에 들어갈 수 없기 때문에 처리할 수 없음
그래서 빅데이터를 처리하려면, 병렬 처리가 가능한 소프트웨어를 이용하여 복수의 컴퓨터(의 하드웨어 자원)를 이용해야 한다.
여기에서는 다음 흐름을 따라 빅데이터의 각 용어의 의미/가시화/분석 방법을 설명한다.
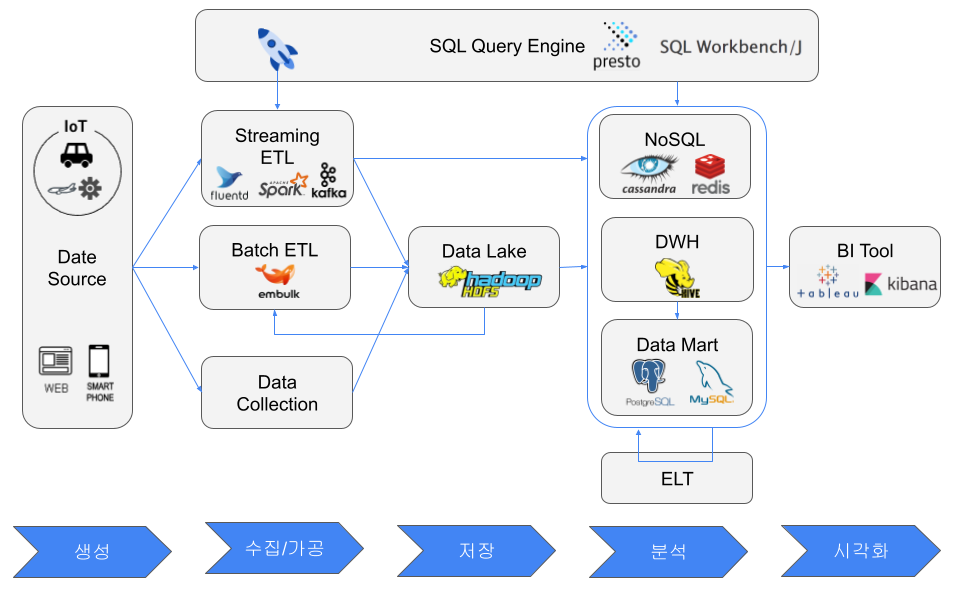
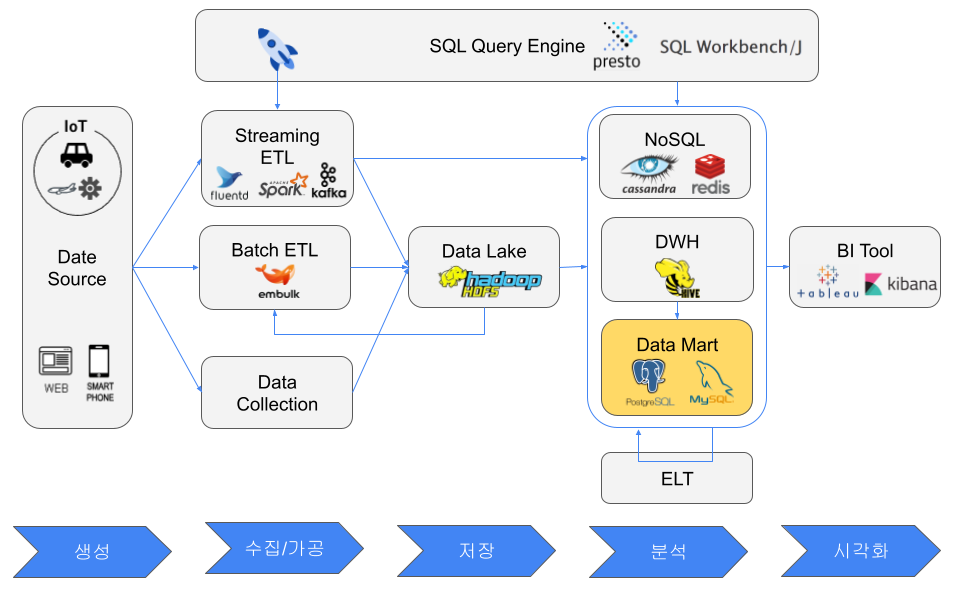
데이터 소스란?
데이터 소스의 구체적인 예는 다음 로그와 테이블 정보이다.
- 웹 서버
- IoT 장비(공장 및 자동차 센서 등)
- 모바일 기기(스마트폰 등)
데이터 소스라는 단어가 가리키는 대상은 서 있는 위치에 따라 달라진다.
(예를 들어, 위 그림의 BI 도구에서 본 데이터 소스는 NoSQL, DWH, 데이터 마트이다.)
또한, 데이터는 다음 세 가지 유형으로 나뉜다.
- 정형(구조화된) 데이터
- 비정형(비구조화된) 데이터
- 반정형(반구조화된) 데이터
정형(구조화된) 데이터란?
