HBase ブルームフィルター(BloomFilter)
BloomFilter とは?
BloomFilter は、1970年に Bloom が提案した多重ハッシュ関数マッピングのための高速検索アルゴリズムである。 このアルゴリズムは、一般的に要素が集合に属するかどうかを素早く判断する必要がある状況で使用されるが、厳密に100%正確である必要はないという考えから始まっている。
詳しい理論は わかりやすく説明するブルームフィルター(Bloom Filter)データ構造 ページを参照すること。
HBase BloomFilter
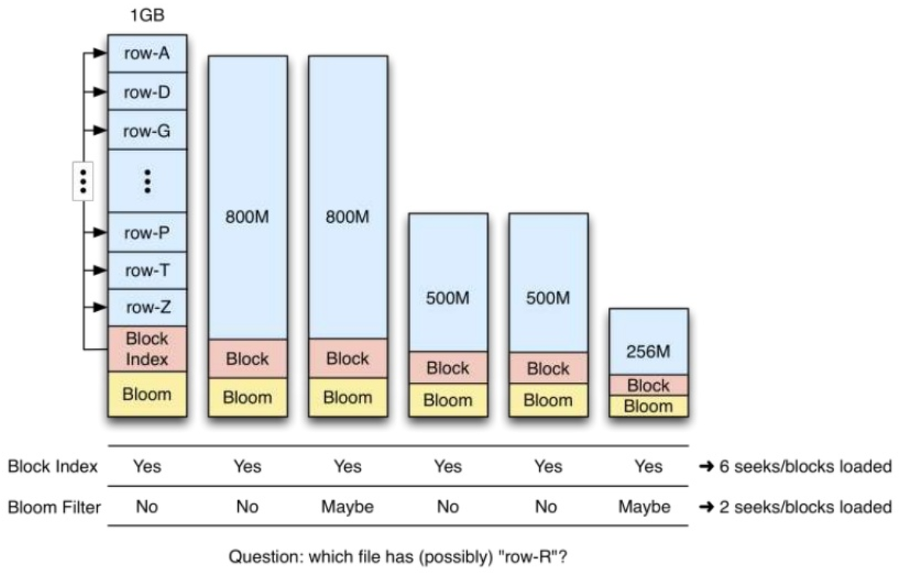
HBase の BloomFilter のデータは StoreFile のメタデータに保存され、一度作成されると StoreFile は変更できないため更新できない。
BloomFilter は Column family レベルの構成属性である。テーブルに BloomFilter が設定されている場合、HBase は MetaBlock と呼ばれる StoreFile を作成するときに BloomFilter 構造のデータ断片を含める。 MetaBlock および DataBlock(実際の KeyValue データ)は LRU BlockCacheMaintenance で一緒に使用される。
したがって、BloomFilter を設定すると、特定のストレージおよびメモリキャッシュのオーバーヘッドが発生する。
HBase BloomFilter の設定方法
特定の Row key を含んでいるかを探索するとき、既存のブロックインデックスに比べて不要なブロックロードを減らし、クラスター全体のスループットを改善する。
セルサイズ、セル数、データ保存方式、読み取り方式などに応じてブルームフィルターを選択する必要がある。
HBase ドキュメントによれば、ほとんどの場合 BloomFilter の使用が推奨されている。
BloomFilter には NONE(デフォルト)、ROW、ROWCOL の3つのパラメータがある。
ROW: KeyValue の行(Row)を基準に StoreFile をフィルタリングする行レベル Bloom フィルターを示す。ROWCOL: KeyValue の行(Row) + 列(Column)に従って StoreFile をフィルタリングする列レベル Bloom フィルターを示す。
したがって、ROWCOL の空間オーバーヘッドは ROW より高い。
該当リージョンに StoreFile が多いほど BloomFilter の効果は高く、リージョンの StoreFile 数が少ないほど HBase の読み取り性能は向上する。
次のように BloomFilter コマンドを有効にするため、HBase で Column family を設定する。
create 't1',{name => 'c1', BLOOMFILTER => '<ROW または ROWCOL>'}