Kafka Streamsを使ったストリーム処理アプリケーション開発
ストリームプロセシングとは?
イベントストリームに対して、データが到着するたびに処理を行い、それを継続していくアプリケーションを指す。Kafkaのエコシステムでは、Kafka BrokerにConsumerとして接続し、無限ループでpollingを実行して、データが到着するたびに短い間隔で処理を行うアプリケーションである。
複数のRecordを使って集計処理を行う場合もあるが、一定期間ごとに集計単位を区切って1件ごとに集計結果を更新したり、バッファリングして一定間隔でまとめて処理したりする形式である。
StatelessまたはStateful
ストリームプロセシングの処理内容は、大きくStatelessとStatefulに分けられる。
Stateless処理とは、あるイベントRecordが到着したとき、そのRecordだけで処理が完了する処理をいう。Record AをRecord Bの形に変換して、別のTopicや別のデータストアへ送信する処理などが一般的である。
一方、Statefulな処理とは、到着したイベントRecordやそれをもとに生成したデータを一定期間保持し、それらを組み合わせて結果を生成する処理をいう。一般的にはイベント数を集計して合計、平均、ヒストグラムを算出したり、処理効率のためにバッファリングしてまとめて処理したり、他のStreamやデータストアと結合してデータ品質を高めたりする処理が挙げられる。
Statefulな処理では、一定量のRecordを保存しておくデータストアが別途必要になる。これをStateStoreと呼ぶ。ストリームプロセシングにおけるStateStoreには重要な検討ポイントがいくつかあり、後で説明する。
StatefulアプリケーションのState Store
ストリームプロセシングでは、データが到達するとそのたびに処理が行われるため、何らかのデータストアを利用する場合は、データが来るたびに取得や保存を行う必要がある。
そのため、重要な要素として低レイテンシが求められる。データ量によってはRedisのような単純で高速なKVSでもネットワークレイテンシが発生するため、十分とはいえない場合がある。
そこでストリームプロセシングでは、基本的に各処理ノードのローカルにデータストアを保持し、レイテンシを低く保つ方法を採用する。
後で説明するKafka StreamsやApache FlinkなどのストリームプロセシングフレームワークではRocksDBが使われている。RocksDBはアプリケーションに組み込まれるKVS型で、各ノードのローカルでRocksDBを動かして低レイテンシを維持する。
各ノードのローカルで動かすということは、ノードが意図しない障害でダウンして復旧不能になるとデータが失われる危険があることを意味する。これを避けるため、ノードに依存しないデータ永続化メカニズムも別途必要になる。この構造ではネットワーク通信のオーバーヘッドが避けられないため、ある程度のバッファリングが必要である。
またKafkaを利用したストリーミングアプリケーションでは、拡張性を保証するためにアプリケーションを分散し、複数ノードで実行できる。この場合、ノード数の増減に応じて処理するPartitionの割り当てが変わる可能性がある。前章で説明したように、Kafka Consumerでは同じConsumer Group内で1つのPartitionを処理できるクライアントは1つだけである。台数が増減すると割り当てが再配置されるため、処理対象が別ノードへ移動することを考慮しなければならない。処理が別ノードへ移動したとき、それまで各ノードのローカルに保持していたデータを、新しく処理が割り当てられたノードへ何らかの形で移さなければ、それまで保持していたStateStoreのデータを利用できなくなる。たとえばノードが増えた瞬間に集計カウントが突然0に戻ることがある。これを避けるため、処理ノードの切り替えに合わせてStateStoreを再配置するメカニズムが必須である。
Kafka Streamsとは?