정형 데이터의 예
RDB 테이블
정형 데이터의 예는 다음과 같다.
[ID, NAME,DATA] 열을 3행을 가진 데이터
ID,NAME,DATE
1,devkuma,2022/08/01 00:00
2,araikuma,2022/08/02 00:00
3,kimkc,2022/08/03 00:00
특징
- 컴퓨터에서 사용하기 쉽다(RDB + SQL 쿼리로 작업 가능).
- 사전에 미리 행과 열을 정의가 필요하다(고정 스키마).
- 저장에 시간이 많이 걸린다(행, 열의 형태로 데이터를 변환해야 함).
- 각 행은 동일한 열 이름을 가진다.
- 중첩하지 않는다(테이블의 필드 값에 테이블이 포함되지 않음).
- 다른 테이블을 참조하는 경우 JOIN 한다.
비정형(비구조화된) 데이터란?
비정형 데이터의 예
비정형 데이터의 예는 다음과 같다.
- 음악
- 사진
- 텍스트
비정형 데이터의 예는 다음과 같다.
텍스트(액세스 로그)
<6>Feb 28 12:00:00 192.168.0.1 fluentd[11111]: [error] Syslog test
비정형 데이터에는 열 이름이 없으므로 열의 의미를 이해하기가 어렵다.
(위에 텍스트에서의 <6>와 같은 등은 의미를 알 수가 없다.)
특징
- 컴퓨터에서 다루기가 어렵다(예 : 스키마가 없으므로 RDB + SQL 쿼리 로 작업 할 수 없음).
- 행, 열을 정의하지 않아도 된다(스키마리스: schemaless).
- 저장이 쉽다(아무것도 처리하지 않고 그대로 저장).
반정형(반구조화된) 데이터란?
반정형 데이터의 예
비정형 데이터의 예는 다음과 같다. 이 외에도 Parquet, ORC 등이 존재한다.
- JSON
- XML
- AVRO
비정형 데이터를 반정형 데이터로 변환하는 예는 다음과 같다.
비정형 데이터 (변환 전)
비정형 데이터의 예: 텍스트(액세스 로그)
<6>Feb 28 12:00:00 192.168.0.1 fluentd[11111]: [error] Syslog test
반정형 데이터(변환 후) 반정형 데이터의 예: JSON 형식(위에 비정형 데이터의 요소에 속성 이름을 붙인 것임)
{
"jsonPayload": {
"priority": "6",
"host": "192.168.0.1",
"ident": "fluentd",
"pid": "11111",
"message": "[error] Syslog test"
}
}
비구조화 데이터에서는 <6>이 무엇을 나타내는지 몰랐지만, 반구조화 데이터는 속성명이 붙어 있으므로, “6"이 priority인 것을 알 수 있다.
특징
- 속성을 갖기 때문에 컴퓨터가 다루기 쉽다(반정형 데이터에 대한 쿼리 등).
- 사전에 속성 정의가 필요하지 않다(가변 스키마).
- 언제든지 새로운 속성을 추가 가능하다.
- 저장이 조금 편하다(사전에 데이터의 형태를 결정하지 않아도 된다. 나중에 쉽게 속성을 추가할 수 있다).
- 각 행마다 다른 속성을 가질 수 있다.
- 중첩 가능
- 관련 데이터는 중첩되어 포함되므로 JOIN 불필요하다(또는 클라이언트 측에서 JOIN).
정형/비정형/반정형 차이
정형/비정형/반정형의 차이를 정리하면 다음과 같다.
| 정형 | 비정형 | 반정형 | |
|---|---|---|---|
| 테이블 형식 | Yes | No | No (테이블 형식으로 변환 가능) |
| 스키마(행/열/데이터 유형 등) | 고정 스키마 (사전 정의) |
스키마리스 | 가변 스키마 (나중에 속성을 추가 가능) |
| 저장 | 번거롭다 고정 스키마로 변환 |
쉽다 무변환 |
약간 쉽다 가변 스키마로 변환 |
| 쿼리 가능 | 예 | 아니 | 예(해당 DB) |
| 서버측 JOIN | 필요한 데이터가 중첩 불가능 |
- | 불필요한 데이터가 중첩 가능 |
- 고정 스키마는 데이터를 반드시 스키마에 맞추지 않으면 저장할 수 없다.
- 가변 스키마는 나중에 데이터에 맞게 스키마 쪽 속성을 나중에 추가할 수 있다.
데이터 분석의 목표는 쿼리를 사용하여 원하는 데이터를 추출하는 것이다.
따라서, 비정형 데이터를 분석하려면 쿼리를 사용할 수 있도록 정형 데이터 또는 반정형 데이터로 변환해야 한다.
ETL/ELT란?
