HBase データモデル
データ構造
HBase テーブルには型がなく、バイト配列(byte[])として保存される。
HBase の行は一意な行キーで昇順にソートされ、テーブルの値を読み書きするときはこの行キーを通じて行われる。
前述したように、HBase が管理するデータは一定範囲ごとにリージョンという単位で分割され、テーブルには複数のリージョンがある。
また、HBase の列は Column Family という単位でグループ化される。
テーブルのデータはリージョンごとに分かれ、Column Family ごとに分かれてファイルへ出力される。
ファイルは別々だが、同じリージョンであれば同じ Region Server に保存される。
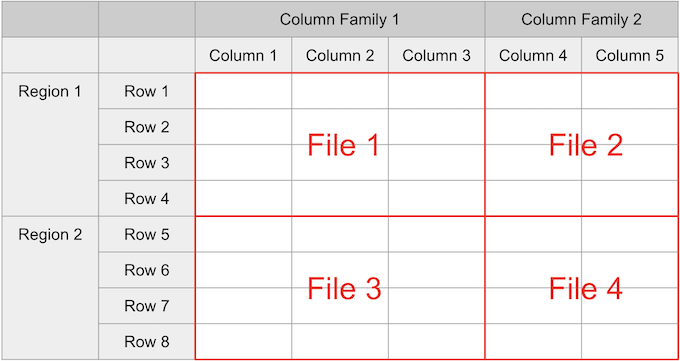
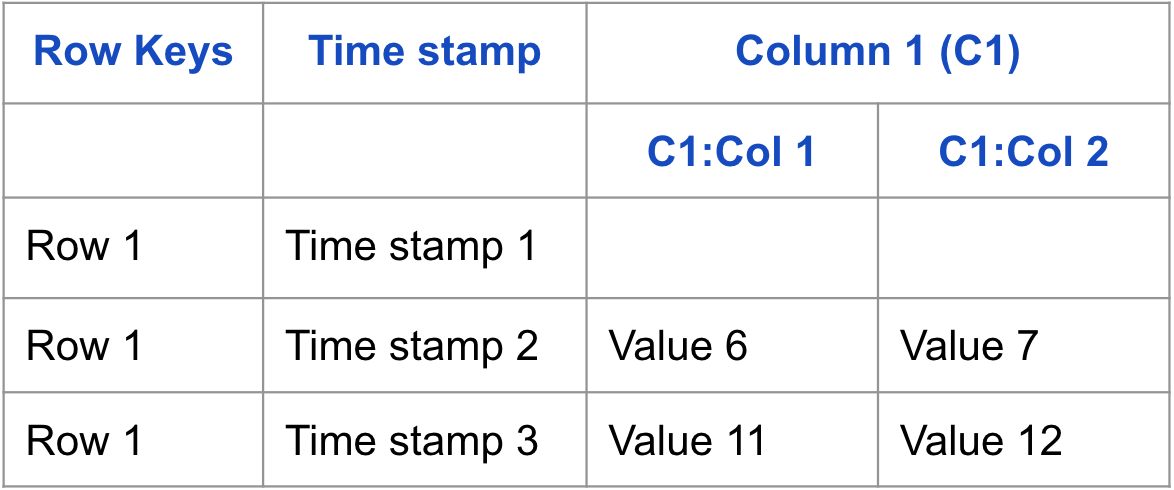
HBase データ、つまりセル値にはそれぞれ timestamp が付与されており、バージョンが管理されている。 ファイルは次の形式で保存される。
Row(Row Key): Column family: Column: timestamp: 値
データモデル
Apache HBase データモデルは、列(Column) key、行(Row) key、および timestamp によってインデックスが作成される分散型、多次元型、永続型、ソート済みの map であり、これが Apache HBase が key-value ストレージシステムとも呼ばれる理由である。
HBase の基本単位は Column であり、この Column が集まって Column Family を構成し、この Column Family が集まってテーブルを構成する。テーブルに入る各 Row は Row Key を持ち、識別できる。以下の図を見てみよう。
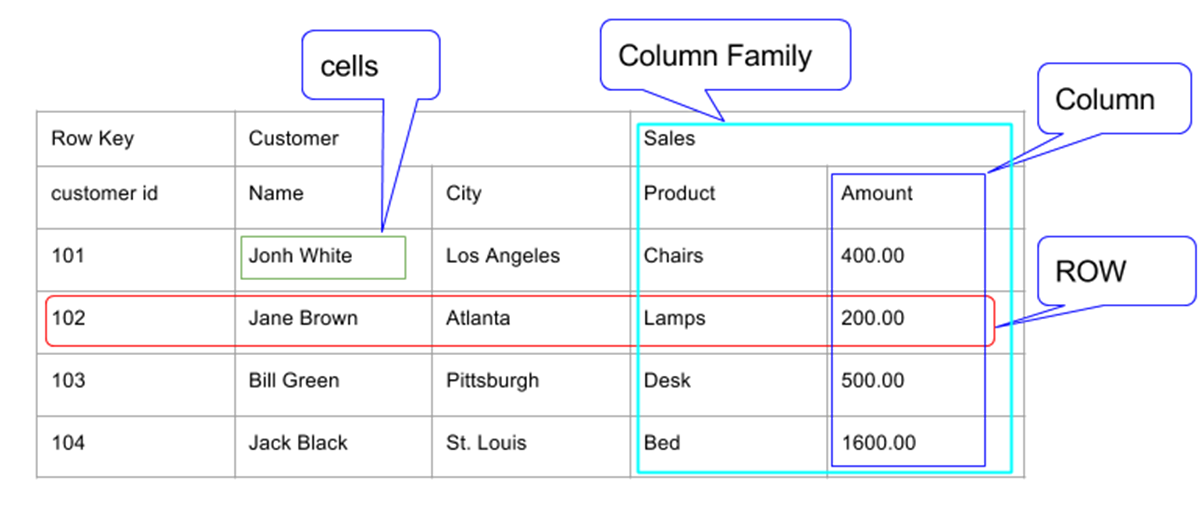
- このテーブルは Customer と Sales の2つの Column Family を持つ。
- Customer Column Family は Name と City の2つの Column を持つ。
- Sales Column Family は Product と Amount の2つの Column を持つ。
- Row は Row Key、Customer CF、Sales CF で構成される。
次は Apache HBase で使用されるデータモデル用語である。
Table
Apache HBase テーブルは複数の Row で構成される。文字で構成され、ファイルシステムと一緒に使用しやすいテーブルとしてデータを構成する。
