Bloom Filter Data Structure Explained Simply
What Is a Bloom Filter?
A Bloom Filter is an efficient probabilistic data structure. It is used to test whether an element is a member of a set. Bloom filters are not as commonly used as binary trees or hash maps, but they are used from time to time.
The basic concept is very simple and is especially useful in the following situation.
When there is a Set and an Element, a Bloom filter can quickly tell whether a specific Element exists in that Set. When asked whether a specific Element exists in a specific Set, a Bloom filter can give two answers.
- The specific Element does not exist in the specific Set.
- The specific Element may exist in the specific Set.
These two answers mean that when an Element does not exist in the filter, the answer can be given with certainty, but when it appears to exist, the answer is not certain.
The reason it is used despite being inexact is that a Bloom Filter is a space-efficient data structure. The memory area it uses can be fixed from the beginning. The unit of a Bloom Filter element is a bit. On a 32-bit machine, an integer can contain up to 32 elements.
Bloom Filter Structure
Now let’s explain how a Bloom filter works. A Bloom filter consists of one array of bits and n hash functions.
n Hash functions
A Bloom Filter uses multiple hash functions.
A hash function takes a value and turns it into one number among the indexes of an array.
The number of hash functions can be set to several, and each function uses a different hashing method.
The functions are used for the following:
- Add a new Element to a Set.
- Check whether an input Element exists in a Set.
Array with multiple values
A Bloom filter is made of an array with multiple values. A value is passed through hash functions, and the resulting indexes are changed to numbers.
The example uses a Bloom Filter with an array size of 20.
Adding a New Element to a Bloom Filter
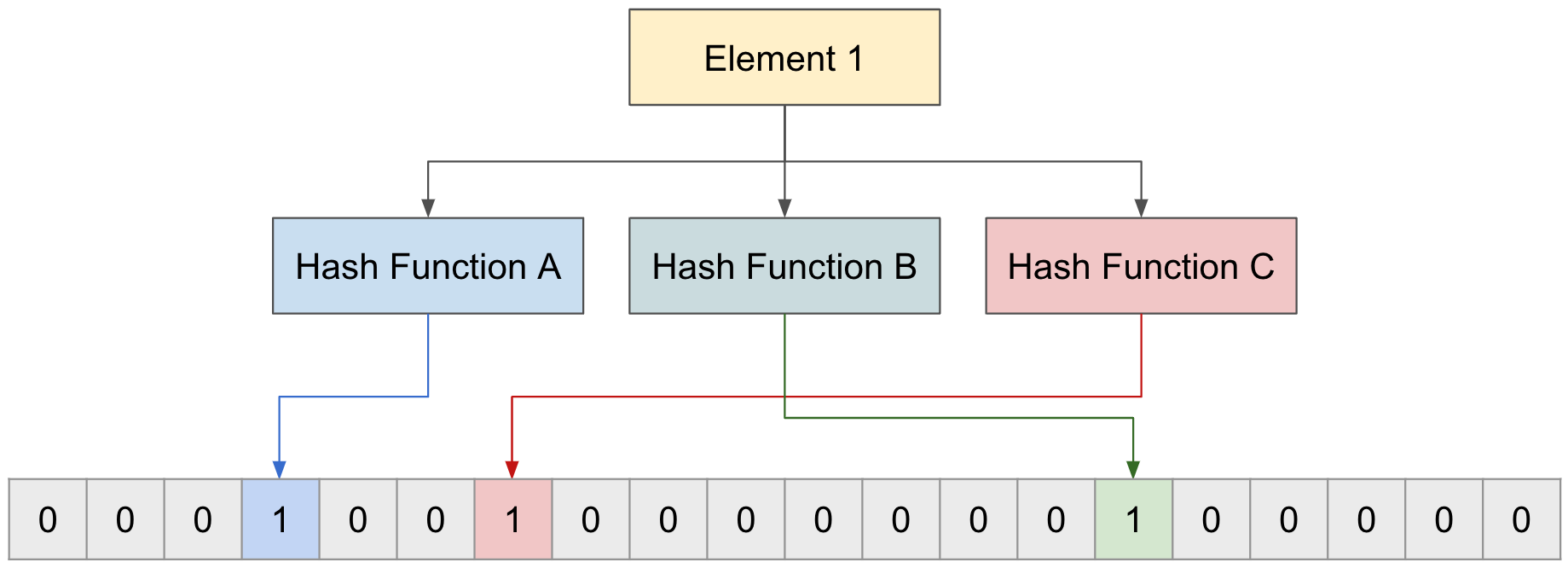
For “Element 1”, the Bloom filter gets indexes through three functions and changes the values at those indexes from 0 to 1.
