Designing Data-Intensive Applications | Chapter 11. Stream Processing
Presenters: Kyungcheol Kim, Mingyu Kim
A stream is data that is produced gradually over time. Stream processing handles events as they occur, unlike batch processing, which collects data and processes it later. An event stream is an ordered sequence of business events that can be processed incrementally.
Transmitting Event Streams
An event contains details about something that happened at a particular point in time, usually with an event timestamp based on a clock. Events include user actions such as viewing a page or purchasing a product, sensor readings, CPU metrics, and lines in a web server log.
Events can be encoded as text, JSON, or binary data. They can be written to files, relational tables, or document databases, and they can be sent over the network for another node to process.
Producers, publishers, or senders create events. Consumers, subscribers, or recipients process events. Stream systems group related events into topics or streams.
In batch processing, a day’s worth of data may be processed at the end of the day. In stream processing, new events are checked and processed continuously, while still keeping track of progress since the last processed event.
Messaging Systems
A messaging system notifies consumers about new events. Producers send messages that contain events, and consumers receive and process them.
The simplest approach is a direct communication channel such as a Unix pipe or TCP connection. A messaging system generalizes this by allowing many producers to send messages to the same topic and many consumers to receive messages from it.
Publish/subscribe systems must decide what happens when producers send faster than consumers can process:
- Drop messages.
- Buffer messages in a queue.
- Apply backpressure, also called flow control, to slow producers down.
They must also decide what happens when a node fails or goes offline. Durability requires writing messages to disk, replicating them, or both. Avoiding durability can improve throughput and latency, but lost messages may be unacceptable depending on the application.
Direct Messaging
Some systems send messages directly from producers to consumers without an intermediate broker. UDP multicast is used in latency-sensitive financial systems, while application-level protocols can recover lost packets. ZeroMQ and nanomsg provide publish/subscribe messaging over TCP or IP multicast. Metrics systems such as StatsD use UDP messaging. Producers can also call an exposed HTTP or RPC endpoint on the consumer.
The limitation of direct messaging is that the application must handle lost messages and offline consumers. Messages sent while a consumer is unavailable may be lost.
Message Brokers
A message broker is an alternative that receives messages from producers and delivers them to consumers. It is a kind of database optimized for message streams. Producers and consumers connect to the broker as clients.
The broker absorbs changes in client state. If messages are written to disk, they can survive broker failure. If consumers are slow, the broker can buffer messages, though a growing queue raises questions about memory, disk usage, and performance.
Compared with databases, brokers usually delete messages after delivery or acknowledgement. They are optimized for sequential message delivery rather than arbitrary queries over stored data.
Message brokers include RabbitMQ, ActiveMQ, Qpid, HornetQ, TIBCO Enterprise Message Service, IBM MQ, Azure Service Bus, and Google Cloud Pub/Sub. JMS is a Java API for sending, receiving, and reading messages. AMQP is an open standard application-layer protocol for message-oriented middleware.
Multiple Consumers
There are two common patterns:
- Load balancing: each message is delivered to one consumer, spreading work across nodes.
- Fan-out: each message is delivered to all consumers, allowing independent processing pipelines.
Consumer groups combine both ideas. Each group receives all messages, but within a group each message is processed by only one node.
Acknowledgements and Redelivery
A broker may deliver a message to a consumer that fails before processing it. To avoid loss, the consumer explicitly acknowledges successful processing. If the broker does not receive an acknowledgement before a timeout or disconnect, it redelivers the message.
Redelivery can change ordering. If one consumer fails while processing m3 and another consumer has already processed m4, m3 may be redelivered later and processed after m4.
Partitioned Logs
Traditional message brokers treat messages as temporary. After delivery and acknowledgement, a message is removed and cannot be recovered. Databases and files, by contrast, keep data until someone deletes it.
A log-based broker stores messages as an append-only sequence on disk. Producers append messages to the end of the log. Consumers read the log sequentially and wait for notification when they reach the end.
To increase throughput, the log can be partitioned. Each partition may be served by a different machine. Within a partition, the broker assigns each message an increasing offset. Ordering is guaranteed within a partition, not across partitions.
Apache Kafka, Amazon Kinesis, and Twitter’s distributed log use this style. They can process very high message volumes and tolerate failures by replicating messages.
Logs Versus Traditional Messaging
Log-based messaging supports fan-out because consumers read the log independently and messages are not deleted when read. Load balancing is usually done by assigning partitions to consumers in a group.
The advantage is high throughput and replayability. The disadvantage is that the number of consumers in a group is limited by the number of partitions, and a slow consumer may fall behind.
