Elasticsearch の基本概念
Elasticsearch
- Elasticsearch は Apache Lucene を基盤とし、Java で開発されたオープンソースの検索エンジンである。
- Elasticsearch は、複数のドキュメントやファイルから特定の文字列を検索する分散エンジンである。
- Inverted Index 構造でデータを保存するため、全文検索時に RDBMS より優れた性能を発揮する。
- 通常は単独で使うよりも、ELK スタックとして Logstash、Kibana、Beats を追加して使用する。
- データ保存、ドキュメント検索、位置検索、機械学習ベースの検索、ログ分析、セキュリティ検査分析など、さまざまな用途で使用される。
全文検索
複数のドキュメントやファイルから特定の文字列を検索することを全文検索という。
全文検索技術には grep 型とインデックス型があり、Elasticsearch は複数のコンピューターにインデックス型の全文検索を分散して高速な検索を提供する。
grep 型
複数のファイルを順番に検索する方法である。検索対象が増えるほど検索速度が大きく低下する。UNIX の文字列検索コマンド grep がこれに該当する。
インデックス型
本の索引と同じように、複数のドキュメントにあらかじめインデックスを作成して検索速度を高める方法である。インデックス型の全文検索を利用した例は次のとおりである。
- Elasticsearch ドキュメント検索
- Google 検索: 複数のドキュメント(Web ページ)から特定の文字列を検索
- GitHub コード検索: 複数のドキュメント(ソースコード)から特定の文字列を検索
ここでは、次の 2 つのドキュメントを例にインデックスを作成した場合を紹介する。
- ドキュメント 1: I Like search engine.
- ドキュメント 2: I search keywords by google.
上記のドキュメントで、単語が含まれる場合を 1、含まれない場合を 0 とすると、次のようなインデックスが作成される。
インデックス (Index)
| I | like | search | engine | keywords | by | ||
|---|---|---|---|---|---|---|---|
| ドキュメント 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| ドキュメント 2 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
しかし、このインデックスは左から右への行単位でしか検索できない。そのため、google という単語を使うドキュメントを探すには、すべての行をスキャンする必要がある。
そこで Elasticsearch は、逆インデックス(Inverted index)というインデックスを使用する。逆インデックスは、次のようにインデックスの行と列を入れ替えた逆行列である。
逆インデックス (Inverted index)
| ドキュメント 1 | ドキュメント 2 | |
|---|---|---|
| I | 1 | 1 |
| like | 1 | 0 |
| search | 1 | 1 |
| engine | 1 | 0 |
| keywords | 0 | 1 |
| by | 0 | 1 |
| 0 | 1 |
逆インデックスでは、google という単語が登場するインデックスを検索するには、google の 1 行だけをスキャンすればよい。
インデックスと逆インデックス
Elasticsearch での index は、RDBMS の database に対応する概念である。
- インデックス (index)
- キーワードを見つけやすいように並べた一覧を指す。
- 逆インデックス (Inverted Index)
- キーワードを通じてドキュメントを探し出す方式を指す。
逆インデックス構造の利点は、検索が非常に速いことである。簡単に言えば、本の先頭にある目次が Index に相当し、本の末尾でキーワードごとに探せる索引が Inverted index に相当する。Elasticsearch はテキストを解析して検索語辞書を作成し、逆インデックス方式でテキストを保存する。
Elasticsearch の特徴
Elasticsearch には次のような特徴がある。
- Scale out
- シャードによって水平方向に規模を拡張できる。
- 可用性 (Availability)
- Replica によってデータの安定性を保証する。
- Schema Free
- JSON ドキュメントを通じてデータ検索を行うため、スキーマの概念がない。
- RESTful
- データの CRUD 操作は HTTP RESTful API を通じて行う。
Elasticsearch の用途(活用事例)
内部および外部ドキュメント検索
社内文書やサービス文書などを検索するために使用する。企業での活用事例は次のとおりである。