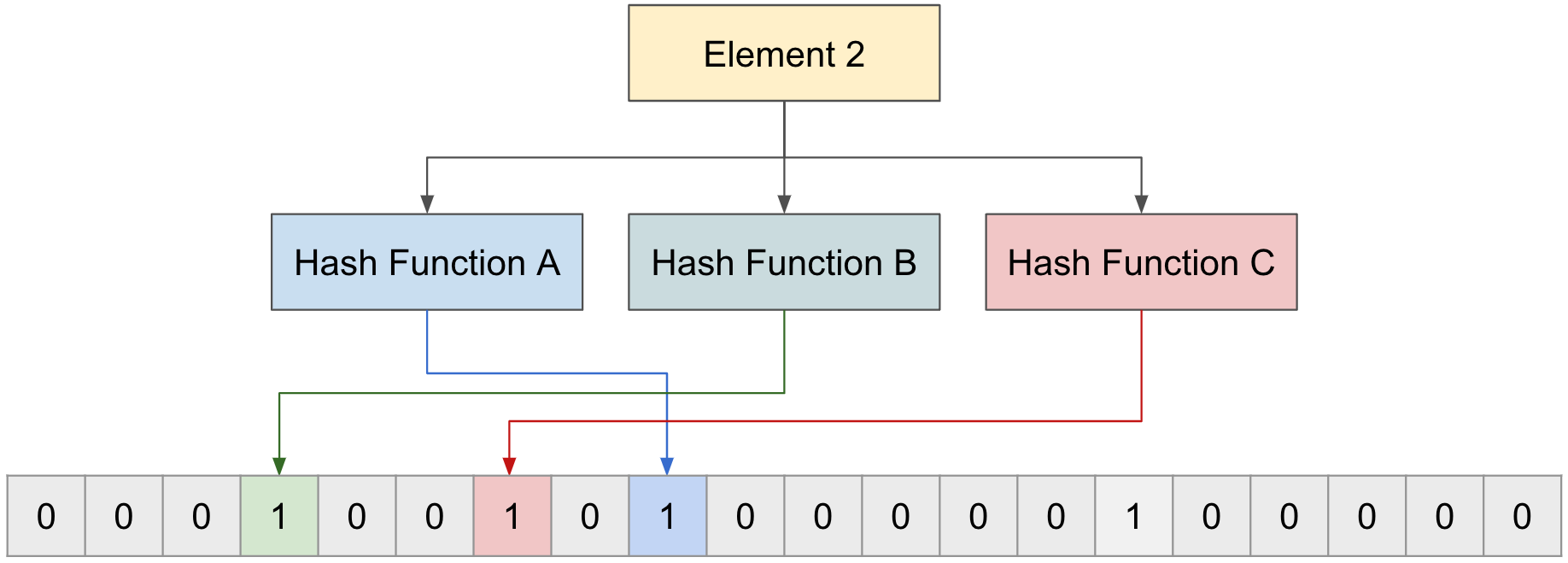
For the second value, “Element 2”, it does the same: gets indexes through three functions and changes the values at those indexes from 0 to 1.
Checking a New Element in a Bloom Filter
To check whether “Element 3” exists, pass it through three functions.