- Row の集合。Row Key があり、多数の column family で構成される。
- Schema 定義では Column Family のみを定義する。
Row
Apache HBase は行(Row)を基準にデータを保存し、各行には一意な Row Key がある。Row Key はバイト配列で表される。
Row Key
Row Key を基準にデータが集まるため、Row Key は適切にデータが分散されるよう設計する必要がある。Row Key 設計の目標は、似た Row が互いに近くなる方式でデータを保存することである。
- 任意の Byte 列として辞書順にソートされる。
- 空の Byte 文字列はテーブルの開始と終了を意味する。
- 文字列、整数バイナリ、シリアライズされたデータ構造まで、どのようなものでも Row Key になり得る。
一般的に Row Key パターンは Web サイトドメイン形式で構成することもできる。org.apache.mair、org.apache.jira のようにドメインを逆順に保存すると、apache ドメインは近い位置にデータを保存できる。
Column
Column Family と Column Qualifier で構成される。
Column Family
Column Family は Row を保存するために使用され、Apache HBase にデータを保存する構造も提供する。
文字と文字列で構成され、ファイルシステムパスと一緒に使用できる。テーブルの各行は同じ column family を持つが、すべての column family に行を保存する必要はない。
Column Qualifier
Column Qualifier は Column Family に保存されたデータに対するインデックスを提供する。Column qualifier は固定値ではないため、さまざまなデータを入力できる。map オブジェクトと考えられる。
- Column のグループであり、すべての ColumnFamily の Member は同じ prefix を使用する。
- NOSQL:Cassandra と NOSQL:HBASE は NOSQL という Column Family の member column である。
- ColumnFamily prefix は必ず表示可能な文字で構成する。
- テーブルスキーマで定義の一部を先に指定する必要がある。
- すべての ColumnFamily member は物理的にファイルシステムで一緒に保存される。
