HBase 圧縮、コンパクション、およびデータブロックエンコーディング
圧縮とコンパクション
HBase RegionServer に保存される Region には、Column Family ごとに HStore があり、HStore はその CF の MemStore と HFile で構成される。
MemStore はメモリ上の Column Family データであり、HFile はローカルディスク、つまり HDFS に保存される Column Family データである。このような階層構造になっている理由は、HBase のテーブル構造上、データを Row key でソートする必要があり、ディスクへ直接書き込むのではなく、まずメモリ上でソートする必要があるためである。
HBase で put や update などの書き込み処理が行われると、データはまず WAL (Write Ahead Log) に記録され、その後 MemStore に書き込まれる。scan などの読み取り処理では、まず MemStore を確認し、次に HFile から要求された内容を検索する。
書き込みが繰り返されて MemStore のデータサイズが設定されたしきい値を超えると、MemStore のデータは HFile として保存される。多くの HFile で構成された Region では、HFile が増えるにつれてコンパクションが発生し、複数の HFile がより大きな HFile にマージされる。その結果、多数の小さな HFile は、少数の大きな HFile に整理される。この処理をコンパクションと呼ぶ。
HBase のコンパクションは、Minor Compaction と Major Compaction として実行される。
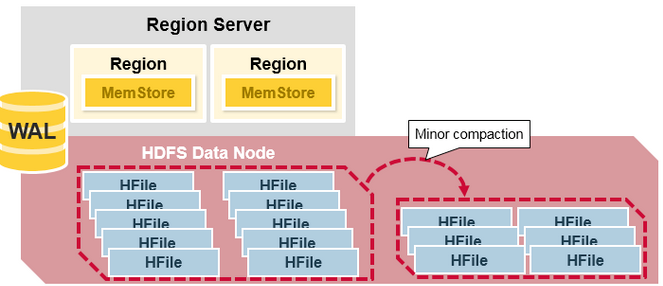
Minor Compaction
- Minor compaction は、最近作成された複数の小さなファイルを、設定されたより大きな HFile サイズへマージする処理である。
- データが挿入されると、小さな HFile が多数作成される。ファイル数が多すぎると性能が低下する可能性があるため、HBase は複数の HFile を少数の大きな HFile に作り直し、HFile 数を自動的に管理する。
- HFile に保存されたデータはソートされているため、マージソートを使って高速にマージできる。
Major Compaction
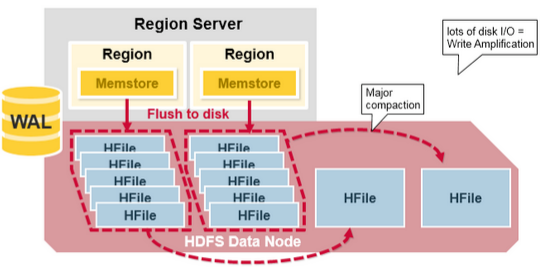
- Major compaction は、特定 Region 内の Column Family に属するすべての HFile を集め、Column ごとに 1 つの HFile を作成する。デフォルトでは 7 日に 1 回実行される。
- この処理中に不要な Cell や期限切れの Cell が削除され、全体的な読み取り性能が改善される。Tombstone Marker が付いたデータも、この時点で最終的に削除される。
- この作業が実行されると、大量のファイル読み書きが発生するため、ディスク I/O とネットワークトラフィックが増加する可能性がある。
- 自動実行をスケジュールできるため、週末や夜間に実行するように設定し、急激な I/O 増加がサービスに与える影響を最小化できる。
コンパクション設定
Minor compaction では、コンパクション対象となる HFile 数を次の設定で指定する。
hbase.hstore.compaction.min- Minor compaction の最小 HFile 数を設定する。
- デフォルトは 3 で、2 以上に設定する必要がある。
- 値が大きすぎると Minor compaction が遅延し、後でまとめて処理される際に負荷が発生する可能性がある。
hbase.hstore.compaction.max- Minor compaction の最大 HFile 数を設定する。
次の設定では、コンパクション対象となる HFile サイズを指定する。
hbase.hstore.compaction.min.size: この値より小さい HFile は、ExploringCompactionPolicy によって Minor compaction を検索するとき常に含まれる。この値はhbase.hstore.compaction.ratioと併用され、コンパクション対象の HFile を選択するために使われる。hbase.hstore.compaction.max.size: このサイズより大きい HFile は Minor compaction から除外される。Minor compaction が頻繁に発生しても効果が小さい場合、この値を小さくして大きなファイルを Minor compaction から除外できる。デフォルト:9223372036854775807, LONG.MAX_VALUE, bytes。
その他の設定:
hbase.hregion.majorcompaction- HBase では、1 つの Region に複数の StoreFile が存在することがある。性能改善のため、定期的にこれらのファイルを集め、より大きな 1 つのファイルにまとめる。この処理では CPU 使用量とディスク I/O が大きく、応答時間が低下する場合がある。そのため、応答時間が重要な場合は、ピーク時間を避けて Major compaction を手動実行する方がよい。
- デフォルトは 86,400,000 ms である。この値を 0 に変更すると、定期的な Major Compaction は実行されない。
hbase.hregion.majorcompaction.jitter- このプロパティのデフォルトは 0.2、つまり 20% である。保存された各ファイルで Major compaction が実行されるタイミングを分散させる。
- これがない場合、Major compaction は 24 時間ごとに同時実行される。
HBase 圧縮およびデータブロックエンコーディング
