Spring Batchのスケーリングと並列処理 | 公式リファレンス翻訳

Spring WebFlux、WebClient、WebSocket、RSocket。
この文書は、Spring Batchリファレンス文書Version 5.0.0の公式リファレンスを韓国語へ翻訳した文書です。
スケーリングと並列処理
多くのバッチ処理問題は、単一スレッドかつ単一プロセスのジョブで解決できるため、より複雑な実装を考える前に、それで要件を満たすかどうかを適切に確認することをおすすめします。現実的なジョブの性能を測定し、まず最も単純な実装が必要を満たすか確認します。標準的なハードウェアでも、数百メガバイトのファイルを1分もかからずに読み書きできます。
複数の並列処理を使用してジョブ実装を始める準備ができたら、Spring Batchはいくつかの選択肢を提供します。これらの選択肢をこの章で説明します。大まかに言うと、並列処理には2つのモードがあります。
- 単一プロセス、マルチスレッド
- マルチプロセス
これらは次のように分類されます。
- マルチスレッドStep(single-process)
- 並列Step(single-process)
- リモートStepのチャンク化(multi-process)
- Stepのパーティショニング(single or multi-process)
まず単一プロセスの選択肢を確認します。その後、マルチプロセスの選択肢を確認します。
マルチスレッドStep
並列処理を始める最も簡単な方法は、TaskExecutorをStep構成に追加することです。
例えば、次のように属性をtaskletに追加できます。
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>
Java構成を使用する場合は、次の例のようにStepにTaskExecutorを追加できます。
Java Configuration
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}
例えば、taskExecutorはTaskExecutorインターフェースを実装する別のBean定義への参照です。TaskExecutor(Javadoc)は標準のSpringインターフェースです。利用可能な実装の詳細はSpringユーザーガイドを参照してください。最も単純なマルチスレッドTaskExecutorはSimpleAsyncTaskExecutorです。
上記構成の結果、Stepは個別の実行スレッドで各チャンク、つまり各コミット間隔の項目を読み取り、処理し、書き込むことを意味します。これは、処理対象の項目に固定順序がなく、チャンクには単一スレッドの場合と比べて連続していない項目が含まれる可能性があることを意味します。タスクエグゼキューターによって課される制限、例えばスレッドプールに支えられているかどうかに加えて、taskletの構成にはスロットル制限(throttle-limit、デフォルト: 4)があります。スレッドプールを完全に使用するには、この制限を増やす必要がある場合があります。
例えば、次のようにthrottle-limitを増やせます。
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>
Java構成を使用する場合、ビルダーは次のようにスロットル制限へのアクセスを提供します。
Java Configuration
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}
また、Stepで使用されるプールされたリソース、例えばDataSourceなどによって同時実行性に制限が設定される場合があります。これらのリソースのプールは、少なくともStepで必要な同時スレッド数と同じ大きさでなければなりません。
一般的なバッチ利用ケースの一部では、マルチスレッドStep実装を使用することにいくつかの実際的な制限があります。
Stepに参加する多くのオブジェクト、例えばreaderやwriterなどは状態を持ちます。状態がスレッドごとに分離されていない場合、これらのコンポーネントをマルチスレッドStepで使用できません。特に、Spring Batchのreaderとwriterの多くは、マルチスレッドで使用するようには設計されていません。
しかし、状態を持たない、またはスレッドセーフなreaderとwriterは使用できます。また、Spring Batchサンプル(GitHub)には、Preventing State Persistenceのような処理識別子を使用して、データベース入力テーブル内ですでに処理された項目を追跡する方法を示すサンプル(parallelJob)があります。
