Elasticsearch 기본 개념
Elasticsearch
- Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 자바로 개발된 오픈소스 검색엔진이다.
- Elasticsearch는 여러 문서(파일)에서 특정 문자열을 검색하는 분산 엔진이다.
- Inverted Index 구조로 데이터를 저장해서, 전문(Full-text) 검색시에 RDBMS에 띄어난 성능을 보장한다.
- 보통 단독으로 사용하기보다는 ELK 스택이라고 하여, Logstach, Kibana, Beats를 추가적으로 사용한다.
- 데이터 저장, 문서 검색, 위치 검색, 머신 러닝 기반 검색, 로그 분석, 보안 검사 분석 등 다양한 용도로 사용된다.
전체 텍스트 검색
여러 문서(파일)에서 특정 문자열을 검색하는 것을 전체 텍스트 검색 이라고 한다.
전체 텍스트 검색 기술에는 grep 유형과 색인(인덱스) 유형이 있으며, Elasticsearch는 여러 컴퓨터에 색인 유형의 전체 텍스트 검색을 분산하여 빠른 검색을 제공한다.
grep 유형
여러 파일을 순서대로 검색하는 방법이다. 검색 대상이 증가함에 따라 검색 속도가 크게 저하된다. UNIX 문자열 검색 명령 grep이 이에 해당한다.
색인(인덱스) 유형
책의 색인과 마찬가지로 여러 문서에 미리 색인을 작성하여 검색 속도를 높이는 방법이다. 색인 유형의 전체 텍스트 검색을 이용한 예는 다음과 같다.
- Elasticsearch 도큐먼트 검색
- Google 검색 : 여러 문서(웹 페이지)에서 특정 문자열 검색
- GitHub 코드 검색 : 여러 문서(소스 코드)에서 특정 문자열 검색
여기서 다음의 2개의 도큐먼트를 예로 하여 인덱스를 작성했을 경우의 예를 소개하겠다.
- 도큐먼트 1: I Like search engine.
- 도큐먼트 2: I search keywords by google.
위에 도큐먼트에서 도큐먼트에 단어가 포함되는 경우를 1, 포함되지 않는 경우를 0으로 하면, 다음과 같은 인덱스가 작성된다.
인덱스 (Index)
| I | like | search | engine | keywords | by | ||
|---|---|---|---|---|---|---|---|
| 도큐먼트 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 도큐먼트 2 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
그런데 인덱스는 왼쪽에서 오른쪽으로의 행 단위로 밖에 검색할 수 없다. 그러기 때문에 google 이라는 단어를 사용하는 문서를 찾으려면 모든 행을 스캔 해야 한다.
그래서 Elasticsearch는 역 인덱스(Inverted index)라는 인덱스를 사용한다. 역 인덱스는 다음과 같이 인덱스의 행과 열을 바꾼 역 행렬을 말한다.
역 인덱스 (Inverted index)
| 도큐먼트 1 | 도큐먼트 2 | |
|---|---|---|
| I | 1 | 1 |
| like | 1 | 0 |
| search | 1 | 1 |
| engine | 1 | 0 |
| keywords | 0 | 1 |
| by | 0 | 1 |
| 0 | 1 |
역 색인에서는 google이라는 단어가 등장하는 색인을 검색하려면 ‘google’이라는 한 줄만 스캔하면 된다.
색인(Index)와 역색인(Inverted Index)
Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념이다.
- 색인(index)
- 키워드를 찾아보기 쉽도록 정렬/나열한 목록을 말한다.
- 역색인(Inverted Index)
- 키워드를 통해 문서를 찾아내는 방식을 말한다.
역색인의 구조의 이점은 검색이 매우 빠르다는 것이다.
쉽게 말해 책에서 맨 앞에 볼 수 있는 목차가 Index에 해당되고, 책 맨 뒤에 키워드마다 찾아볼 수 있도록 찾아보기가 Inverted index에 해당한다.
Elasticsearch는 텍스트를 파싱해서 검색어 사전을 만든 다음에 역색인 방식으로 텍스트를 저장한다.
Elasticsearch 특징
Elasticsearch는 다음과 같은 특징이 있다.
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있다.
- 고가용성(Availability)
- Replica를 통해 데이터의 안정성을 보장한다.
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없다
- Restful
- 데이터 CURD 작업은 HTTP Restful API를 통해 수행한다.
Elasticsearch 용도 (활용 사례)
내부 및 외부 문서 검색
자사내에 문서나 서비스의 문서 등를 검색하기 위해서 이용한다. 기업에서의 활용 사례는 다음과 같다.
- 위메프: 판매 제품을 검색할 수 있는 온라인 웹 스토어 (제품 카탈로그, 재고 저장 및 자동 완성 등)
- GitHub: 소스 코드 찾기
이상 감지
액세스 로그 등에서 이상을 감지한다. 기업에서의 활용 사례는 다음과 같다.
- 위메프: 머신러닝을 통한 비정형 위협탐지
- 11번가 : 모니터링 및 이상 감지
- Netflix: 보안 로그 모니터링
- Elasticsearch in Netflix from Danny Yuan
Elasticsearch와 RDBMS 비교
관계형 DB와 다음과 같이 대응된다.
| Relational Database | Elasticseach |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Index | Analyze |
| Primary key | _id |
| Schema | Mapping |
| Physical partition | Shard |
| Logical partition | Route |
| Relational | Parent/Child Nested |
| SQL | Query DSL |
출처: https://www.slideshare.net/deview/2d1elasticsearch
인덱스 구조 차이
- Elasticsearch
- Inverted-Index 구조로 데이터를 저장한다.