このセクションで言及する codec は、データブロックまたは row key のエンコードとデコードのためのものである。レプリケーション codec の詳細については、cluster.replication.preserving.tags を参照する。
HBase は、ColumnFamily に対して有効化できる複数の圧縮アルゴリズムをサポートしている。データブロックエンコーディングは、ソート済み row key や対象テーブルのスキーマなど、HBase の基盤設計とパターンを利用して、key 内の情報重複を抑える。Compressor は Cell 内の大きな不透明バイト配列のサイズを削減し、未圧縮データに必要な保存領域を大幅に削減できる。
Compressor とデータブロックエンコーディングは、同じ ColumnFamily で併用できる。
変更はコンパクション中に適用される
ColumnFamily の圧縮またはエンコーディングを変更した場合、その変更はコンパクション中に適用される。
一部の codec は、GZip 圧縮のように Java に組み込まれた機能を使用する。他の codec はネイティブライブラリに依存する。ネイティブライブラリは、HBase ライブラリディレクトリにインストールされた codec 依存関係として提供できるほか、Hadoop codec を使う場合は Hadoop の一部として提供される。Hadoop codec には通常ネイティブコードコンポーネントがあるため、HBase で Hadoop ネイティブライブラリを使用するには、Hadoop native binary support installation instructions に従う。
このセクションでは、HBase で一般的に使用され、テストされている codec について説明する。
どの codec を使用する場合でも、その codec が正しくインストールされ、クラスタ内のすべてのノードで利用可能であることをテストする必要がある。新しくデプロイされたノードで codec の利用可否を確認するには、追加の運用手順が必要になる場合がある。指定した codec が正しくインストールされていることを確認するには、compression.test ユーティリティを使用できる。
HBase で compressor を使用する設定については compressor.install を参照する。ColumnFamily で compressor を有効にする方法については changing.compression を参照する。ColumnFamily でデータブロックエンコーディングを有効にする方法については data.block.encoding.enable を参照する。
Block Compressors
NONE
この圧縮タイプ定数は圧縮なしを選択し、デフォルトである。
BROTLI
- Brotli は汎用の可逆圧縮アルゴリズムである。LZ77 の現代的な変種、Huffman coding、二次コンテキストモデリングを組み合わせ、現在利用できる最良の汎用圧縮方式に匹敵する圧縮率を提供する。速度は GZ と同程度だが、より高密度に圧縮できる。
BZIP2
- Bzip2 は Burrows-Wheeler block-sorting text compression algorithm と Huffman coding を使用してファイルを圧縮する。通常、LZ のような辞書ベース圧縮より圧縮率はかなり良いが、圧縮と展開はいずれも他の選択肢より遅い場合がある。
GZ(GZIP)
- 圧縮率を重視する。
- gzip は、LZ77 と Huffman coding の組み合わせである DEFLATE アルゴリズムに基づいている。このアルゴリズムは Java ランタイム環境で普遍的に利用できるため、最小公分母として使いやすい選択肢である。ただし、Zstandard などの新しいアルゴリズムと比べるとかなり遅い。
LZ4
- 圧縮/展開速度を重視する。
- LZ4 は、圧縮と展開速度を重視した可逆データ圧縮アルゴリズムである。Brotli、DEFLATE、Zstandard と同じく LZ77 系の圧縮アルゴリズムに属する。マイクロベンチマークでは、LZ4 はその系列の中で圧縮と展開の両方が最も高速であり、一般的に推奨される。
LZMA
- LZMA は LZ77 にやや似た辞書圧縮方式である。計算コストの高い予測モデルと可変サイズの圧縮辞書により非常に高い圧縮率を実現しながら、一般的に使われる他の圧縮アルゴリズムと同程度の展開速度を維持する。典型的な圧縮率では LZMA は他のすべての選択肢を上回るが、compressor としては非常に遅く、特に高い圧縮レベルで動作するように設定した場合は遅くなることがある。
LZO
- 圧縮/展開速度を重視し、追加ライブラリのインストールが必要である。
- LZO は、展開速度を重視して実装された別の LZ 系データ圧縮アルゴリズムである。LZ4 ほど速くはないが、それに近い性能を持つ。
SNAPPY
- 圧縮/展開速度を重視する。
- SNAPPY は LZ77 の考え方に基づくが、非常に高速な圧縮速度に最適化されており、その代わり圧縮率は妥当な水準にとどまる。LZ4 と同程度に高速だが、圧縮率はそれほど高くない。HBase は pure Java Snappy codec を提供しており、すべてのハードウェアアーキテクチャ上のすべての Java ランタイムで普遍的に利用できる選択肢として、GZ の代わりに使用できる。
ZSTD
- Zstandard は、辞書マッチング段階 (LZ77) と、大きな検索ウィンドウ、および finite-state entropy と Huffman coding の両方を使用する高速なエントロピーコーディング段階を組み合わせる。圧縮速度は最速レベルと最遅レベルで 20 倍以上異なる場合があるが、展開は一貫して高速で、最速レベルと最遅レベルの差は 20% 未満である。
- ZStandard は、利用可能な圧縮 codec の中で最も柔軟な選択肢である。レベル 1 では LZ4 と同程度の圧縮率を提供し、性能はわずかに低い。中間レベルでは DEFLATE と同程度の圧縮率をより良い性能で提供し、高レベルでは LZMA に似た圧縮速度で LZMA と同程度の高密度圧縮を提供しながら、展開は常に高速である。