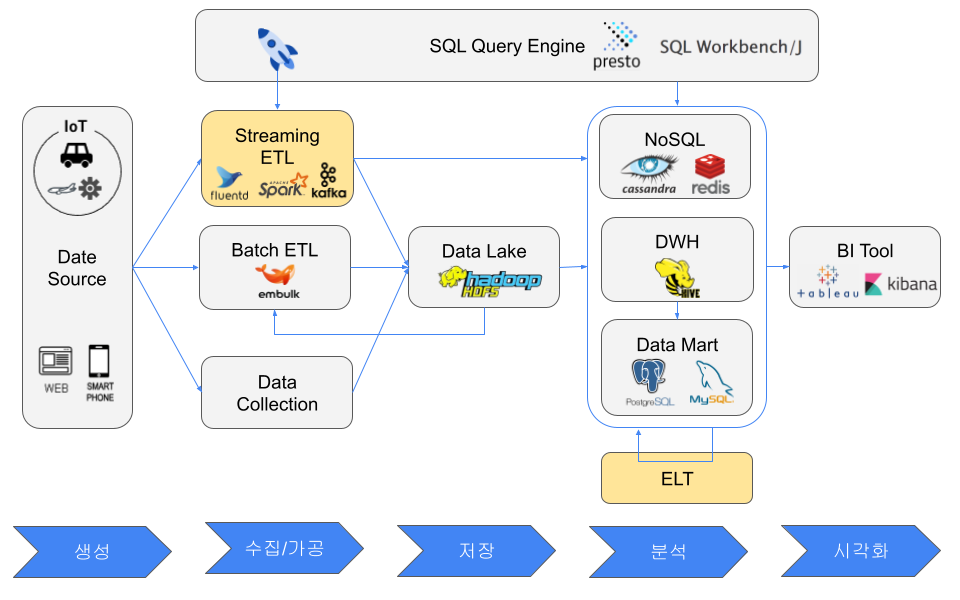
데이터 소스 측에서 가공/변환(Transform) 하지 않는 이유는 다음과 같다.
- 웹 서버 : 운영 서버에 로드를 원하지 않는다.
- IoT 기기: 변환 처리할 수 있을 만큼의 스펙이 없다.
- 모바일 기기: 고객 기기에서 처리할 수 없다.
ETL에는 다음 두 가지 유형이 있다.
- 배치 ETL
- 스트리밍 ETL
| 배치 ETL | 스트리밍 ETL | |
|---|---|---|
| 목적 | 처리량 중시 | 실시간 중시 |
| 처리할 타이밍 | 일정한 간격(매시간, 매일 밤 등) | 데이터가 발생했을 때 |
| 처리에 걸리는 시간 | 몇 분 ~ 몇 시간 | 몇 밀리초 ~ 몇 초 |
| 사용 사례 | 야간 배치 월별 처리 |
실시간성이 필요한 처리 (예: 신용카드의 부정 검출 등) |
Extract(추출)
데이터 소스에서 데이터를 추출하는 소프트웨어는 다음과 같다.
(외부에서 직접 SQL 쿼리나 REST API로 추출하는 방법도 있다.)
| 소프트웨어 | ETL 유형 |
|---|---|
| Embulk | 배치 ETL |
| fluentd | 스트리밍 ETL |
| beats(Elasticsearch) | 스트리밍 ETL |
| Kafka Producer API(Kafka) | 스트리밍 ETL |
스트리밍 ETL에서는 Extract와 Transform 사이에 Pub/Sub 메시징 시스템을 배치할 수 있다.
복수의 수신자에게 같은 메시지를 전달하는 일대다의 출판-구독 모델(Pub-Sub 모델)에 의한 전달에 대응하고 있는 것도 있다.
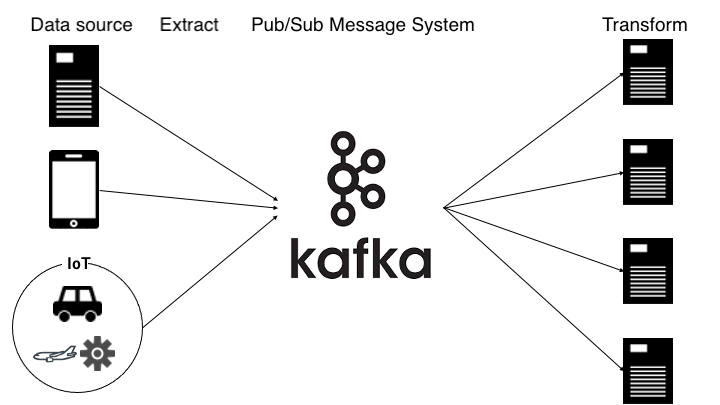
Pub/Sub 메시징 시스템을 설치하는 이유는 다음과 같다.
- 실시간으로 Transform을 완료하기 위해 여러 컴퓨터에 처리를 분산하고 가속화
- 피크(peak)시 급격한 데이터 증가로 인해 Transform이 시간에 맞지 않으면 데이터를 일시적으로 저장
Transform (가공/변환)
추출한 데이터는 주로 다음 소프트웨어로 Transform(가공/변환) 한다.
- SQL 쿼리
- pandas
- fluentd
- logstash (Elasticsearch)
- Kafka Streams (Kafka)
- Spark Streaming (Apache Spark)
Transform은 정형/반정형 데이터로 변환하거나 데이터를 추가/삭제한다.
