Designing Data-Intensive Applications | Chapter 05. Replication
Presenters: Hojun Lee, Sungjik Jo
Part 2. Distributed Data
Part 1 looked at data systems on a single machine. Part 2 deals with systems in which several machines are involved.
There are several reasons to distribute data:
Scalability
When data volume or read/write load exceeds what one machine can handle, the load can be spread across multiple machines.
Fault tolerance and high availability
If one machine fails, the application can continue operating on other machines.
Latency
If users are distributed around the world, data can be placed in data centers closer to them to reduce response time.
Vertical and Horizontal Scaling
Vertical scaling, or scaling up, means using a more powerful machine. It combines more CPU, memory, and disks into one operating system image. Shared-memory and shared-disk architectures can be useful, but they are expensive and have limits in fault tolerance and scalability.
Horizontal scaling, or scaling out, means using many independent nodes. Each node has its own CPU, memory, and disk, and coordination happens through software over the network. This approach can use cost-effective hardware, distribute data geographically, and reduce the impact of a whole data-center failure. It also introduces the constraints and trade-offs of distributed systems.
Replication
Replication means keeping copies of the same data on several networked machines. It is used to keep data geographically close to users, continue operating when part of the system fails, and increase read throughput by adding more machines that can answer read queries.
Replication is difficult because data changes. The main challenge is handling changes to replicated data.
Common replication algorithms are single-leader, multi-leader, and leaderless replication. Each has different strengths and weaknesses.
Leaders and Followers
A replica is a node that stores a copy of the database. In leader-based replication, one replica is designated as the leader. Clients send writes to the leader, and the leader sends the changes to followers.
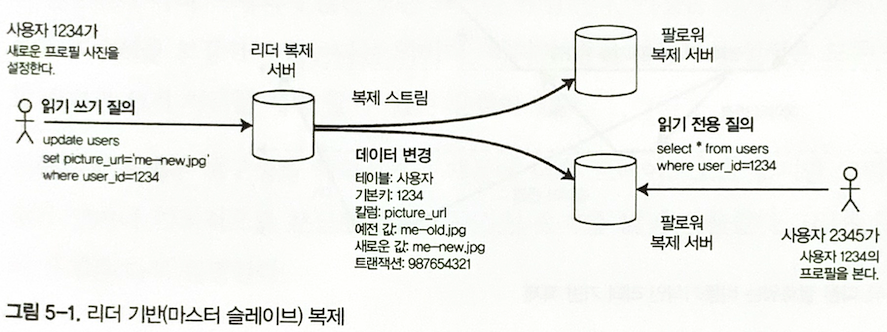
Figure 5-1. Leader-based replication.
The leader, also called the primary or master, handles writes and often reads. Followers, also called read replicas, slaves, secondaries, or hot standbys, receive the leader’s change log and update their local copies. Many relational databases, NoSQL systems, and message brokers use this pattern.
Synchronous and Asynchronous Replication
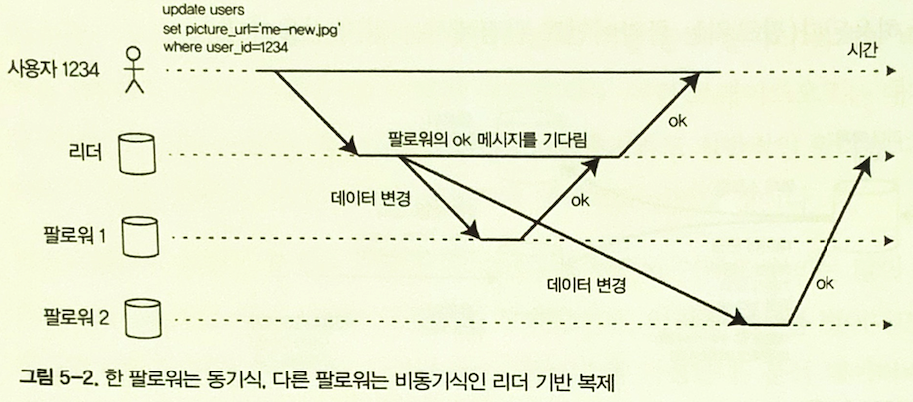
Figure 5-2. One follower is synchronous and another is asynchronous.
With synchronous replication, the leader waits until a follower confirms that it has received the write before reporting success to the client. This guarantees that the follower has up-to-date data, but if the follower is slow or unavailable, writes may block.