Kafka StreamsはApache Kafka開発プロジェクトが公式に提供するストリームプロセシングフレームワークである。Javaで実装されている。
前述のとおり、Statefulなアプリケーションを実装しようとすると、状態管理にはかなり複雑な構造が求められる。Kafka Streamsを使うと、フレームワークがこの複雑さを簡素化してくれる。また、Consumerクライアントのpolling loopや、別TopicへRecordを送信するためのProducerクライアントの構築も複雑になりがちなため、Statelessなアプリケーションでも大幅にコードを簡略化できる。
ここで説明する内容は、Confluentが提供するドキュメントに概ね書かれている。より詳細を知りたい場合は参照するとよい。
cf. Confluent | Streams Concepts
主な特徴
Kafkaの開発で主要な役割を担っているConfluentのドキュメントによると、次の特徴がある。
Powerful
- Makes your applications highly scalable, elastic, distributed, fault-tolerant
- Supports exactly-once processing semantics
- Stateful and stateless processing
- Event-time processing with windowing, joins, aggregations
- Supports Kafka Streams Interactive Queries to unify the worlds of streams and databases
- Choose between a declarative, functional API and a lower-level imperative API for maximum control and flexibility
高機能
- アプリケーションに高い拡張性、弾力性、分散性、耐障害性を実装できる。
- exactly-once処理セマンティクスをサポートする。
- StatefulとStatelessの処理に対応する。
- Window、Join、Aggregationを使ったイベント時間処理に対応する。
- Streamとデータベースを統合するため、Kafka Streams Interactive Queriesをサポートする。
- 高い制御性と柔軟性のため、宣言的な関数型APIと低レベルの命令型APIを選択できる。
Lightweight
- Low barrier to entry
- Equally viable for small, medium, large, and very large use cases
- Smooth path from local development to large-scale production
- No processing cluster required
- No external dependencies other than Kafka
軽量
- 導入のハードルが低い。
- 小規模、中規模、大規模、超大規模のユースケースに対応できる。
- ローカル開発環境から大規模本番環境へ円滑に移行できる。
- 処理クラスターが不要である。
- Kafka以外の外部依存関係がない。
この中でも最も重要だと思われる点は、Kafka以外の外部依存関係がないことである。このような分散処理フレームワークでは、YARNのようなリソースマネージャーや別のデータストアが必要になることも多いが、Kafka Streamsには必要ない。これは導入のハードルを大きく下げる。
Tutorialコード
Kafka Streamsでアプリケーションを作成するには、次のようなコードを書く。公式ドキュメントの引用を少し変更したものである。
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.kstream.StreamsBuilder;
import org.apache.kafka.streams.processor.Topology;
// Use the builders to define the actual processing topology, e.g. to specify
// from which input topics to read, which stream operations (filter, map, etc.)
// should be called, and so on. We will cover this in detail in the subsequent
// sections of this Developer Guide.
StreamsBuilder builder = new StreamsBuilder();
builder
.stream(inputTopic, Consumed.with(stringSerde, stringSerde))
.peek((k,v) -> logger.info("Observed event: {}", v))
.mapValues(s -> s.toUpperCase())
.peek((k,v) -> logger.info("Transformed event: {}", v))
.to(outputTopic, Produced.with(stringSerde, stringSerde));
Topology topology = builder.build();
//
// OR
//
topology.addProcessor(...); // when using the Processor API