Load (로드)
Transform 으로 적절한 형태로 변환한 데이터는 주로 이하의 4개의 목적지에 Load 한다.
- NoSQL
- 데이터 레이크
- DWH(데이터 웨어하우스)
- 데이터 마트
데이터 레이크(Data Lake)란?
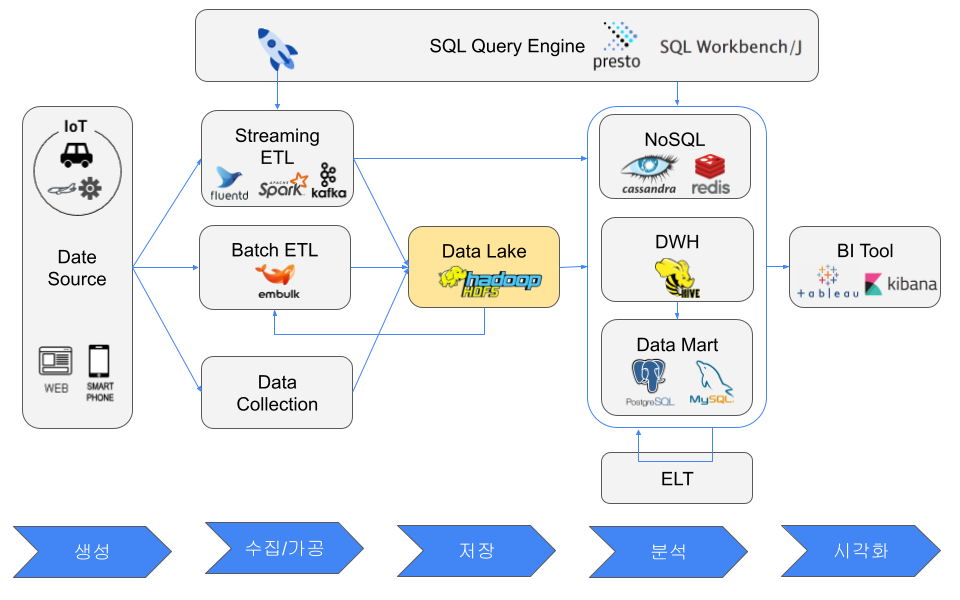
데이터 레이크의 예
데이터 레이크 서비스/소프트웨어 의 예는 다음과 같다.
- Hadoop HDFS
- Amazon S3
데이터 레이크에는 다양한 형식의 데이터를 수 없이 저장해 간다.
따라서, 나중에 용량을 추가할 수 있는 스토리지가 데이터 레이크로 선택된다.
NoSQL 데이터베이스
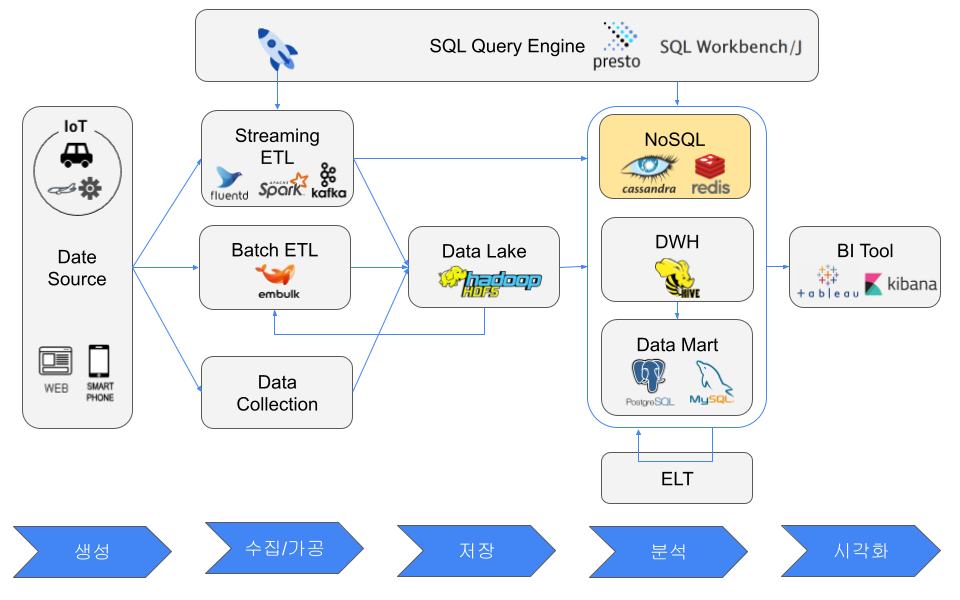
“NoSQL"이라는 이름은 실제로 어떤 기술을 참고한 곳이 아니기에 적절하지 않다. 원래 NoSQL은 2009년 오픈 소스, 분산 환경, 비관계형 데이터베이스 밋업(meetup)용 인기 트위터 해시태그였다.