- Wemakeprice: 販売製品を検索できるオンライン Web ストア(製品カタログ、在庫保存、自動補完など)
- GitHub: ソースコード検索
異常検知
アクセスログなどから異常を検知する。企業での活用事例は次のとおりである。
- Wemakeprice: 機械学習による非定型脅威検知
- 11 番街: モニタリングおよび異常検知
- Netflix: セキュリティログモニタリング
- Elasticsearch in Netflix from Danny Yuan
Elasticsearch と RDBMS の比較
リレーショナル DB とは次のように対応する。
| Relational Database | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Index | Analyze |
| Primary key | _id |
| Schema | Mapping |
| Physical partition | Shard |
| Logical partition | Route |
| Relational | Parent/Child Nested |
| SQL | Query DSL |
出典: https://www.slideshare.net/deview/2d1elasticsearch
インデックス構造の違い
- Elasticsearch
- Inverted-Index 構造でデータを保存する。
- 本の索引のように、特定の単語が含まれるドキュメントを保存する方式である。
- RDBMS
- B-Tree またはそれに類似したインデックスを使用する。
Elastic Stack
Elastic Stack は、Elasticsearch と次の 3 つのオープンソースプロジェクトで構成される。Elasticsearch は検索のために単独で使用されることもあるが、ELK スタックとして使用されることが多い。
Logstash、Kibana とともに使用され、一時期 ELK Stack(Elasticsearch、Logstash、Kibana)として広く知られるようになった Elastic は、2013 年に Logstash、Kibana プロジェクトを正式に取り込み、同じ屋根の下で一緒に開発を進めている。2015 年には会社名を Elasticsearch から Elastic に変更し、ELK Stack の代わりに製品名を Elastic Stack と正式に命名しながら、モニタリング、クラウドサービス、機械学習などの機能を継続して開発、拡張している。 公式文書からの抜粋
Logstash
- Elasticsearch に送るデータ形式を変換するツールである。ETL ツールの Transform、Load 部分を担当する。
- アプリケーションサーバーから Elasticsearch サーバーへログを転送するとき、適切なデータ形式に変換するために使用される。
- さまざまなソース(DB、CSV ファイルなど)のログまたはトランザクションデータを収集、集計、解析し、Elasticsearch へ渡す。
Beats
- データを転送する Shipper である。ETL の Extract を担当する。
- アプリケーションサーバーから Logstash または Elasticsearch へデータを送る。
Elasticsearch
- Logstash から受け取ったデータを検索、集計し、必要な関心情報を取得する。
Kibana
- Elasticsearch の高速検索を通じてデータを可視化、モニタリングする。
- Elasticsearch のドキュメントを可視化する、いわゆる BI ツールである。
Elasticsearch アーキテクチャ
Elasticsearch のアーキテクチャは、次の 2 つに分けられる。
- 論理的概念(ソフトウェア観点の用語)
- 物理的概念(ハードウェア観点の用語)
論理的概念
Elasticsearch の論理的概念の全体図は次のとおりである。
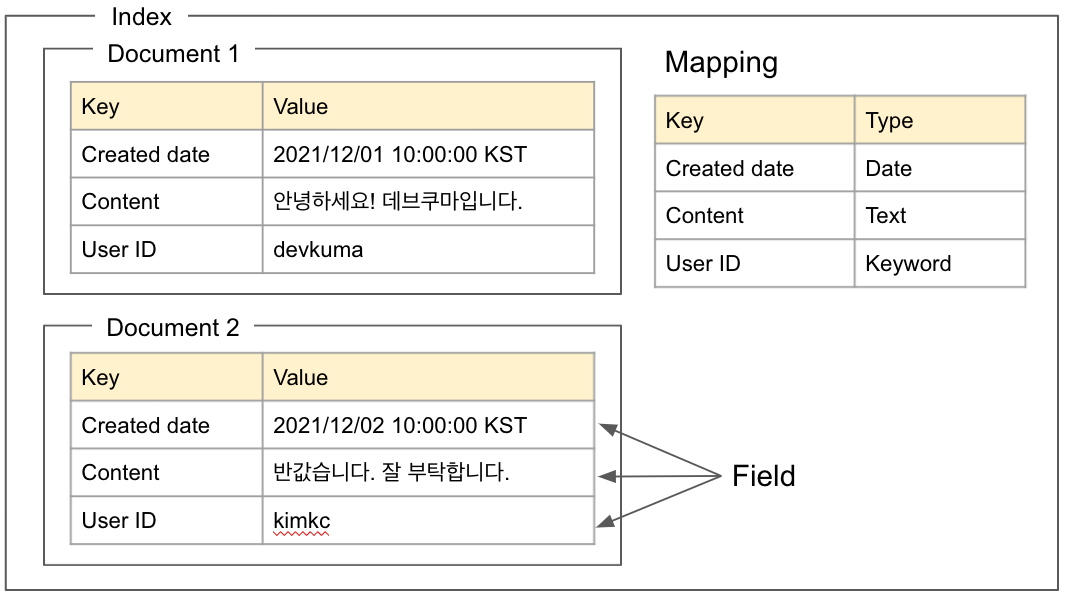
論理的概念図
次に各用語について説明する。
フィールド (Field)
項目名(Key)と値(Value)の組である。ファイルシステムでいう「ファイルの内容」に相当する。それぞれの Key は型(Type)を持つ。
- 文字列を表す
text型 - 時間を表す
date型など
ドキュメント (Document)
フィールドの集合をドキュメントという。ファイルシステムでいう「ファイル」に相当する。ドキュメントは JSON オブジェクトである。
インデックス (Index)
ドキュメントの集合をインデックスという。ファイルシステムでいう「フォルダー」に相当する。ドキュメントをインデックスに保存するとき、逆インデックスを作成する。
マッピング (Mapping)
各フィールドの Key に対する値のデータ型などを定義するものである。マッピングは 1 つのインデックスに 1 つ存在する。