// Use the configuration properties to tell your application where the Kafka cluster is,
// which Serializers/Deserializers to use by default, to specify security settings,
// and so on.
Properties props = ...;
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start(); // non blocking
このようにKafka Streamsでは、DSLを連結したり、Processor APIという特定インターフェースの規則に従ってJavaクラスを実装したりするだけで、Kafkaに接続するConsumerやProducerが作成され、処理スレッドの起動なども簡略化できる。
Kafka Streamsアプリケーションモデル
Kafka StreamsはSource Node、Processor Node、Sink Nodeを組み合わせてTopologyという単位を作り、アプリケーションを構築する。それぞれの意味を説明する。
Topology
Topologyという言葉は、本来は数学用語で位相幾何学を表す。数学的な詳細は省くが、物の形状が持つ性質に注目する学問である。そこから派生して、ネットワークトポロジーという、ネットワークグラフがどのような構成をしているかを示す用語がある。Kafka StreamsのTopologyは、このネットワークトポロジーと同じように考えられる。
Kafka Streamsは特定の役割を持つノードを接続してグラフ構造を構築し、Topologyを形成して動作する。このTopologyは2つ以上のサブトポロジーによって形成されることがある。
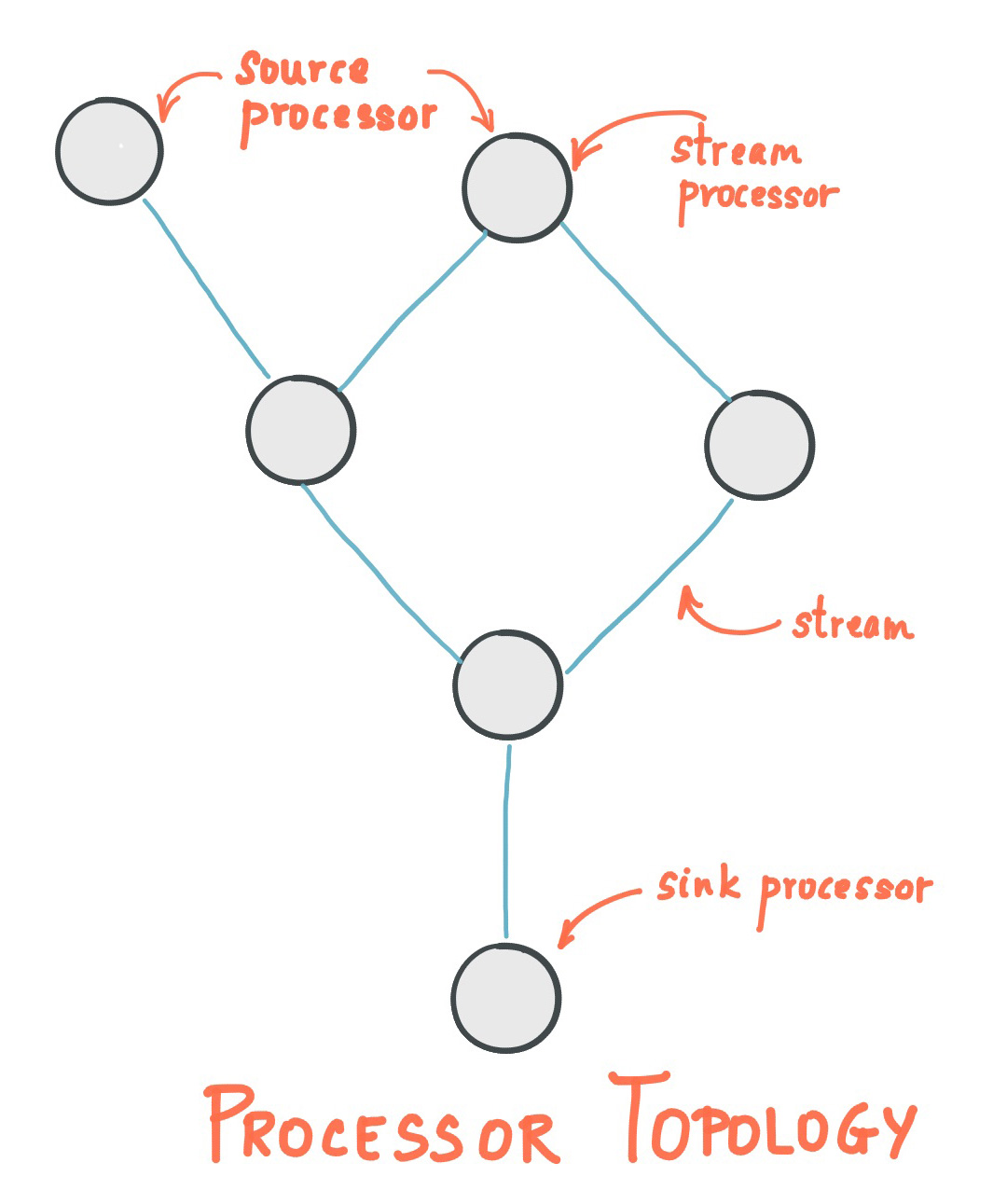
画像:Confluent | Streams Architecture
このようなグラフ構造を1つ以上保持するオブジェクトがKafka StreamsのTopologyである。
2つ以上のサブトポロジーが生成されるかどうかは、アプリケーションがどのように定義されているかによる。1つのアプリケーションが複数のSource Topicからデータを受け取り、それらのSource Topicに依存するProcessor NodeまたはSink Nodeに直接的な依存関係がない場合、複数のサブトポロジーが作られることがある。上の例ではSource Nodeが複数あるが、下のProcessorが両方のSource Nodeに依存しているため、グラフが1つにつながっている。この場合、サブトポロジーは1つである。もし左側のSource Nodeが他の全体と独立し、どこにも接続されていないProcessor Nodeだけに依存している場合は、2つのサブトポロジーになり得る。
Source Node
Kafka Topicからデータを受け取る処理を行うノードをSource Nodeという。Kafka Streamsにはデータを受け取る3種類のパターンがある。詳細はDSLの節で説明する。上のサンプルコードのDSLではstreamが該当する。
Processor Node
Source Nodeから受け取ったデータを実際に処理するノードを指す。開発者が実装するものの多くはこのノードになる。Processor Nodeは複数つなげられる。処理過程を分割することで、見通しよく実装できる。上のサンプルコードのDSLではpeekとmapValuesが該当する。
Sink Node
別のKafka Topicへデータを送信する処理を行うノードを指す。上のサンプルコードのDSLではtoが該当する。
このように、Source NodeがTopicからデータを受け取り、Processor Nodeで処理してデータを加工したり一時的に保持したり別のデータストアに保存したりし、必要であればSink Nodeで別Topicへ出力して次の処理につなげる。Kafka Streamsアプリケーションはこのように構築される。
Task
Kafka Streamsは当然ながら複数マシンで分散処理できるように設計されている。Kafka Streamsでは、サブトポロジーがpolling対象とするSource TopicのPartition数に対応するTaskという単位で、クライアントに処理を割り当てる。
たとえばTopology AにサブトポロジーA-1とA-2があり、A-1がTopic B-1を、A-2がTopic B-2を参照するとする。このときTopic B-1のPartition数が8、Topic B-2のPartition数が10なら、1_0から1_7というTaskと、2_0から2_9というTaskが作成される。Taskの総数は18である。この18個のTaskを現在のConsumer Groupに属するクライアントへ割り当てる。割り当て戦略にはいくつかのパターンがあるが、詳細は次回以降に説明する。
DSL
上で説明したTopologyを簡単に構築するため、Kafka Streamsは便利なDSLを提供している。DSLを使うと、Lambdaをメソッドチェーンでつなぐインターフェースにより、ストリームアプリケーションを簡単に書ける。
全体を知りたい場合は公式ドキュメントを参照するとよい。
以降では重要なDSLだけを説明する。
KStream、KTable、GlobalKTable
Kafka StreamsのDSLでは、Topicからデータを受け取る方法として3つのパターンを提供する。この3つの入力を表すオブジェクトに対してメソッド呼び出しを連結することでDSLを記述する。
KStream
単純なKafka Topicの入力Streamを指す。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Long> wordCounts = builder.stream(