출처 : 데이터 중심 애플리케이션 설계
NoSQL은 RDB로 부터 어떠한 제약을 풀어, 퍼포먼스를 추구한 데이타베이스이다.
(역으로 말하면, RDB로 만족하는 퍼포먼스가 나오는 경우는 NoSQL는 필요 없을지도 모른다)
NoSQL과 RDB의 차이
NoSQL과 RDB의 차이점은 다음과 같다.
| NoSQL | RDB | |
|---|---|---|
| 용도 | 낮은 대기 시간(고성능) 처리 | 트랜잭션 처리 |
| 데이터 모델 | 비정형 데이터가 많다 (Key-Value, 문서, 그래프 등) |
정형 데이터 (관계형 모델) |
| JOIN | 클라이언트측에서 JOIN 을 추천 서버측은 데이터를 중첩하여 대응 |
서버측에서 JOIN |
| 스키마 | 가변 스키마가 많다 | 고정 스키마 |
| 확장성 | 노드 추가 및 처리 분산 ※노드 = 컴퓨터 |
노드 자체의 성능을 높인다 읽기 전용 복제본 노드 추가 |
이는 어디까지나 경향 이야기이다. 위에서 언급했듯이 NoSQL에는 기술적 정의가 없다.
NoSQL 유형 및 예제
NoSQL의 유명한 데이터 모델 유형은 다음과 같다.
| 데이터 모델 유형 | 설명 | 제품 예 |
|---|---|---|
| Key-Value 캐시 (인 메모리) |
키와 해당 값으로 메모리 에 데이터 관리 (연관 배열, 사전 형식) |
Memcached Redis |
| Key-Value 스토어 | 키와 해당 값으로 스토리지 에 데이터 관리 (연관 배열, 사전 형식) | DynamoDB |
| 와이드 컬럼 스토어 | 테이블, 행, 열로 데이터 관리 (2차원 Key-Value 스토어) RDB 와 달리 행마다 열 이름이 달라도 된다. |
카산드라 HBase |
| 그래프 데이터베이스 | 노드, 에지, 속성으로 데이터 관리 | Neo4j |
| 도큐먼트 저장소 | 반정형 데이터(도큐먼트 지향)로 데이터 관리 | Elasticsearch MongoDB |
https://en.wikipedia.org/wiki/NoSQL
데이터 웨어하우스(DWH)란?
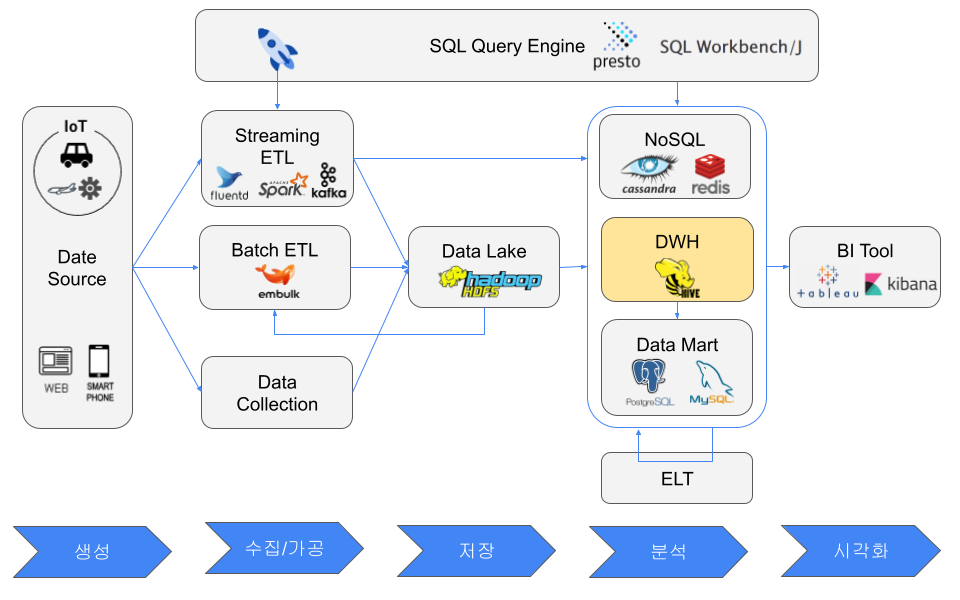
데이터 웨어하우스(DWH)와 RDB의 차이
데이터 웨어하우스(DWH)와 RDB 의 차이점은 다음과 같다.
| 데이터 웨어하우스(DWH) | 관계형 데이터베이스(RDB) | |
|---|---|---|
| 목적 | 분석(OLAP) | 트랜잭션 처리 (OLTP) |
| 스토리지 | 열 지향 스토리지 형식 | 행 지향 스토리지 형식 |
| 데이터 양 | 빅데이터 | 스몰 데이터 |
| 데이터 정규화 | 부분적으로 비정규화 - 스타 스키마 - 눈송이 스키마 |
제3정규형 |
RDB는 데이터 양이 늘어나면 매우 느려진다.