Consumer Offsets
When a consumer processes a partition sequentially, its progress can be represented by an offset. There is no need to track acknowledgements for every message. This reduces overhead and enables batching and pipelining.
Offsets are similar to log sequence numbers in database replication. If a consumer fails, another consumer in the group can resume from the last committed offset. If the failed consumer processed messages but did not commit the offset, those messages may be processed again.
Disk Space and Slow Consumers
Log-based brokers usually retain messages for a fixed time or until a size limit is reached. If a consumer falls so far behind that required messages have been deleted, it cannot catch up without another source of data. Operational monitoring must therefore track consumer lag.
Replaying Old Messages
In AMQP- or JMS-style brokers, acknowledging a message usually removes it. In log-based brokers, consuming a message does not change the log. A consumer can move its offset backward and replay old messages. This is useful for debugging, rebuilding derived data, and deploying new stream processors.
Databases and Streams
Databases and streams are connected because a database change log is a stream of events. Replication logs, write-ahead logs, and change data capture all expose changes as ordered records.
Keeping Systems in Sync
Many applications maintain data in several systems: a database, a cache, a search index, an analytics system, or a data warehouse. Dual writes, where the application writes to two systems separately, can fail halfway and leave systems inconsistent.
Change data capture (CDC) solves this by deriving a stream of changes from the database and applying them to other systems. The database becomes the source of truth, and consumers update derived systems from the change stream.
Event Sourcing
Event sourcing stores all changes as immutable events. Instead of storing only the current state, the application records the sequence of events that led to it. Current state can be reconstructed by replaying the events.
Event sourcing works well with auditability and derived views, but it requires careful schema evolution and event design because old events must remain understandable.
State, Streams, and Immutability
Mutable state can be viewed as the result of applying a stream of immutable events. Keeping the event log makes it possible to rebuild state, create new derived views, and recover from bugs. Compaction can retain the latest value for each key when the full history is no longer needed.
Processing Streams
Stream processing can do many things: send alerts, update dashboards, build search indexes, update caches, detect fraud, enrich events, and compute analytics.
Stream processors consume input streams and produce output streams or update databases. They must decide how to handle time, joins, faults, and exactly-once effects.
Uses of Stream Processing
Complex event processing looks for patterns in event streams. Stream analytics computes metrics such as rates, percentiles, or rolling aggregates. Maintaining materialized views keeps derived data up to date as source data changes.
