ブルームフィルター(Bloom Filter)データ構造を簡単に説明
ブルームフィルター(Bloom Filter)とは?
ブルームフィルター(Bloom Filter)は効率の良い確率的データ構造である。要素が集合の要素かどうかをテストするために使われる。 ブルームフィルターはバイナリツリーやハッシュマップのように頻繁に使われるデータ構造ではないが、ときどき使われる。
基本的な概念は非常に簡単で、次のような状況でとても有用である。
あるSet(つまり集合)とElementがあるとき、特定のElementがそのSetに存在するかどうかを、ブルームフィルターを使えば素早く知ることができる。特定のElementが特定のSetに存在するかと聞かれたとき、ブルームフィルターは2つの答えを返せる。
- 特定のElementは特定のSet内に存在しない。
- 特定のElementは特定のSet内に存在する可能性がある。
この2つの答えは、Elementがフィルターに存在しないときは確実に知らせることができるが、存在するときは確実ではないことを意味する。
正確ではないにもかかわらず使う理由は、Bloom Filterが空間効率の良いデータ構造だからである。使用するメモリ領域を最初から固定してもよい。 Bloom Filterの要素単位はビットである。32bitマシンでinteger型なら、最大32個の要素を入れられる。
ブルームフィルターの構成
それでは、ブルームフィルターの動作について説明する。ブルームフィルターは1つのビット配列とn個のHash関数で構成される。