따라서, 대량의 데이터를 분석하려면 데이터 웨어하우스(DWH)를 사용한다.
(역으로 말하면, 고속으로 분석할 수 있는 스몰 데이터의 경우는 RDB이면 된다.)
열 지향 데이터베이스(Columnar Database)란?
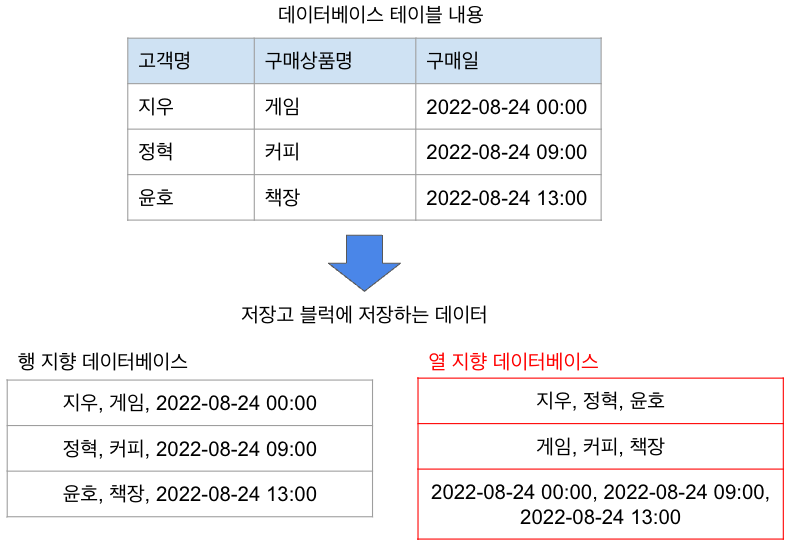
열 지향 데이터베이스는 다음 파일 형식(열 지향 저장소 형식)으로 데이터를 저장한다.
- ORC
- Parquet
또, 열 지향 데이터베이스(열 지향 스토리지 형식)의 아래와 같이 3가지 특징이 있다.
- 분석시 읽기 효율이 좋다.
- 쓰기 효율이 떨어진다.
- 압축률이 좋다.
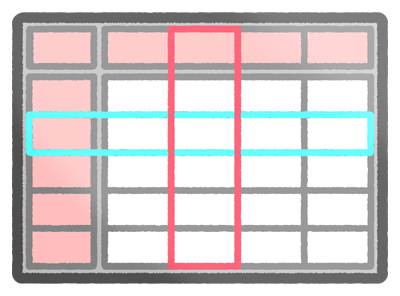
분석시 읽기 효율이 좋다.
열 지향 데이터베이스에서는 불필요한 열을 읽을 수 있으므로 읽기 효율이 좋아진다.
데이터 분석에는 열(column)만 필요한 경우가 많다.
예를 들어, 다음 테이블에서 주문 피크 시간을 분석하려는 경우에는 ‘구매일’ 컬럼만 집계 하면 되며 전체 테이블을 로드할 필요가 없다.
색인은 하나의 열로 설정되지만, 분석에서는 색인이 없는 열을 사용할 수 있다.
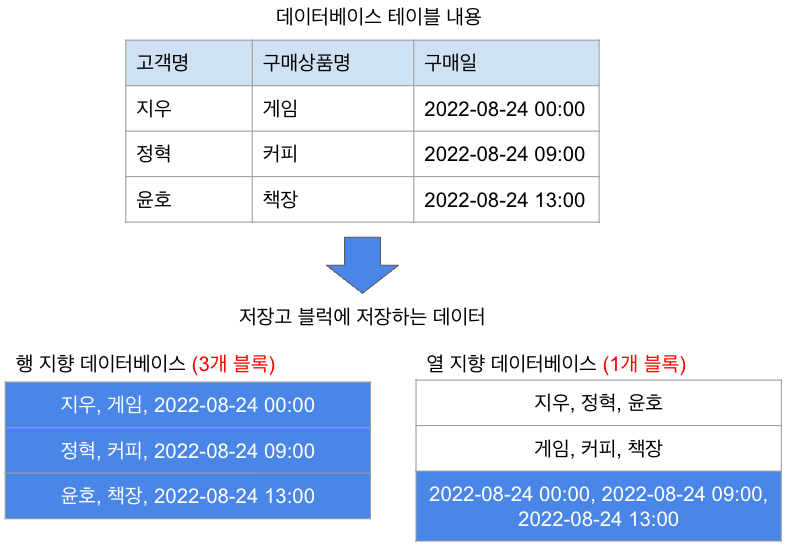
위의 예제에서 열 지향 데이터베이스를 사용하면 블록 읽기를 1/3로 줄일 수 있다.
쓰기 효율이 떨어진다.
열 지향 데이터베이스에서는 쓰기 블록을 찾아야 하므로 쓰기 효율이 떨어진다.
각 데이터베이스를 작성하는 절차는 다음과 같다.
-
열 지향 데이터베이스
- 쓸 블록 찾는다.
- 열의 내용을 추가한다.