- 新しい ColumnFamily member は動的に追加可能である。
Cell
Cell は Column family、Row key、Column qualifier で構成されるデータ単位であり、各 Column の値を Cell という。
データ Cell には value(値)と timestamp(値のバージョン)を含む。timestamp があるため、以前の値も一緒に保存され、一定期間その値を保持する。
- ROW KEY、Column、Version が明示された tuple。
- 値は任意の Byte 列であり Timestamp。
- テーブル Cell はバージョン管理される。Cell のみである。
Timestamp
Cell に同じデータが保存された値にはバージョンが指定され、各バージョンは生成時間に割り当てられたバージョン番号で識別される。データを書き込むときに Timestamp を明示しなければ、現在時刻が指定される。
HBase データ型(Data Types)
Apache HBase にはデータ型の概念がない。すべてバイト配列である。値が挿入されると、Put および Result インターフェースを使用してバイト配列へ変換される、一種の byte-in and byte-out データベースである。Apache HBase はシリアライズフレームワークを使用して、ユーザーデータをバイト配列へ変換する。
Apache HBase Cell には最大 10から15MB の値を保存できる。値がより大きい場合は Hadoop HDFS に保存し、ファイルパスメタデータ情報を Apache HBase に保存できる。
HBase データストア
次は Apache HBase の物理的に保存される形式について紹介する。
概念的観点
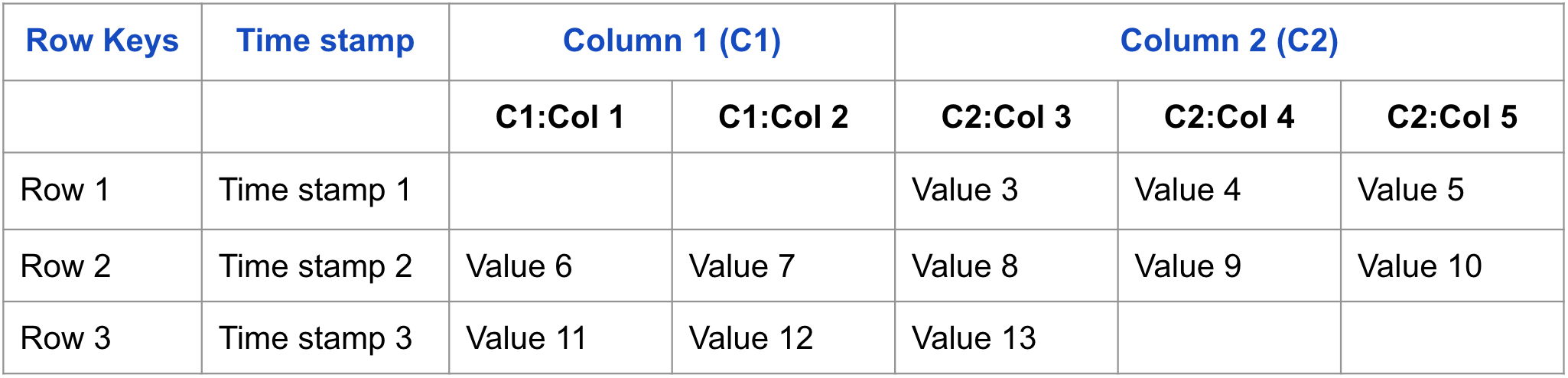
テーブルが概念レベルで一連の Row として表示されることがわかる。
次はデータが HBase に保存される方式の概念図である。
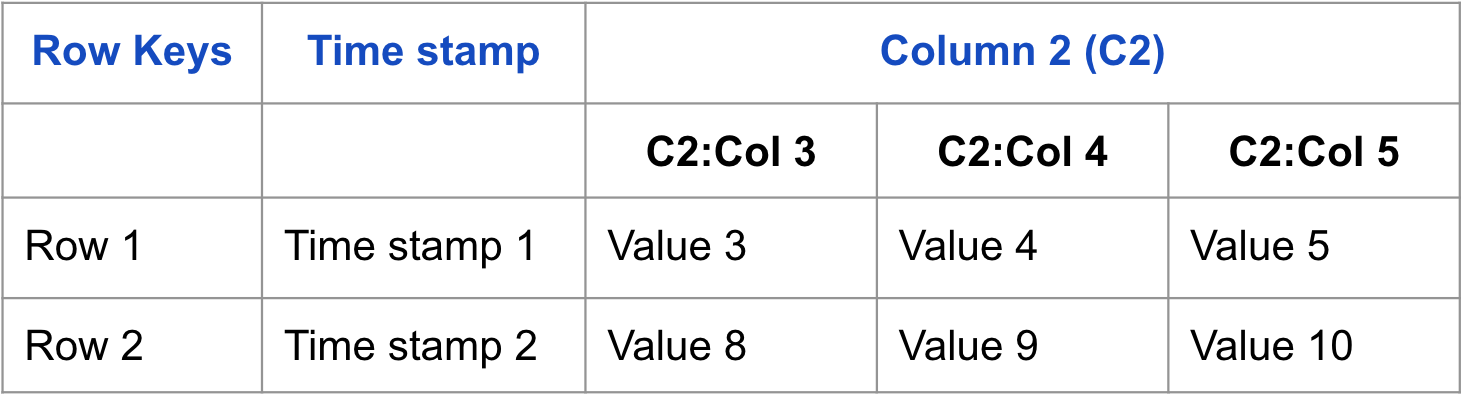
物理的観点
Physical view テーブルは column family によって物理的に保存される。
次の例は、Column Family ベースのテーブルとして保存されるテーブルを表す。
ネームスペース
ネームスペースはテーブルの論理グループである。関連テーブルをグループ化するリレーショナルデータベースに似ている。
ネームスペースの表現を見てみよう。
HBase Namespaces
- Table
- Region Server Group
- Permission