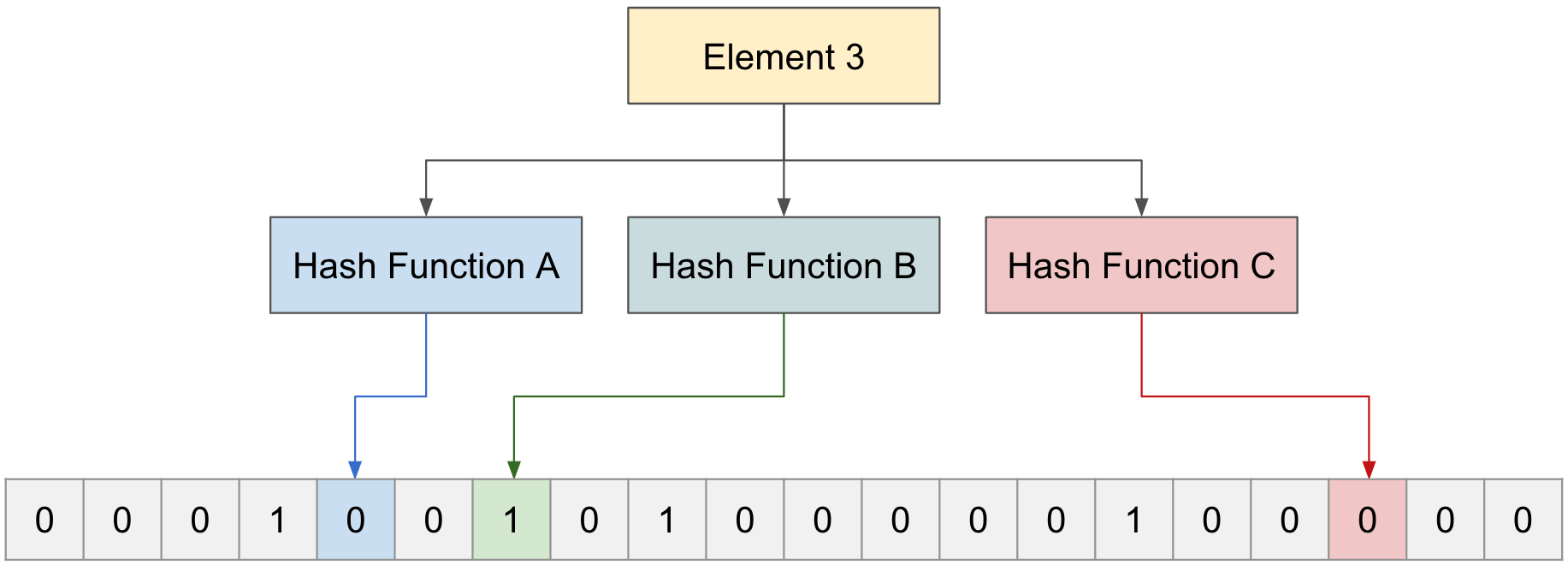
Hash functions A, B, and C point to 0, 1, and 0 respectively. If even one of them includes 0, the input “Element 3” does not exist.
This time, pass “Element 4” through three functions to check whether it exists.