"word-counts-input-topic", /* input topic */
Consumed.with(
Serdes.String(), /* key serde */
Serdes.Long() /* value serde */
);
このように入力時にはSerde(Serializer/Deserializer)を指定する。実際の入力ではDeserializerだけが使われる。
このSerdeを通じて、Kafka StreamsはJavaオブジェクトとバイト配列を自動変換する。
KTable、GlobalKTable
テーブルのように扱える入力Streamを指す。テーブルのように扱えるということは、ロード開始から現在に至るまでKafka Brokerに入力されたすべてのRecordをローカルに保持しており、他のStreamと結合したりKVSのように利用したりできることを意味する。
これは入力Recordの状態を保持しているため、KTableを使うアプリケーションはStatefulである。
KTableは各Partitionの内容が割り当てられたクライアントにだけ保持されるが、GlobalKTableはすべてのノードが1つのTopicの全Partitionデータを保持し続ける。そのため、入力Topicのデータ量には注意して利用する必要がある。
GlobalKTable<String, Long> wordCounts = builder.globalTable(
"word-counts-input-topic",
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(
"word-counts-global-store" /* table/store name */)
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Long()) /* value serde */
);
KTableには保存先名と保存するデータのSerdeが必要である。この保存先名を使って各ノードにRocksDBデータベースファイルが作られ、そこにデータが蓄積される。このデータストアをStateStoreと呼ぶ。上の例にあるMaterialized.asというメソッドを使ってStore名やSerdeを切り替えたり、他の引数の渡し方によってインメモリデータストアを使うよう変更したりすることもできる。
StateStoreに保存されたデータは、インメモリストアでない限りプロセスを再起動しても保持される。ただしPartitionの割り当てが変わって担当Taskが切り替わると、不要になったり新しく作り直しが必要になったりする。不要になったRocksDBデータは一定期間後に自動削除される。
GroupBy、GroupByKey
KStreamやKTableを集計したいとき、どのキーを基準に集計するかを指定するDSLである。countまたはaggregateの前提として呼び出す必要がある。
KGroupedStream<String, String> groupedStream = stream.groupBy(
(key, value) -> value,
Grouped.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.String()) /* value */
);
groupByを利用すると必ず再パーティションが行われる。再パーティションでは、再パーティション用Topicが自動作成され、そのTopicへRecordを送信して再び受け取る処理を行う。ネットワークとストレージに重複負荷がかかるため、再パーティションはできるだけ避けるべきである。
再パーティショニングを避けるにはgroupByKeyを使用する。
KGroupedStream<String, String> groupedStream = stream.groupByKey(
Grouped.with(
Serdes.String, /* key */
Serdes.String()) /* value */
);
groupByKeyは現在のキーをそのまま使用してグループ化を指定する。この場合、処理過程でキーが変更されていなければ再パーティションは行われない。mapなどの変換処理でキーが変更されている場合は、groupByKeyを使用しても再パーティションが実行される。
aggregate
DSLの中で最も汎用的な集計処理を実装できるDSLである。初期値を生成するInitializer、新しいRecordが到着したときに実行されるAdder、変更前Recordの情報を使って実行されるSubtractor(任意)の3つのLambdaを渡して集計処理を実装する。
KTable<byte[], Long> aggregatedTable = groupedTable.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue.length(), /* adder */
(aggKey, oldValue, aggValue) -> aggValue - oldValue.length(), /* subtractor */
Materialized.as("aggregated-table-store") /* state store name */
.withValueSerde(Serdes.Long()) /* serde for aggregate value */
);
集計結果を処理ノードのローカルに保持し続けていなければ、次のRecordが到着したとき現在の集計値が何か分からない。そのため集計処理には必然的にKTableが必要になる。集計結果はDSLが自動的に構築したStateStoreに保存され、保持される。