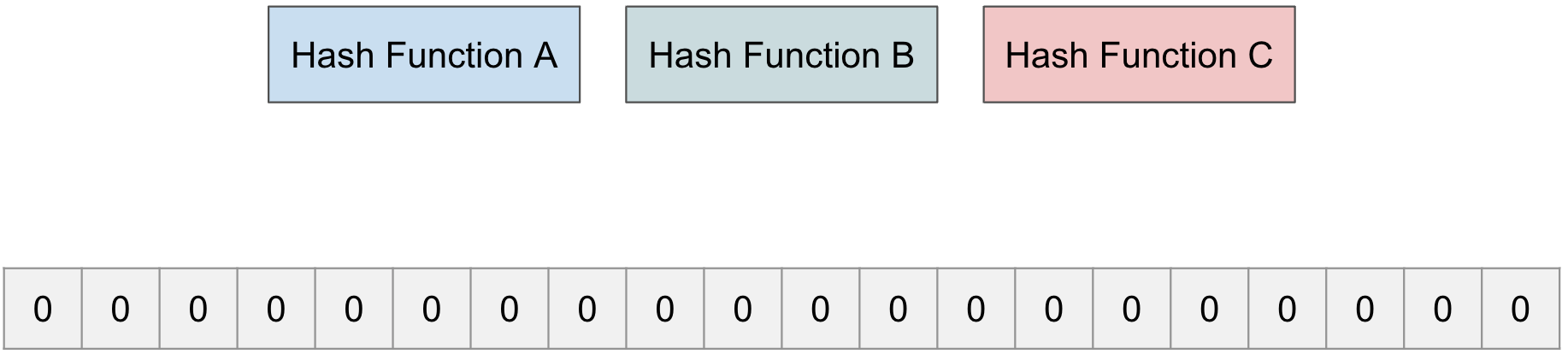
n個のHash関数
Bloom Filterは複数のHash関数を使う。
Hash関数は、ある値を渡したとき、その値を配列のインデックスのうち1つの数字に変換する役割を持つ。
Hash関数の数は複数に設定でき、各関数はHashの方法がそれぞれ異なる。
この関数の機能は以下のとおりである。
- Setに新しいElementを追加する。
- Setに入力したElementが存在するか確認する。
複数の値を持つ配列
ブルームフィルターは複数の値を持つ配列で構成され、ある値をHash関数に通して得たインデックスの値を変更する。
例では、配列サイズ20のBloom Filterを例にする。
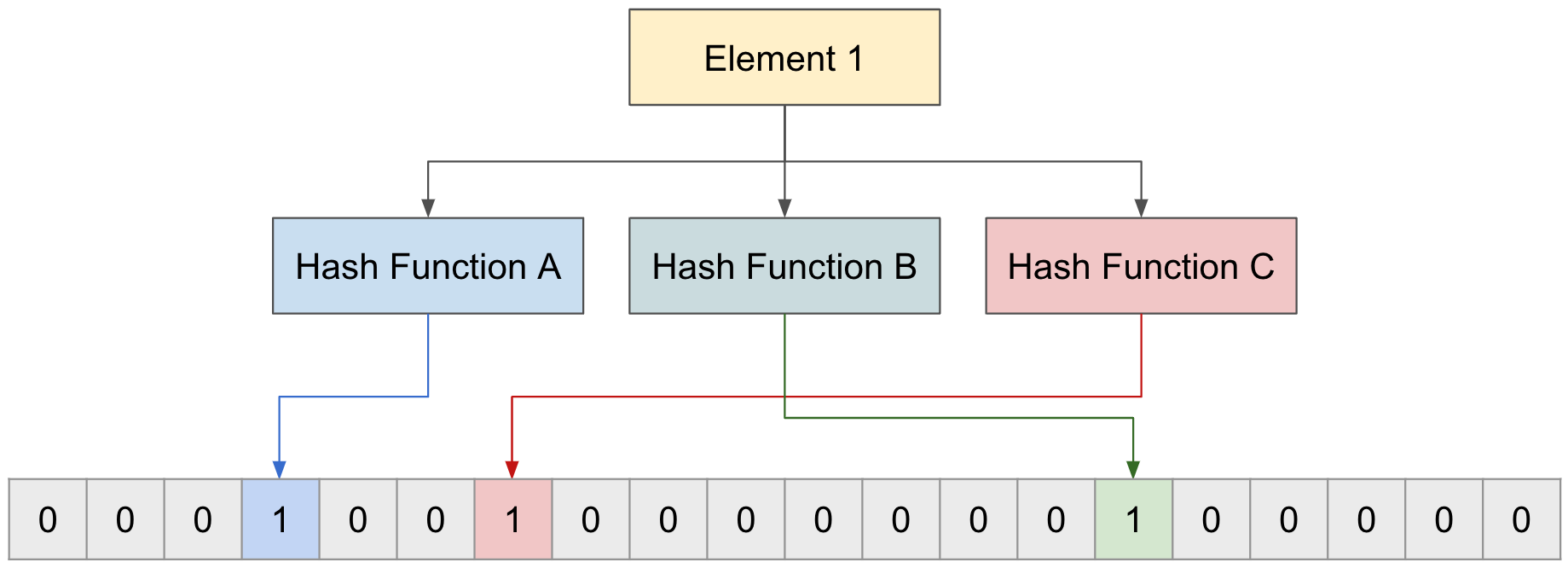
ブルームフィルターに新しいElementを追加
ブルームフィルターに"Element 1"を追加するため、3つの関数それぞれでインデックスを取得し、そのインデックスの値を0から1に変更する。
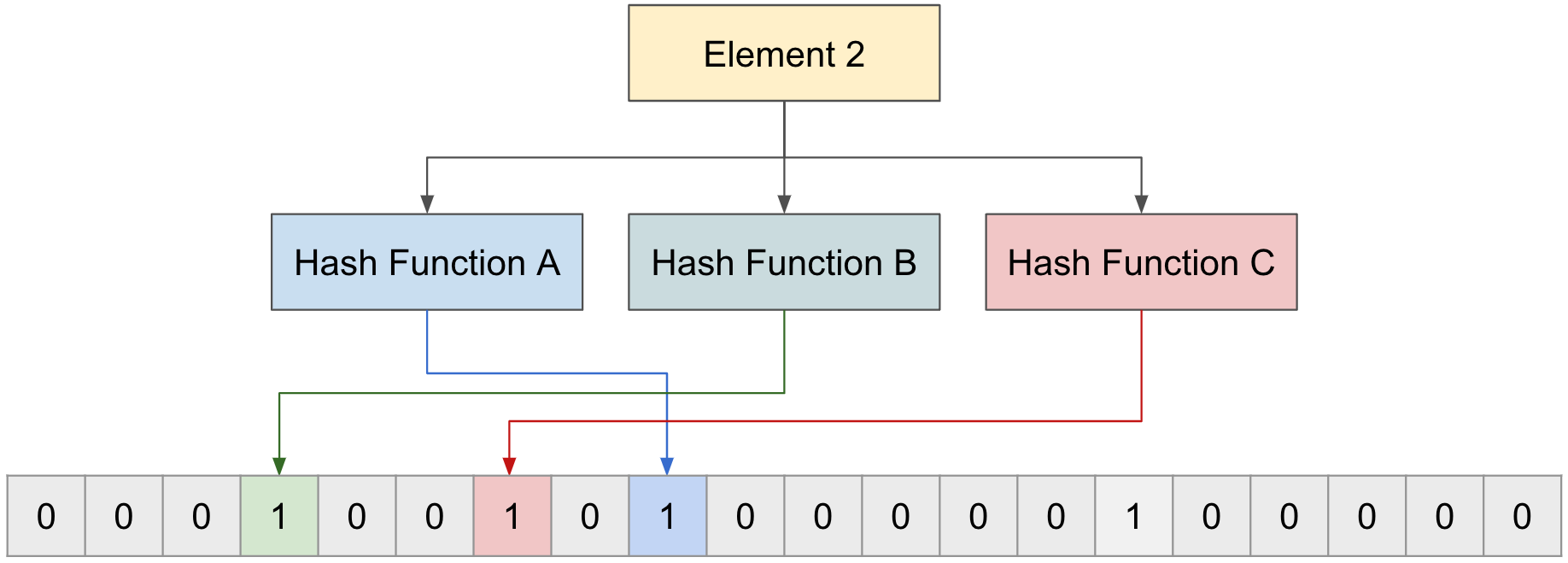
2番目の"Element 2"も同様に、3つの関数それぞれでインデックスを取得し、そのインデックスの値を0から1に変更する。
ブルームフィルターで新しいElementを確認
“Element 3"が存在するか確認するため、3つの関数を通してみる。