データブロックエンコーディングタイプ
HBase は 5 種類のデータブロックエンコーディングを提供する。
- NONE
- Prefix
- Diff
- Fast Diff
- Prefix Tree
None
None はエンコーディングを適用しないことを意味し、デフォルトである。
エンコーディングなしの ColumnFamily
次の表は、データブロックエンコーディングを使用しない仮想的な ColumnFamily を示している。
| Key Length | Value Length | Key | Value |
|---|---|---|---|
| 24 | … | RowKey:Family:Qualifier0 | … |
| 24 | … | RowKey:Family:Qualifier1 | … |
| 25 | … | RowKey:Family:QualifierN | … |
| 25 | … | RowKey2:Family:Qualifier1 | … |
| 25 | … | RowKey2:Family:Qualifier2 | … |
| … | … | … | … |
Prefix
通常、key は同じ prefix を持ち、最後の部分だけが異なることが多い。
たとえば、最初の key が RowKey:Family:Qualifier0 で、次の key が RowKey:Family:Qualifier1 であるとする。Prefix encoding は、現在の key と直前の key の間で共有される prefix の長さを格納する拡張カラムを追加する。この例で、最初の key が直前の key と完全に異なる場合、prefix length は 0 である。2 番目の key の最初の 23 文字が同じであるため、prefix length は 23 になる。
もちろん、2 つの key に共通部分がない場合、Prefix の利点はない。
Prefix encoding を適用した ColumnFamily
次は、同じデータに Prefix data encoding を適用したものである。
| Key Length | Value Length | Prefix Length | Key | Value |
|---|---|---|---|---|
| 24 | … | 0 | RowKey:Family:Qualifier0 | … |
| 1 | … | 23 | 1 | … |
| 1 | … | 23 | N | … |
| 19 | … | 6 | 2:Family:Qualifier1 | … |
| 1 | … | 24 | … | … |
| … | … | … | … | … |
Diff
Diff encoding は Prefix encoding を拡張したものである。Key を 1 つのバイト列として扱うのではなく、各 Key Field に分割し、Key の各部分をより効率的に圧縮できるようにする。
timestamp と type という 2 つの新しいフィールドが追加される。
ColumnFamily が直前の行と同じ場合、現在の行では省略される。key length、value length、type が直前の行と同じ場合、それらのフィールドは省略される。
また、圧縮を改善するため、timestamp は完全な値として保存されず、直前の行の timestamp との差分として保存される。prefix の例で、2 つの row key があり、timestamp が完全に一致し、type も同じである場合、2 番目の行では value length や type を保存する必要がなく、2 番目の行の timestamp 値は完全な timestamp ではなく 0 になる。
write と scan の速度が遅くなるため、より多くのデータをキャッシュできるにもかかわらず、Diff encoding はデフォルトで無効になっている。
Diff encoding を適用した ColumnFamily
この表は、同じ ColumnFamily に Diff encoding を適用したものを示している。
| Flags | Key Length | Value Length | Prefix Length | Key | Timestamp | Type Value | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 24 | 512 | 0 | RowKey:Family:Qualifier0 | 1340466835163 | 4 | … | |
| 5 | - | 320 | 23 | 1 | 0 | - | … | |
| 3 | - | - | 23 | N | 120 | 8 | … | |
| 0 | 25 | 576 | 6 | 2:Family:Qualifier1 | 25 | 4 | … | |
| 5 | - | 3384 | 24 | 2 | 1124 | - | … | |
| … | … | … | … | … | … | … | … |
Fast Diff
Fast Diff は Diff と同じように動作するが、より高速に実装されている。また、データ自体が直前の行と同じかどうかを追跡する 1 ビットを保存するフィールドが 1 つ追加される。同じであれば、データは再度保存されない。
key が長い場合や column が多い場合は、Fast Diff codec を使用する。
データ形式は Diff encoding とほぼ同じであるため、説明用の別画像はない。
Prefix Tree
Prefix Tree encoding は、HBase 0.96 で実験的機能として導入された。Prefix Tree encoding は、Prefix、Diff、Fast Diff encoder と同様のメモリ節約を提供しながら、エンコード速度が遅くなる代わりに、より高速なランダムアクセスを提供する。よいアイデアではあったが、ほとんど使用されず、HBase 2.0.0 で削除された。