StateStoreの実体については知っておくべき要素がいくつかあるため、後でまとめて説明する。まずは結果がStateStoreという場所に保存されることを覚えておく。
windowedBy
一定時間ごとに集計範囲を区切るDSLである。この機能を使うと、5分ごとに合計を計算し続けたり、1つのSessionに含まれるイベント数を数えたりできる。Window処理は時間軸に依存する処理であるため、RecordのTimestampと保存期間が重要である。場合によっては古いTimestampのRecordが遅れて到着することがあり、古い集計データをいつまでも保持するとデータが無限に増えてストレージを圧迫する。このような状況に対応するため、Window処理では保存期間を別途設定できる。
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
Window処理には区切り方によってTumbling Window、Sliding Window、Hopping Window、Session Windowの4種類がある。比較的複雑なので、詳細はConfluentドキュメントを参照するとよい。
Processor API
Kafka StreamsのLow Level APIに該当するもので、上記のDSLはすべてこのProcessor APIで実装されている。
簡単にいえば、Processor APIはクラス定義だけで利用できる。initメソッドにはProcessorContextというオブジェクトが渡されるため、これを利用してKafka Streamsの情報を取得したり、StateStoreへの参照を得たり、後続処理へデータを送ったりできる。詳細はConfluentドキュメントを参照する。
処理の実体はprocessメソッドに実装し、Recordが到着するたびにこの処理が呼び出される。また一定時間ごとにスケジュール処理を行うこともできる。ProcessorContext#scheduleメソッドでPunctuatorという処理を登録し、一定期間ごとに自動実行できる。実行間隔のTimestampを処理する方法として、Kafka StreamsはSTREAM_TIMEとWALL_CLOCK_TIMEの2種類を提供する。それぞれの違いは上記リンクの詳細を参照する。
次は上記ドキュメントから引用したコードサンプルである。重要な部分はStateStoreを取得する部分、スケジュール処理を登録する部分、そしてcontext.forwardを呼び出して後続へRecordを渡す部分である。
public class WordCountProcessor implements Processor<String, String, String, String> {
private KeyValueStore<String, Integer> kvStore;
@Override
public void init(final ProcessorContext<String, String> context) {
context.schedule(Duration.ofSeconds(1), PunctuationType.STREAM_TIME, timestamp -> {
try (final KeyValueIterator<String, Integer> iter = kvStore.all()) {
while (iter.hasNext()) {
final KeyValue<String, Integer> entry = iter.next();
context.forward(new Record<>(entry.key, entry.value.toString(), timestamp));
}
}
});
kvStore = context.getStateStore("Counts");
}
@Override
public void process(final Record<String, String> record) {
final String[] words = record.value().toLowerCase(Locale.getDefault()).split("\\W+");
for (final String word : words) {
final Integer oldValue = kvStore.get(word);
if (oldValue == null) {
kvStore.put(word, 1);
} else {
kvStore.put(word, oldValue + 1);
}
}
}
@Override
public void close() {
// close any resources managed by this processor
// Note: Do not close any StateStores as these are managed by the library
}
}
これをKafka Streamsに組み込むには、Topologyクラスを直接作成するか、StreamsBuilder#buildで生成されたTopologyに対してTopology#addProcessorを呼び出し、任意のProcessorクラスを指定する。このとき利用したいStateStoreがあれば、その名前を渡して関連付ける。そうしないとProcessor APIからStateStoreを見つけられず、例外が発生する。
Topology builder = new Topology();
// add the source processor node that takes Kafka topic "source-topic" as input
builder.addSource("Source", "source-topic")