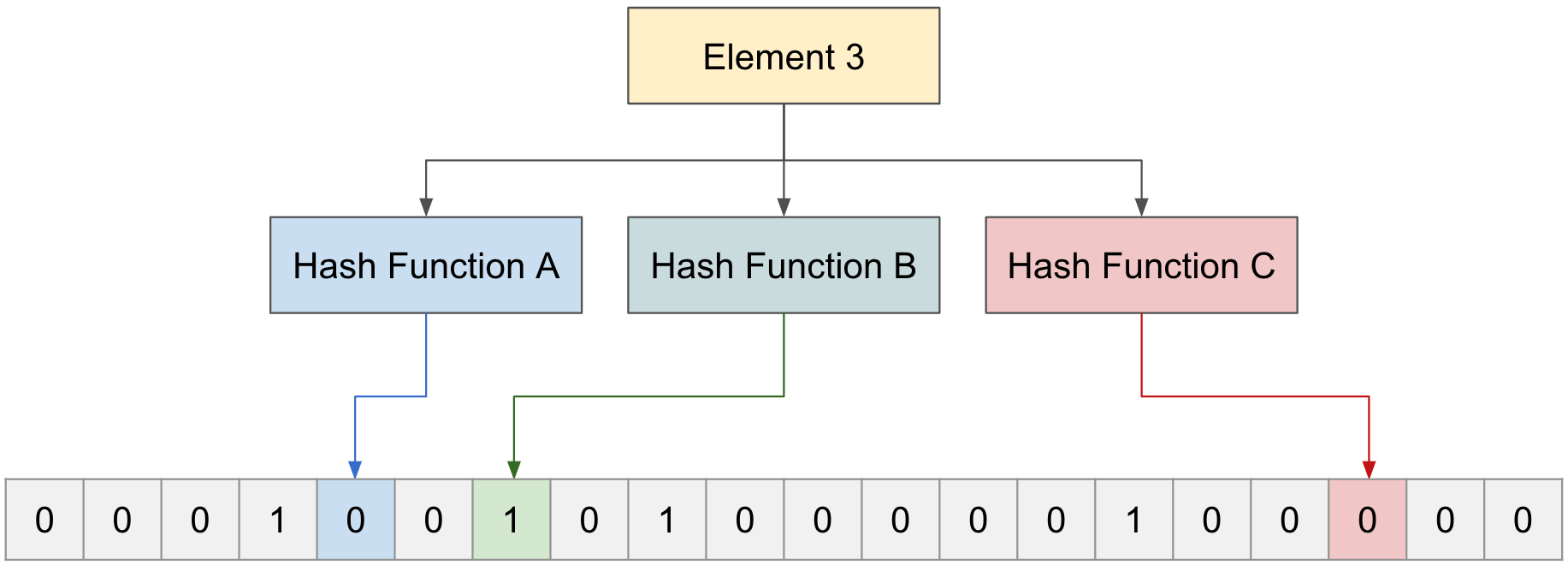
Hash関数A、B、Cでそれぞれ0、1、0を指し、1つでも0を含む場合、入力された"Element 3"は存在しない。
今度は"Element 4"が存在するか確認するため、3つの関数を通してみる。
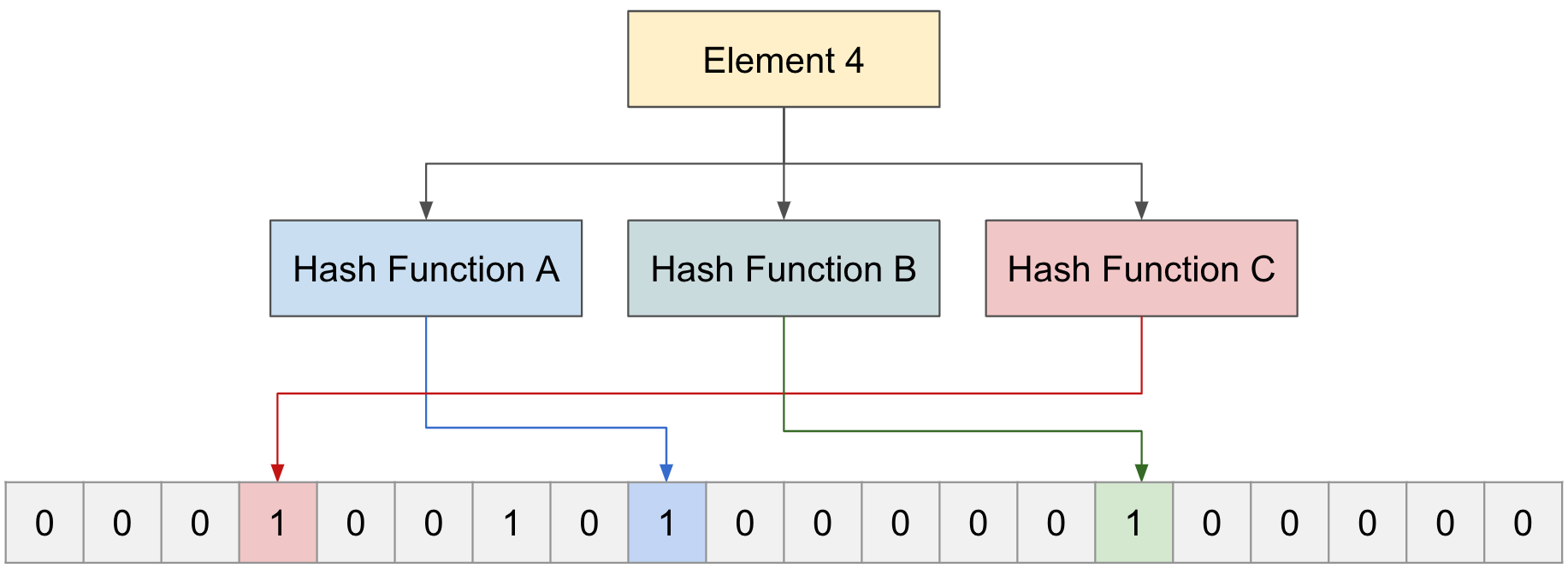
関数A、B、Cはすべて1の値を指しているが、実際には"Element 1,2"だけが存在し、“Element 4"は存在しなかった。
このように、存在しない"Element"については確実に存在しないと知らせられるが、存在するように見える"Element"については確率的に知らせられるだけで、正確ではない。
ブルームフィルターを使う例
では、このように確実ではないのになぜ使うのか。その理由は、ブルームフィルターが非常にメモリ効率的(Efficient)で速いからである。
次に、ブルームフィルターを使う2つのケースを見てみる。
CDN
CDNは、多くのユーザーが要求するデータをユーザーに近いCDNに保存し、ダウンロードしやすくするためのものである。
CDNではリクエストに対するCachingを行うことになるが、最初のリクエストがあったときにすぐキャッシュされると考えてみよう。 そうすると、何度もリクエストされず、1回だけリクエストされる場合でもすべてキャッシュすることになる。これは効率が悪い。