Spring Batchは、ItemWriterやItemReaderなど、いくつかの実装を提供します。通常、Javadocにはスレッドセーフかどうか、または同時実行環境での問題を回避するために何をすべきかが記載されています。Javadocに情報がなければ、実装に状態があるかを確認すればよいです。readerがスレッドセーフでない場合は、提供されているSynchronizedItemStreamReaderでデコレートするか、独自の同期デリゲートとして使用できます。read()への呼び出しを同期すればよく、processとwriteがチャンクで最もコストの高い部分であれば、Stepは単一スレッド構成よりはるかに速く完了する可能性があります。
並列Step
並列処理が必要なアプリケーションロジックを個別の役割に分割し、個別のStepへ割り当てられる限り、単一プロセスで並列化できます。Parallel Stepを実行する設定と使用は簡単です。
例えば、次のようにすれば、Step (step1, step2)とstep3を簡単に並列実行できます。
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>
Java構成を使用する場合は、次のようにStep (step1, step2)とstep3を簡単に並列実行できます。
Java Configuration
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
構成可能なタスクエグゼキューターは、個別のフローを実行するTaskExecutor実装を指定するために使用されます。デフォルトはSyncTaskExecutorですが、Stepを並列実行するには非同期のTaskExecutorが必要です。この処理は、終了ステータスを集計して移行する前に、分割内のすべてのフローが確実に完了するようにします。
詳細はSplit Flowsセクションを参照してください。
Remote Chunking: リモートチャンク
リモートチャンク(Remote Chunking)では、Step処理が複数プロセスに分割され、複数のミドルウェアを通じて相互に通信します。次の画像はこのパターンを示しています。
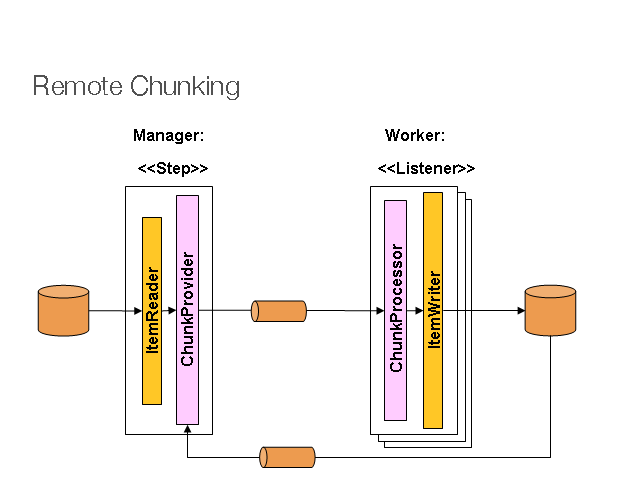
図1: リモートチャンク
マネージャーコンポーネントは単一プロセスで、ワーカーは複数のリモートプロセスです。このパターンは、マネージャーがボトルネックにならない場合に最適に動作するため、処理コストが項目を読み取るより高い場合、実際によくあるケースで効果的です。
マネージャーは、項目チャンクをメッセージとしてミドルウェアへ送る方法を知っている汎用バージョンに置き換えられたItemWriterを持つSpring Batch Stepの実装です。ワーカーは、使用中のミドルウェアの標準リスナー、例えばJMSのMesssageListener実装であり、その役割はChunkProcessorインターフェースを通じて標準のItemWriterまたはItemProcessorを使用し、ItemWriter項目のチャンクを処理することです。このパターンを使用する利点の一つは、reader、processor、writerコンポーネントが既製品であることです。つまり、Stepをローカル実行するために使用するものと同じです。項目は動的に分割され、ミドルウェアを通じて作業が共有されるため、リスナーがすべて積極的なコンシューマーであれば、ロードバランシングは自動的に行われます。
ミドルウェアは耐久性があり、各メッセージを1つのコンシューマーへ配信することを保証する必要があります。JMSが最も明確な候補ですが、グリッドコンピューティングや共有メモリ製品領域で使用される他の選択肢、例えばJavaSpacesなども存在します。
詳細はSpring Batch integration - Remote Chunkingを参照してください。
Partitioning: パーティショニング
Spring Batchは、Step実行を分割し、リモートで実行するためのSPIも提供します。この場合、リモート参加オブジェクトはStepインスタンスであり、ローカル処理と同じように構成して使用できます。次の画像はこのパターンを示しています。
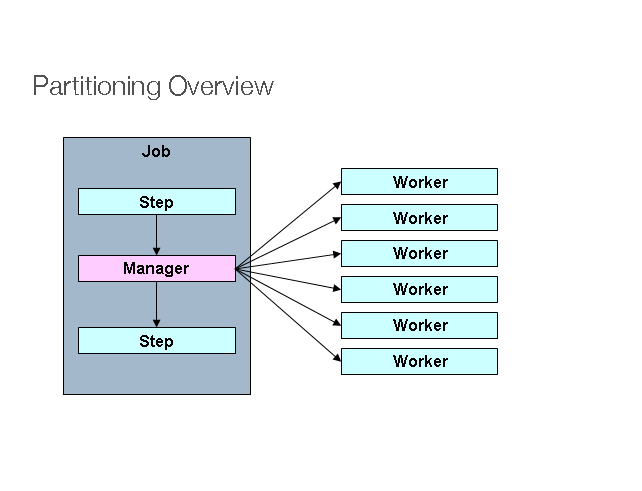
図2: パーティショニング
左側のJobは一連のStepインスタンスとして実行され、そのうち1つのStepインスタンスがマネージャーとして表示されています。この図のすべてのワークはStepの同じインスタンスであり、実際にはマネージャーの代わりとなり、結果としてJobと同じ結果になります。ワーカーは通常リモートサービスですが、ローカル実行スレッドでもかまいません。このパターンでマネージャーがワーカーへ送るメッセージは、耐久的である必要も配信保証される必要もありません。JobRepositoryにあるSpring Batchメタデータにより、各ワーカーはJobの各実行に対して1回だけ実行されます。