// add the WordCountProcessor node which takes the source processor as its upstream processor
.addProcessor("Process", () -> new WordCountProcessor(), "Source")
// add the count store associated with the WordCountProcessor processor
.addStateStore(countStoreSupplier, "Process")
// add the sink processor node that takes Kafka topic "sink-topic" as output
// and the WordCountProcessor node as its upstream processor
.addSink("Sink", "sink-topic", "Process");
StateStoreの実体
公式に提供されているStateStoreは、大きくRocksDBを利用したpersistent storeと、プロセスが終了すると消える揮発性のin-memory storeの2種類に分けられる。一般的によく使われるのはpersistent storeだと考えられる。まず共通要素を説明する。なお、APIの形式に合わせて独自実装すれば、独自のStateStoreを定義することもできる。
StateStoreをLow Level APIで利用する場合、自分でStateStoreを構築できる。
// Creating a persistent key-value store:
// here, we create a `KeyValueStore<String, Long>` named "persistent-counts".
import org.apache.kafka.streams.processor.StateStoreSupplier;
import org.apache.kafka.streams.state.StoreBuilder;
import org.apache.kafka.streams.state.Stores;
StoreBuilder countStoreBuilder =
Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("persistent-counts"),
Serdes.String(),
Serdes.Long()
);
Processor APIで利用したい場合は、次のように使う。
KeyValueStore<String, Long> counterStore = context.getStateStore("persistent-counts");
long count = counterStore.fetch("key");
count++;
counterStore.put("key", count);
この例では単純なキー完全一致で取得しているが、Kafka Streamsが提供するStateStoreはキーのバイト列でソートされているため、rangeメソッドを使って一定範囲のキーを取得することもできる。
StateStoreで重要な要素は次のとおりである。
- KVSであり、キー順にソートされる。
- キーと値のどちらも実際に保存される値はバイト列であり、アプリケーションとやり取りするときにSerialize/Deserializeを行う。
- changelog Topicを利用して耐久性を保証する。
- 読み書きに対するcacheメカニズムを持つ。
changelog Topic
前で軽く触れたが、StateStoreを使用するとchangelog TopicがKafka Brokerに自動作成される。in-memory storeの場合はデフォルトで無効である。
changelog Topicは、StateStoreに書き込まれた変更を保持するTopicである。StateStoreにデータが書き込まれたり削除されたり(nullを入れたり)するたびに、changelog TopicへRecordが送信される。
Kafka Streamsはこのchangelog Topicを使って、処理ノードのダウンやTask再割り当てに対応する。
Kafka Streamsプロセスが新しく起動したとき、アプリケーションがStateStoreを使用するよう定義されており、ローカルストレージにStateStoreデータがない場合、Kafka Streamsは復元処理を行う。Kafka Brokerに存在するchangelog TopicからすべてのRecordを読み取り、ローカルStateStoreを復元する。
同様に、ノードの増減によってrebalanceが実行されTaskが再割り当てされた場合も、自分のローカルに割り当てられたTask IDに対応するStateStoreが存在しなければ、まずrestore処理が実行され、その後処理が継続される。
Kafka Brokerはproductionで運用する場合、通常3つ以上のレプリカを持つよう設定されるため、データ自体の耐障害性はKafka Brokerの機能によって保証される。
restore処理の注意点
StateStoreを活用するときに最も注意すべきなのはrestore処理である。
Kafka Streamsはrestoreが必要になると処理を停止する。処理が開始または再開されるのはrestore処理が完了した後である。つまり、StateStoreに蓄積されているデータ量が非常に多くなると、restore処理にかかる時間も長くなり、いざノードがダウンしたり増減したりしたときに長時間処理が停止する危険が生じる。