With asynchronous replication, the leader does not wait for followers. This reduces latency and improves availability, but if the leader fails before changes reach followers, acknowledged writes may be lost.
A semi-synchronous configuration keeps one follower synchronous and the others asynchronous. If the synchronous follower becomes unavailable, another follower can be made synchronous. Fully asynchronous replication is common when there are many followers or geographically distributed nodes, despite weaker durability guarantees.
Setting Up a New Follower
A new follower is needed when increasing read capacity or replacing a failed node. Simply copying data files is not enough because writes continue while the copy is being made. Locking the database would harm availability.
The usual process is to take a consistent snapshot of the leader without blocking writes, copy the snapshot to the new follower, and then ask the leader for all changes that happened after the snapshot. Once the follower has processed the backlog, it has caught up and can continue receiving changes.
Handling Node Outages
Follower failure is handled by catch-up recovery. The follower keeps a local log of changes it has received. After it restarts or reconnects, it asks the leader for the changes after the last processed transaction and applies them.
Leader failure requires failover. One follower is promoted to become the new leader, clients must send writes to it, and other followers start consuming changes from the new leader. Failover can be manual or automatic.
Automatic failover must detect that the leader has failed, choose a new leader, and reconfigure clients and followers. Timeouts are commonly used for failure detection, but false positives are possible.
Problems With Failover
Failover can lose data if asynchronous writes were acknowledged by the old leader but not replicated to the new leader. A former leader may return after being considered dead, creating split brain if two leaders accept writes. Choosing timeouts is difficult because short timeouts cause unnecessary failovers, while long timeouts extend downtime.
Implementation of Replication Logs
Replication can be implemented in several ways:
- Statement-based replication sends SQL statements to followers, but nondeterministic functions, auto-increment values, triggers, and side effects can cause inconsistencies.
- Write-ahead log shipping sends low-level storage-engine log records. This tightly couples replication to the storage format.
- Logical log replication uses row-level records that describe inserted, updated, and deleted rows. It is easier to keep compatible across versions.
- Trigger-based replication lets application code capture and replicate changes, but it is more complex and often slower.
Problems With Replication Lag
Asynchronous replication creates replication lag: followers may be behind the leader. This can cause users to read stale data.
Read-after-write consistency ensures that a user sees their own writes. Monotonic reads ensure that a user does not see time move backward by reading from a more stale replica after reading from a fresher one. Consistent prefix reads ensure that causally related writes are observed in the correct order.
Replication lag is especially visible when reads are served from followers for scalability. Applications often need routing, timestamps, version tracking, or session affinity to provide stronger user-facing guarantees.
Multi-Leader Replication
In multi-leader replication, more than one node accepts writes. Each leader sends its changes to the others. This can be useful across multiple data centers because users can write to a nearby data center and continue operating if another data center is unavailable.
The main problem is write conflicts. Two leaders may update the same data concurrently. Conflict handling can avoid conflicts by routing writes for a record to the same leader, converge automatically with deterministic rules, preserve all conflicting versions for application resolution, or use custom conflict-resolution logic.
Multi-leader replication is also useful for offline-capable clients and collaborative editing, where multiple replicas may accept changes independently and synchronize later.
Leaderless Replication
In leaderless replication, clients send writes to several replicas directly, or a coordinator does so on their behalf. Reads also query several replicas and reconcile the returned versions.
If there are n replicas, a write quorum w, and a read quorum r, the condition w + r > n means reads should overlap with the latest successful write. For example, with n = 3, w = 2, and r = 2, at least one read replica should contain the latest value.
Quorums are not a complete consistency guarantee. Concurrent writes, sloppy quorums, network partitions, and delayed repair can still produce stale or conflicting values.
Sloppy Quorums and Hinted Handoff
During a network interruption, a client may be unable to reach enough home replicas. A sloppy quorum allows writes to be accepted by other reachable nodes. Later, hinted handoff sends those writes back to the intended replicas. This improves availability but weakens consistency guarantees.
Detecting Concurrent Writes
Leaderless systems need to detect and resolve concurrent writes. Last-write-wins is simple but can lose data. A safer approach is to keep multiple versions and let clients merge them. Happens-before relationships and version vectors help determine whether one write supersedes another or whether two writes are concurrent.
Summary
Replication improves locality, availability, and read scalability, but it introduces lag, failover complexity, and conflict handling. Single-leader replication is simple but has leader failover issues. Multi-leader replication improves geographical availability but must resolve conflicts. Leaderless replication offers high availability through quorums, but applications must understand and handle concurrent versions.