- 모든 열에 대해 1과 2을 반복한다.
-
행 지향 데이터베이스
- 가장 마지막 블록에 넣는다.
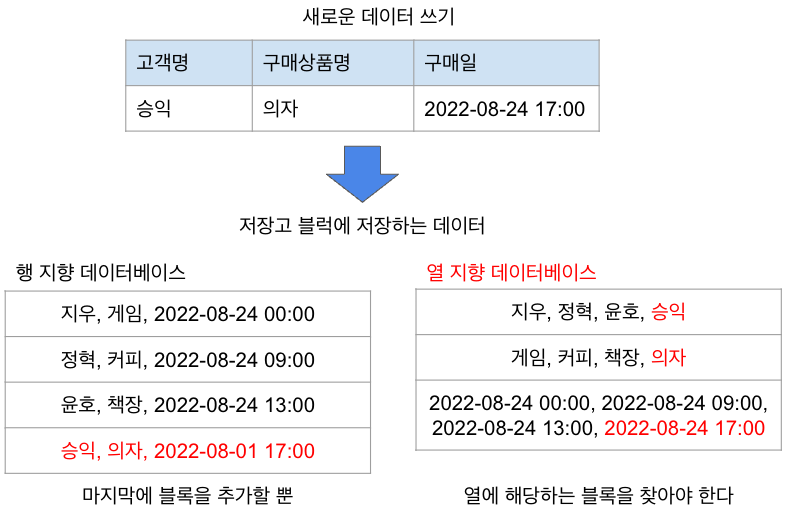
쓰기에 대해서는 행 지향 데이터베이스가 효율이 더 좋다는 것을 알 수 있다.
압축률이 좋다.
동일한 컬럼은 동일한 데이터 유형을 포함하므로, 컬럼 지향 데이터베이스의 압축률이 향상된다.
예를 들어, ‘구매수’ 열에서 같은 숫자가 계속되기 쉽다. 이 경우 압축 효율이 좋아진다.
압축 이미지
압축률이 좋으면 한번에 스토리지 액세스로 많은 데이터를 읽을 수 있다.
데이터 웨어하우스(DWH) 예제
데이터 웨어하우스(DWH)의 특정 소프트웨어 및 서비스는 다음과 같다.
데이터 웨어하우스(DWH)와 데이터레이크의 차이
| 데이터 웨어하우스(DWH) | 데이터레이크 | |
|---|---|---|
| 목적 | “지금” 데이터를 가장 빠르게 분석 | “미래"에 이용할 데이터를 모으기 |
| 데이터 형식 | 정형/반정형 | 모두(정형/비정형/반정형) |
| 저장 | 번거롭다(구조화 된 데이터로 변환) | 쉽다(무변환으로 저장) |
| 분석/추출 | 빠르다 | 느리다(정형화되어 있지 않기 때문에) |
| 새로운 요구 분석 | 불가능(스키마 이외의 데이터 버림) | 가능(모든 데이터 포함) |
| 용량 | 제한 있음 | 무제한 |
데이터 마트(Data Mart)란?
데이터 마트와 데이터 웨어하우스(DWH)의 차이
데이터 웨어하우스의 규모가 작아진 것이 데이터 마트라고 할 수 있다.
| 데이터 마트 | 데이터 웨어하우스 | |
|---|---|---|
| 목적 | 필요한 데이터만 분석 | 모든 데이터 분석 |
| 범위 | 단일 부서 | 모든 부서 |
| 사이즈 | 소형 데이터(100GB 미만) | 빅데이터(100GB 이상) |
| 소량의 데이터 분석 | 능숙하다(고속) | 능숙하지 못하다(저속) |
| 대량의 데이터 분석 | 능숙하지 못하다(저속) | 능숙하다(고속) |
빅데이터의 크기는 2022년 시점에서의 기준
메모리에 모든 데이터가 올라오게 되면 로컬 호스트 1대로 처리하는 것이 가장 빠르다. (노드간 통신이나 결과를 병합하는 지연 시간(Latency)이 발생하기 때문)
따라서, 분석 속도를 높이기 위해 데이터 웨어하우스에서 필요한 데이터만 데이터 마트로 이동한다.
데이터 마트의 예
데이터 마트의 예는 다음을 포함한다.
- RDB
- DWH의 클러스터 규모가 작은 것(RDB 권장)
- CSV 파일
위에서 볼 수 있듯이 규모가 작고 분석 가능한 데이터 저장소를 나타낸다.
SQL 쿼리 엔진이란?