これを避けるのは現在でも難しい問題である。一定以上古いデータや利用頻度の低いデータは、ネットワークオーバーヘッドを許容して外部ストアへ逃がすなど、データ量を削減する仕組みを組み込むしかない。
changelogの無効化
StateStoreを作成したとき、StoreBuilderのwithLoggingDisabled()を呼び出すとchangelogとの関係を無効化できる。in-memory storeの場合は基本的に無効化されている。
changelog Topicが利用できない場合、restore処理は行われない。RocksDB storeを使用する場合、同じノードで同じIDのTaskが実行される限りデータは保持される。一方、ConsumerのrebalanceによってTaskの再配置が行われた場合や、処理ノードがダウンして復旧不能になった場合、そのデータは消滅する。
主な用途はローカルキャッシュである。メモリに収まらない量であっても、ファイルシステムを利用してノードローカルのキャッシュとして利用できる。
たとえば不変データであれば外部データストアに蓄積しておき、最初の1回はネットワークアクセスのオーバーヘッドが発生するが、その後はローカルファイルシステムにキャッシュされ、ネットワーク経由のアクセスを回避する、といった用途に利用できる。
StateStore cache
ストリーム処理はその性質上、短時間に同じキーのデータを何度も読み書きする可能性が高い。たとえばuser_idをキーにして数値を計算する場合、そのユーザーのイベントRecordが集中して到着することがある。このような状況で毎回ストレージへデータを書き込み、changelog Topicを更新するのは無駄なオーバーヘッドにつながる。
Kafka Streamsではこれを避けるため、cacheがデフォルトで有効になっている。書き込んだ内容は一定期間メモリに保持され、flushタイミングで実際のStateStoreへ書き込まれ、changelogが更新される。
DSLで構築されたKTableでは、このcache機能によりforwardが遅延する。たとえばaggregateで集計された結果を次のDSLで使用したり別Topicへ送ったりする場合、デフォルト動作では一定期間StateStoreにcacheされ、bufferingされる。一定時間が経過するかcache用メモリを消費すると、CacheFlushListenerがRecordを次のProcessorへ渡す。
WindowStoreの実体
先ほどDSL説明でwindowedByというDSLを紹介した。このDSLを利用することで、一定時間WindowごとにRecordを集計できる。
実はこれはWindowStoreというStateStoreの変形によって実装される。WindowStoreを作成するときは次のようになる。1分ごとのWindow幅で、2時間分のデータを保持するWindowStoreは次のように作成する。
StoreBuilder<WindowStore<String, Long>> counterStoreByMinute =
Stores.windowStoreBuilder(
Stores.persistentWindowStore(
"counter",
Duration.ofHours(2),
Duration.ofMinutes(1),
false),
Serdes.String(),
Serdes.Long());
Processor APIで利用したい場合は次のように使う。
WindowStore<String, Long> counterStoreByMinute = context.getStateStore("counter");
long durationMillis = Duration.ofMinutes(1).toMillis();
long currentWindowStart = (context.timestamp() / durationMillis) * durationMillis;
long count = counterStoreByMinute.fetch("key", windowStart);
count++;
counterStoreByMinute.put("key", count, currentWindowStart);
キーと値のストアにTimestampを付与する形で取得や保存を行う。DSLの裏側で使われる場合は、TimestampからTime Windowを自動的に設定してくれるが、WindowStoreを直接扱う場合はTimeWindowの開始となるTimestampを手動で算出する必要がある。WindowStoreにあらかじめ与えられたWindow Durationは、記録されたTimestampを基準にどの程度のWindowであるかを示すために使われる。
上の例は非常に単純な形だが、Timestampの開始と終了時刻を渡し、その範囲に含まれるRecordを順番に検索することもできる。また通常のKeyValueStoreと同じように、キー範囲探索とTimestampの開始・終了時刻の範囲探索を組み合わせることもできる。
内部実装として、WindowStoreは複数のRocksDB storeで構成されており、記録するTimestampごとに大まかなsegmentに分割されている。保存時にはTimestampから該当segmentを識別し、その領域にデータを書き込む。取得時には対象範囲のsegmentからだけデータを取得することで、検索範囲を小さくしている。またTimestampの範囲からsegmentを決定できるため、現在処理しているTimestampと比較して保存期限を過ぎたものは、ファイル単位でまとめて削除することで簡単に破棄できる。
書き込み時には、Recordに与えられたキー(上の例では"key"という文字列)の末尾にミリ秒単位のUnix timestampが自動的に付与されて記録される。