Time Reasoning
Events often arrive late or out of order. Event time is when the event actually happened. Processing time is when the processor sees it. Windowing groups events by time, but late events make windows hard to close. Systems use watermarks or allowed lateness to balance correctness and latency.
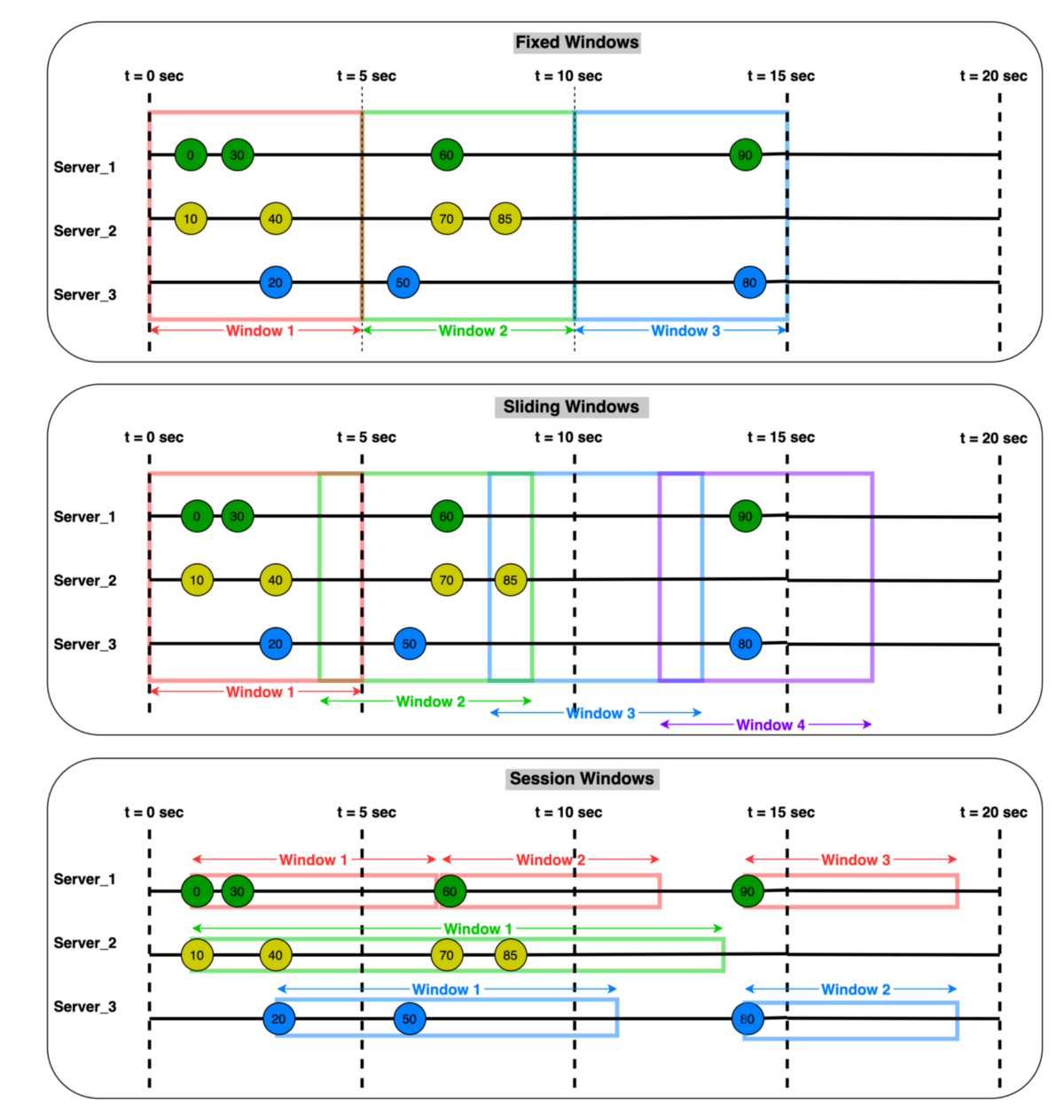
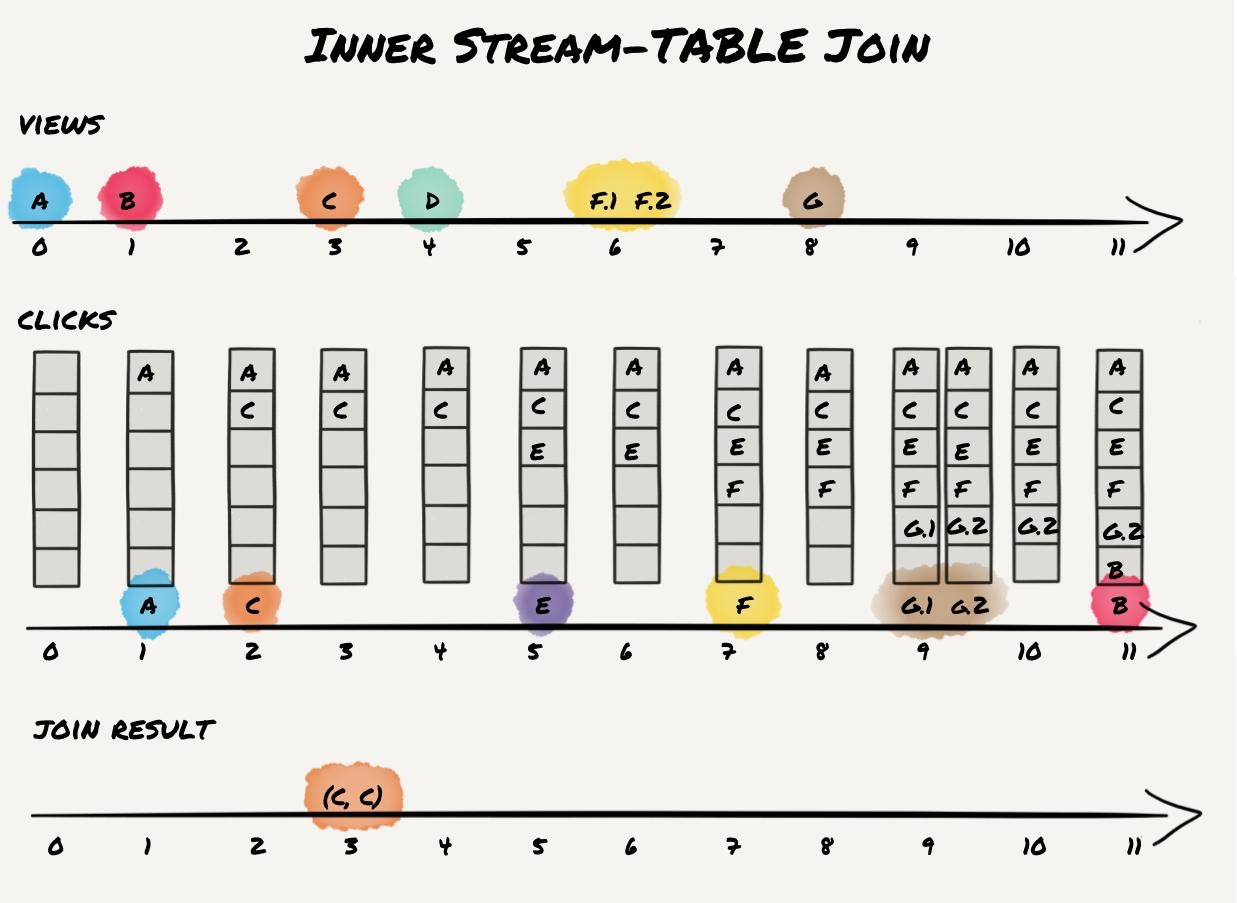
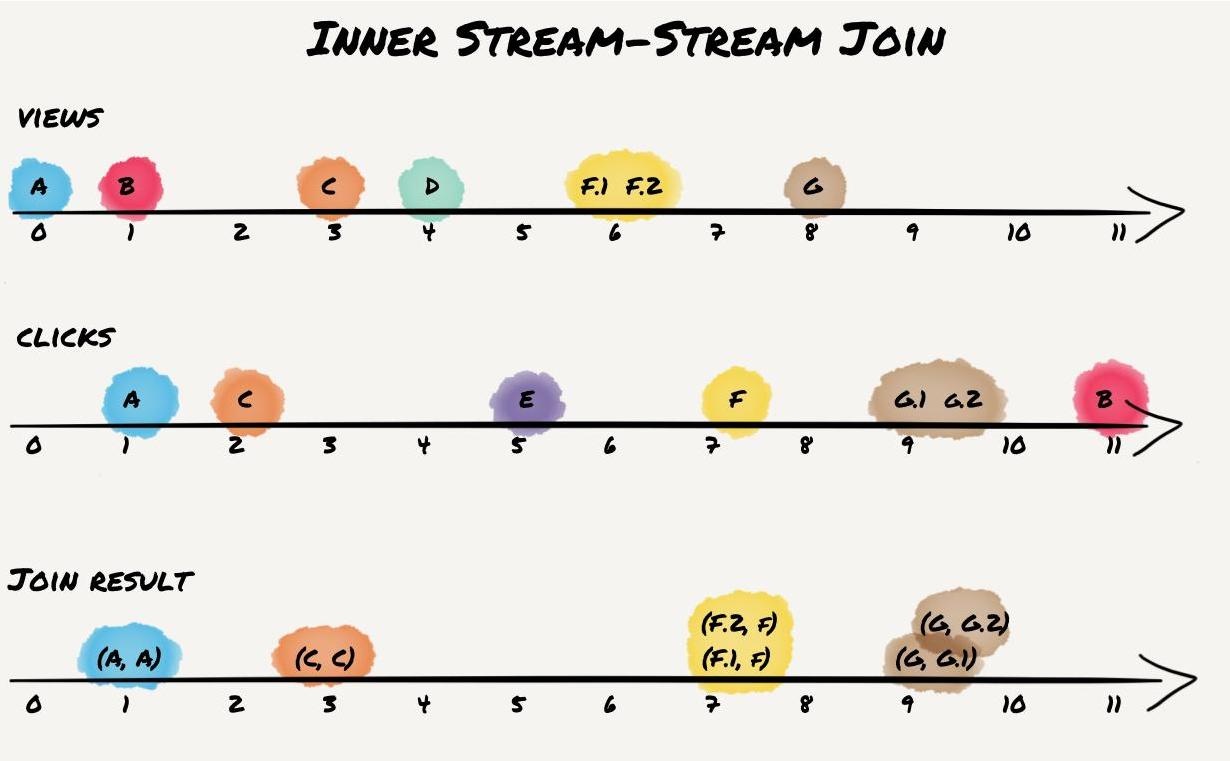
Stream Joins
Stream processing may join a stream with a table, two streams with each other, or a stream with a changing table.
For stream-stream joins, the processor must keep recent events from both sides so that matching events arriving later can be joined.
Fault Tolerance
Batch processing can retry failed tasks because input files are immutable. Stream processing is harder because it runs continuously and may have side effects.
At-least-once processing may process an event more than once. At-most-once processing may lose events. Exactly-once processing is usually implemented by replayable logs, checkpoints, deterministic processing, idempotent writes, or transactions between input offsets and output writes.
Summary
Stream processing treats ongoing data as a first-class input. Messaging systems deliver events, log-based brokers retain and replay them, and database change streams keep derived systems in sync. The main design questions are delivery guarantees, ordering, retention, time handling, joins, state management, and fault tolerance.