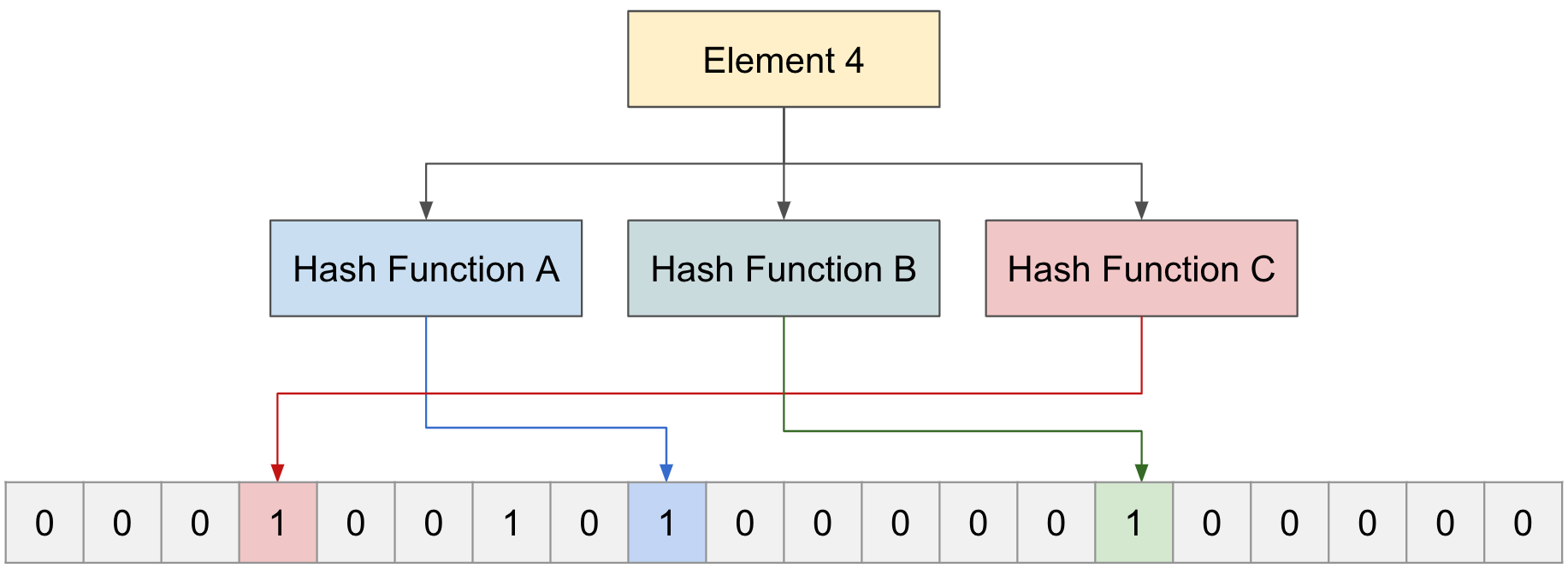
Functions A, B, and C all point to values of 1, but in reality only “Element 1” and “Element 2” exist, and “Element 4” does not.
In this way, a Bloom filter can say with certainty that a non-existing Element does not exist, but for an Element that appears to exist, it can only answer probabilistically and not exactly.
Examples of Using a Bloom Filter
Why use something that is not certain? The reason is that a Bloom filter is very memory efficient and fast.
Let’s look at two cases where Bloom filters are used.
CDN
A CDN stores data requested by many users in CDN servers close to users so that it can be downloaded easily.
The CDN will cache requests. Suppose it immediately caches data on the first request. Then it would cache everything even for resources requested only once, which is inefficient.
According to Akamai, a company in the CDN business, about three-quarters of data is requested only once. The idea they came up with was this: when the first request arrives, mark it only in the Bloom filter and deliver the resource to the user without caching it in the CDN. When the same resource is requested again, the Bloom filter can be checked to see whether it was requested before. This makes it possible to know that the resource has been requested multiple times, and caching begins at that point.
Key Value Store
When fetching a Key from a key-value store, it checks whether the Row exists. If the Key does not exist, every Row may need to be checked, which is the slowest worst case. If the Key exists, it may be found quickly by checking an index, or after looking at the index several times. However, if the Key does not exist, in the worst case all existing indexes and datasets must be checked to confirm that it is absent.
In this worst case, a Bloom filter can be used in preparation for requests for non-existing keys. With a Bloom Filter, you can quickly check whether a Key does not exist or may exist, though a small error is possible.
The following data stores are said to use Bloom Filters.
- Google Bigtable
- HBase
- Redis
- Cassandra
- PostgreSQL