- Quota
ネームスペース空間の各構成要素を見てみよう。
Table
すべてのテーブルはネームスペースの一部である。定義されたネームスペースがなければ、テーブルは default ネームスペースに割り当てられる。
RegionServer group
ネームスペースに対するデフォルト RegionServer group を持つことができる。この場合、作成されたテーブルは RegionServer の構成員になる。
Permission
ネームスペースを使用して、ユーザーは読み取り、削除、更新権限などのアクセス制御リストを定義でき、書き込み権限を使用してテーブルを作成できる。
Quota
この構成要素は、ネームスペースがテーブルおよびリージョンに対して含められる割り当て量を定義するために使用される。
事前定義された namespaces
事前定義された2つの特殊ネームスペースがある。
- hbase: HBase 内部テーブルを含めるために使用されるシステムネームスペースである。
- default: このネームスペースは、ネームスペースが定義されていないすべてのテーブルのためのものである。
データモデル操作
主要な作業データモデルは Get、Put、Scan、Delete である。これらの操作を使用してテーブルからレコードを読み、書き、削除できる。
各操作を詳しく見てみよう。
Get
Get 操作はリレーショナルデータベースの Select 文に似ている。HBase テーブルの内容を取得するために使用される。
以下のように HBase Shell で Get コマンドを実行できる。
hbase(main) :001:0> get 'table name', 'row key' <filters>
Put
Put 操作はテーブルにデータを書き込むために使用される。
Scan
Scan 操作はテーブルの複数行を読むために使用される。読み取る行集合を指定する必要がある Get とは異なる。Scan を使用すると、行範囲またはテーブルのすべての行を反復できる。
Delete
Delete 操作は HBase テーブルから行または行集合を削除するために使用される。HTable.delete() によって実行できる。
削除コマンドが実行されると削除マークで表示され、compaction が発生すると該当行がテーブルから最終削除される。
内部削除の種類は以下のとおりである。
- Delete: 特定バージョンの Column に使用される。
- Delete column: すべての列バージョンに使用できる。
- Delete family: 特定 ColumnFamily のすべての列に使用される。