CDN事業を行うAkamaiという会社によると、約4分の3は1回しかリクエストされないデータだという。 そこで考えられた方法が、最初のリクエストが来たときはブルームフィルターにだけ記録しておき、リソースをCDNにキャッシュせずユーザーへ届けるというものだった。 そのリソースが再びリクエストされたとき、ブルームフィルターを確認して以前にリクエストされたものかどうかを確認できる。 これにより、そのリソースが複数回リクエストされることが分かり、その時点からキャッシュするようにしたという。
Key Value Store
Key Value StoreでKeyをfetchするとき、Rowが存在するかどうかを確認することになる。 このとき、Keyがない場合はすべてのRowを確認しなければならないため、最悪の場合は最も遅くなる。なぜなら、存在するKeyはインデックスのような場所を確認したとき、場合によっては確認してすぐにそのKeyを見つけられることもあり、インデックスを何度か見て見つけられることもある。 しかし、そのKeyがなければ、最悪の場合、存在するすべてのインデックスやデータセットを照会して初めて、存在しないことを確信できる。
この最悪の場合、存在しないKeyをリクエストされたときに備えてブルームフィルターを使うことができる。Bloom Filterを使えば、多少のエラーはあり得るが、Keyが存在しないか、存在する可能性があるかを素早く確認できる。
以下のようなデータストアがBloom Filterを使用しているという。
- Google Bigtable
- HBase
- Redis
- Cassandra
- PostgreSQL