Spring BatchのSPIは、PartitionStepと呼ばれるStepの特別な実装と、特定の環境に応じて実装する必要がある2つの戦略インターフェースで構成されます。戦略インターフェースはPartitionHandlerとStepExecutionSplitterであり、次のシーケンス図はそれらの役割を示しています。
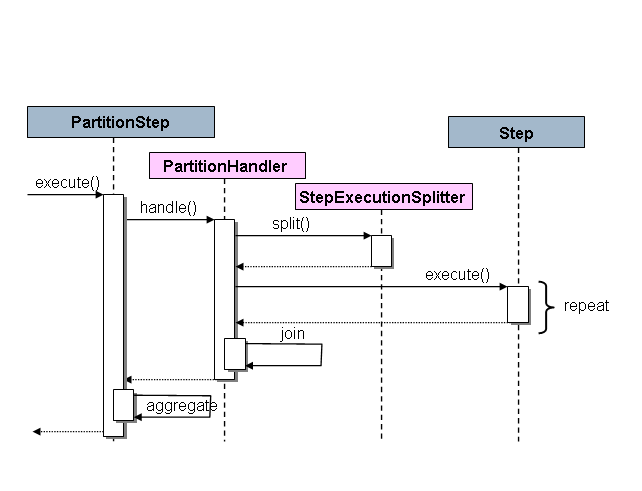
図3: パーティショニングSPI
この場合、右側のStepはリモートワーカーであるため、この役割を担う多くのオブジェクトとプロセスがあり、実行を主導するものとしてPartitionStepが示されています。
次の例は、XML構成を使用する場合のPartitionStep構成を示しています。
<step id="step1.manager">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>
次の例は、Java構成を使用する場合のPartitionStep構成を示しています。
Java Configuration
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.<String, String>partitioner("step1", partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
マルチスレッドStepのthrottle-limit属性と同じように、grid-size属性は、タスクエグゼキューターが単一Stepへ過剰なリクエストを送らないようにできます。
マルチスレッドStepのthrottleLimitメソッドと同じように、gridSizeメソッドは、タスクエグゼキューターが単一Stepへ過剰なリクエストを送らないようにできます。
Spring Batchサンプル(GitHub)のユニットテストスイートに簡単な例があります。partition*Job.xml構成を参照し、コピーして拡張して使用できます。
Spring Batchは、step1:partition0というパーティションのStep実行を作成します。多くの人は一貫性のために、マネージャーのStepをstep1:managerと呼ぶことを好みます。Stepには別名を使用できます。id属性の代わりにname属性を指定します。
PartitionHandler
PartitionHandlerは、リモート環境またはグリッド環境の構造を理解するコンポーネントです。DTOのようなファブリック固有の形式でラップされたリモートStepインスタンスへStepExecutionリクエストを送れます。入力データを分割する方法や、複数のStep実行結果を集計する方法を知る必要はありません。一般的に言えば、弾力性とフェイルオーバーはファブリックの機能であるため、それらについて知る必要はありません。いずれにしても、Spring Batchはファブリックに関係なく常に再起動可能な動作を提供します。失敗したJobはいつでも再起動でき、その場合は失敗したStepだけを再実行します。
PartitionHandlerインターフェースは、単純なRMIリモーティング、EJBリモーティング、カスタムWebサービス、JMS、Java Spaces、共有メモリグリッド(Terracotta、Coherenceなど)、グリッド実行ファブリック(GridGainなど)といったさまざまなファブリック種別に特化した実装を持てます。Spring Batchには独自のグリッドまたはリモートファブリックの実装は含まれていません。
ただし、Spring BatchはSpringのTaskExecutor戦略を使用して、各Stepインスタンスを個別の実行スレッドとしてローカルで実行するPartitionHandlerの便利な実装を提供します。この実装はTaskExecutorPartitionHandlerと呼ばれます。
TaskExecutorPartitionHandlerは、前述のXML名前空間で構成されたStepのデフォルトです。次のように明示的に構成することもできます。
<step id="step1.manager">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>
次のようにJava構成を使用して、TaskExecutorPartitionHandlerを明示的に構成できます。
Java Configuration
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.partitioner("step1", partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}
gridSize属性は、Stepをいくつに分けて実行するかを決めるため、TaskExecutorのスレッドプールサイズと一致させることができます。または、利用可能なスレッド数より大きく設定して作業ブロックを減らすこともできます。