上記の「論理的概念図」で説明されたマッピングでは、Content キーが Text 型として定義されているため、Content キーの値は常に Text 型の文字列になる。
物理的概念
Elasticsearch の物理的概念の全体図は次のとおりである。また、論理的概念であるインデックスとの関係もあわせて表現されている。
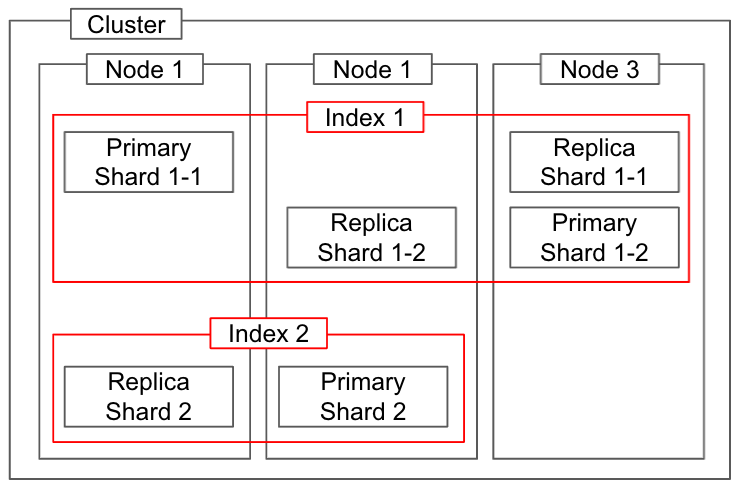
物理的概念と論理的概念の関連
ノード (Node)
ノードは Elasticsearch を構成する 1 つの単位プロセスを意味し、1 つの Elasticsearch サーバーである。
1 つの OS 上で複数の Elasticsearch ノードを起動できる。
ノードには役割に応じて次の 4 種類の属性があり、1 つのノードが複数の属性を持つことも可能である。
- マスターノード (Master Node)
- クラスターメタデータなどを管理するノードである。
- マスターノードはクラスターごとに 1 つだけ存在する。
- マスターノードへ昇格可能なノードは Master-eligible と呼ばれるが、Master ノードではない。
- データノード (Data Node)
- 実データを保存するノードである。
- リクエスト処理(検索および集計など)を実行する。
- リクエストを他のノードへルーティングする(例: 他のノードにシャードがある場合)。
- インジェストノード (Ingest Node)
- データ変換および加工を行い、Data ノードに保存する。
- Logstash と同じ役割を担う。
- コーディネートノード (Coordinating Node)
- リクエストルーティング(Data ノードでも可能)の役割を担う。
- Data ノードにルーティング作業の負荷をかけたくない場合に、ルーティング処理専用ノードとして用意するノードである。
クラスター (Cluster)
Elasticsearch でクラスターは最大のシステム単位を意味し、少なくとも 1 つ以上のノードからなるノード群である。クラスターに検索処理リクエストを投げると、各ノードに検索処理が分散される。
異なるクラスターはデータのアクセスや交換ができない独立したシステムとして維持され、複数台のサーバーが 1 つのクラスターを構成することも、1 台のサーバーに複数のクラスターが存在することもできる。
コンピュータークラスターとは、複数台のコンピューターが接続され、1 つのシステムのように動作するコンピューター群をいう。
シャード (Shard)
論理的概念として紹介した「インデックス」のデータを分割し、ノードに保存したデータである。これにより、検索プロセスを各ノードに分散できる。シャードの実体は Lucene インデックスファイルである。
シャードには次の 2 種類が存在する。
- プライマリシャード (Primary shard)
- データの原本である。
- 最初に更新処理を行うシャードである。
- レプリカシャード (Replica shard)
- プライマリシャードのコピーである。
- プライマリシャードの更新が終わると複製される。
- 検索負荷の分散やデータのバックアップとして使用される。
シャード (Shard) とレプリカ (Replica)
シャードとレプリカは Elasticsearch だけに存在する概念ではなく、分散データベースシステムにも存在する概念である。
- シャード (Shard)
- シャーディングはデータを分散して保存する方法を意味する。つまり、スケールアウトのために index を複数の shard に分割する。
- 基本的に 1 つ以上存在し、検索性能向上のためにクラスターのシャード数を調整するチューニングを行うこともある。
- 単一ノードに保存できるデータ量には制限がある。
- クラスターで単一インデックスのデータを分割し、クラスターのストレージ、メモリ、処理容量を自然に活用できる。
- デフォルトではシャード数は 5 に設定され、インデックス作成時点でインデックスのデータを分割するシャード数を指定できる。インデックスを作成した後は、シャード数を変更できない。
- レプリカ (Replica)
- Replica は別の形の Shard と見なすことができる。
- 障害発生時にも問題なく実行できるよう Replica(コピー)を用意し、障害を解決できる。つまり、ノードを失った場合のデータ信頼性のためにシャードを複製する。そのため、Replica は異なるノードに存在することが推奨される。
- インデックスの各シャードは 0 個以上のレプリカを持つことができる。
- まとめ
- Elasticsearch の最小単位はノードであり、このノードはデータを保存してクエリを実行する。
- ノードが 1 つ以上集まってクラスターを構成する。
- ノード内部ではシャードによってデータをより効率的に管理でき、障害状況の発生を考慮してレプリカを追加構成することで、フェイルオーバーおよびデータ可用性を高められる。
- 高可用性(Availability)とは、サーバー、ネットワーク、プログラムなどの情報システムが正常に使用可能な程度をいう。稼働率と似た意味である。