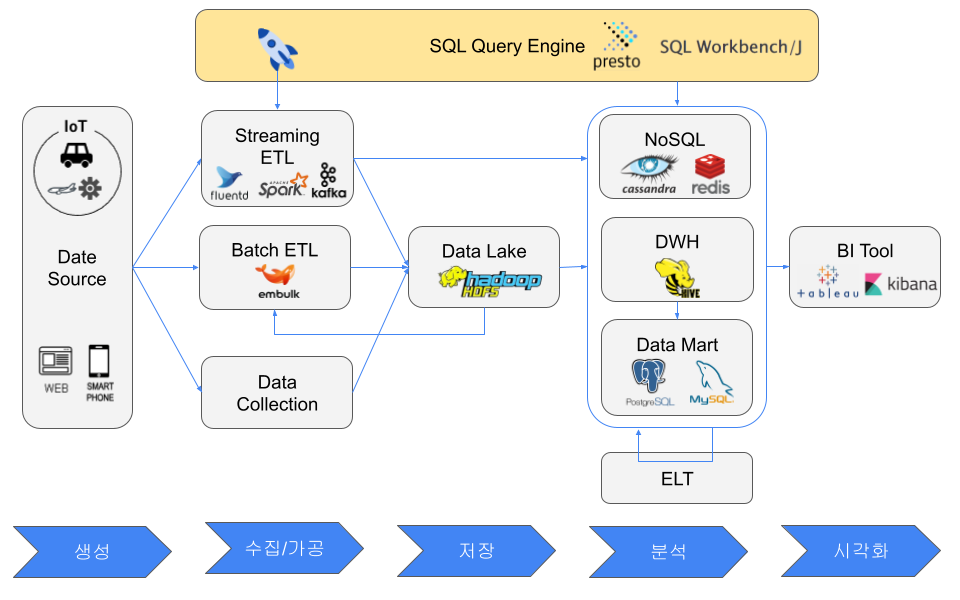
“프로그래밍하지 않고 더 쉽게 데이터를 조작하고 싶다"는 요구에서 SQL 쿼리 엔진이 탄생했다.
SQL 쿼리 엔진의 예
SQL 쿼리 엔진의 특정 소프트웨어 및 서비스는 다음과 같다.
- ETL
- ksql DB (Kafka)
- Apache Flink SQL
- NoSQL
- Elasticsearch SQL
- PartiQL (Dynamo DB)
- 데이터 레이크
- Presto
- Apache Hive
- 데이터 웨어하우스
- SQL Workbench/J
- DBeaver
BI(Business Intelligence) 도구
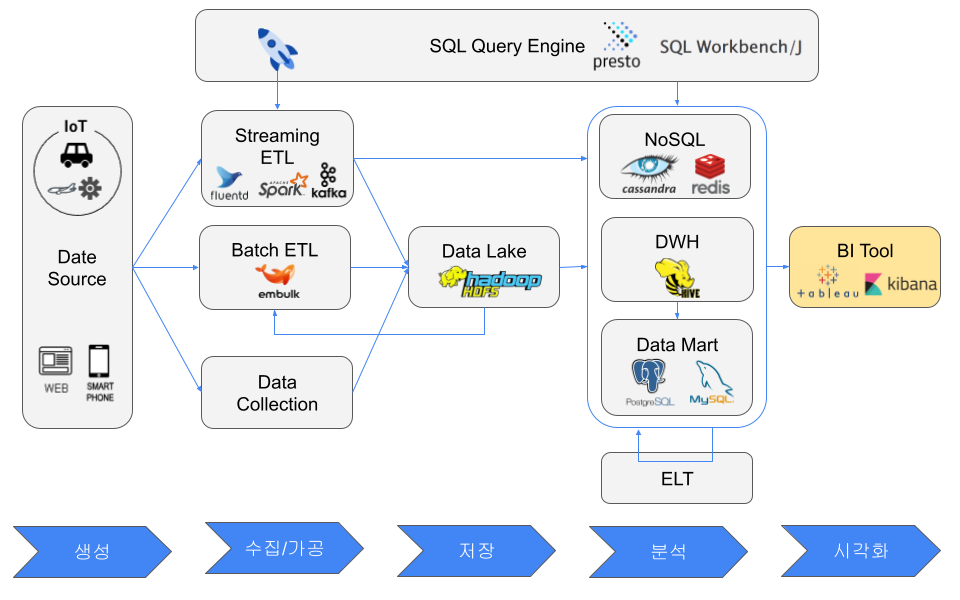
BI 도구의 예
대표적인 BI 도구는 다음과 같다.
- Tableau
- Grafana
- Kibana(Elasticsearch)
- QuickSight
데이터스토어 요약
RDB 와 빅데이터 분석 기반에서 자주 이용되는 데이터스토어의 차이를 표로 정리하면 아래와 같다.
| RDB | NoSQL | DWH | 데이터 레이크 | |
|---|---|---|---|---|
| OSS/서비스 | Oracle MySQL PostgreSQL |
Elasticsearch Cassandra Redis snowflake HIVE Amazon Redshift |
hadoop HDFS Amazon S3 |
|
| 목적 | 트랜잭션 (OLTP) |
특정 실적 중시 | 분석(OLAP) | 데이터 저장 |
| 데이터 구조 | 정형화 | 반정형화 | 정형화 반정형화 |
정형화 비정형화 반구조화 |
| 스키마 | 고정 스키마 | 가변 스키마 | 고정 스키마 | 스키마리스 (데이터 카탈로그) |