TaskExecutorPartitionHandlerは、大量ファイルコピーやコンテンツ管理システムでのファイルシステム複製など、I/O処理が多いStepインスタンスに有用です。リモート呼び出し、例えばSpring Remotingの使用などのプロキシであるStep実装を提供することで、リモート実行にも使用できます。
Partitioner: パーティショナー
Partitionerの役割は簡単です。新しいStep実行専用の入力パラメータとして実行コンテキストを生成します。再起動について心配する必要はありません。次のインターフェース定義からわかるように、単一のメソッドがあります。
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
このメソッドの戻り値は、各Step実行の一意な名前(String)を、ExecutionContext型の入力パラメータに関連付けます。名前は後で分割されたStepExecutionのStep名としてバッチメタデータに表示されます。ExecutionContextは単純にキーと値のペアを保存するため、一連の主キー、行番号、または入力ファイル内の位置を含められます。次に、リモートStepは通常、次のセクションで説明するように、#{...}プレースホルダー、つまりStepScopeでの遅延バインディングを使用してコンテキスト入力にバインドします。
Step実行の名前、つまりPartitionerによって返されるMapのキーは、Job内のStep実行の中で一意である必要がありますが、それ以外の特定の制約はありません。これを行い、かつ名前をユーザーにとって意味のあるものにする最も簡単な方法は、プレフィックスとサフィックスの命名規則を使うことです。サフィックスは単純なカウンターです。フレームワークには、この規則を使用するSimplePartitionerが用意されています。
PartitionNameProviderインターフェースを使用すると、パーティション名をパーティション自体とは別に指定できます。Partitionerがこのインターフェースを実装している場合、再起動時には名前だけが照会されます。パーティショニングに負荷がある場合、これは有用な最適化になります。PartitionNameProviderが提供する名前は、Partitionerが提供する名前と一致する必要があります。
入力データをStepへバインドする
PartitionHandlerによって実行されるStepが同じ構成を持ち、実行時にExecutionContextから入力パラメータがバインドされるのは非常に効率的です。これはSpring BatchのStepScope機能を使用して簡単に実行できます。詳しくは遅延バインディングのセクションで説明します。例えば、Partitionerが各Step呼び出しに対して異なるファイル、またはディレクトリを指すfileNameプロパティキーを使用してExecutionContextインスタンスを生成する場合、Partitionerの出力は次の表の内容に似たものになります。
表1: ディレクトリ処理を対象とするPartitionerによって提供される実行コンテキストのStep実行名の例
| Step実行名(キー) | ExecutionContext(値) |
|---|---|
| filecopy:partition0 | fileName =/home/data/one |
| filecopy:partition1 | fileName =/home/data/two |
| filecopy:partition2 | fileName =/home/data/three |
その後、実行コンテキストへの遅延バインディングを使用して、ファイル名をStepへバインドできます。
次の例は、XMLで遅延バインディングを定義する方法を示しています。
XML Configuration
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resources" value="#{stepExecutionContext[fileName]}/*"/>
</bean>
次の例は、Javaで遅延バインディングを定義する方法を示しています。
Java Configuration
@Bean
public MultiResourceItemReader itemReader(
@Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) {
return new MultiResourceItemReaderBuilder<String>()
.delegate(fileReader())
.name("itemReader")
.resources(resources)
.build();
}