- 책의 색인처럼, 특정 단어가 포함된 문서를 저장하는 방식이다.
- RDBMS
- B-Tree 혹은, 그와 유사한 인덱스를 사용한다.
Elastic Stack
Elastic Stack은 Elasticsearch와 다음 세 가지 오픈 소스 프로젝트이다. Elasticsearch는 검색을 위해 단독으로 사용되기도 하지만, ELK 스택으로 사용된다.
Logstash, Kibana와 함께 사용 되면서 한동안 ELK Stack (Elasticsearch, Logstash, Kibana) 이라고 널리 알려지게 된 Elastic은 2013년에 Logstash, Kibana 프로젝트를 정식으로 흡수하여 한 지붕 아래에서 함께 개발을 해 나가고 있습니다. 2015년에는 회사명을 Elasticsearch 에서 Elastic으로 변경 하고, ELK Stack 대신 제품명을 Elastic Stack이라고 정식으로 명명하면서 모니터링, 클라우드 서비스, 머신러닝 등의 기능을 계속해서 개발, 확장 해 나가고 있다. 공식 문서에서 발췌한 내용
Logstash
- Elasticsearch로 보내는 데이터 형식을 변환하는 도구이다. ETL 툴의 Transform, Load 부분을 담당한다.
- 응용 프로그램 서버에서 Elasticsearch 서버로 로그를 전송할 때 적절한 데이터 형식으로 변경하는데 사용된다.
- 다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달한다.
Beats
- 데이터를 전송하는 쉬퍼이다. ETL의 Extract를 담당한다.
- 애플리케이션 서버에서 Logstash 또는 Elasticsearch로 데이터를 보낸다.
Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 받는다.
Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
- Elasticsearch의 문서를 시각화하는 소위 BI 도구이다.
Elasticsearch 아키텍처
Elasticsearch의 아키텍처는 다음 두 가지로 나뉜다.
- 논리적 개념(소프트웨어 관점에서의 용어)
- 물리적 개념(하드웨어 관점에서 용어)
논리적 개념
Elasticsearch의 논리적 개념의 전체 다이어그램은 다음과 같다.
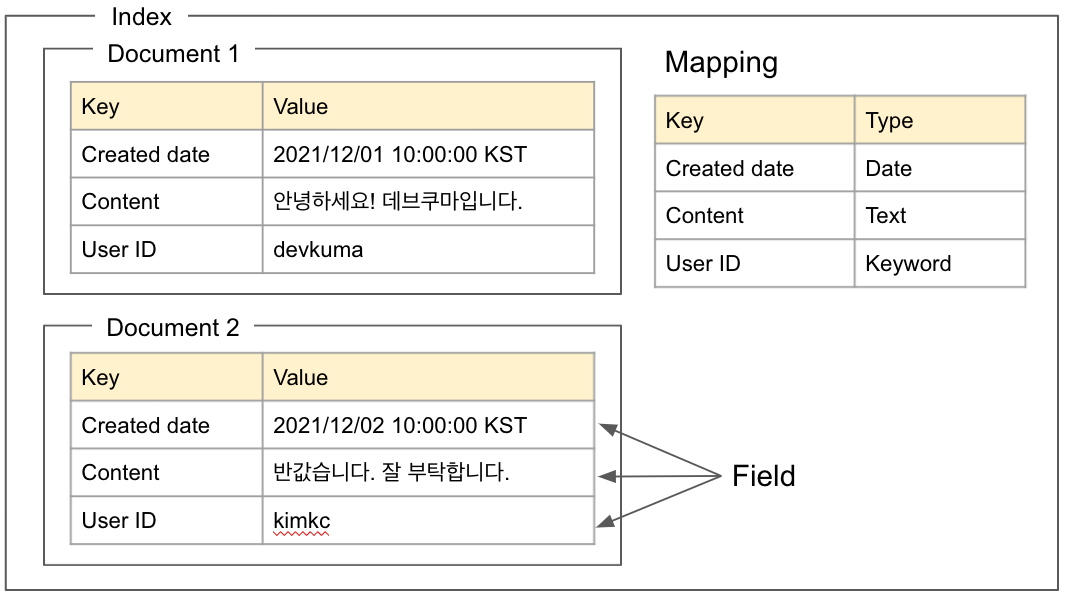
논리적 개념도
다음으로 각 용어에 대해 설명한다.
필드 (Field)
항목명(Key)과 값(Value)의 쌍이다. 파일 시스템에서 말하는 “파일의 내용"에 해당한다. 각각의 Key는 유형(Type)를 가진다.
- 문자열을 나타내는 text 유형
- 시간을 나타내는 date 유형 등
도큐먼트 (Document)
필드 집합을 도큐먼트라고 한다. 파일 시스템에서 말하는 “파일"에 해당한다. 도큐먼트는 JSON 객체이다.
색인 (Index)
문서 집합을 인덱스라고 한다. 파일 시스템에서 말하는 “폴더"에 해당한다. 도큐먼트를 인덱스에 저장할 때 역 인덱스를 만든다.
매핑 (Mapping)
각 필드의 Key 에 대한 값을 데이터의 유형 등을 정의하는 것이다. 매핑은 하나의 인덱스에 하나 존재한다.
위의 “논리적 개념도"에 설명된 매핑에서 “Content” 키는 “Text” 유형으로 정의되어 있기 때문에 “Content” 키의 값은 항상 Text 유형의 문자열이 된다.
물리적 개념
Elasticsearch의 물리적 개념의 전체 다이어그램은 다음과 같다. 또한 논리적인 개념의 인덱스와의 관계도 함께 표현되어 있다.
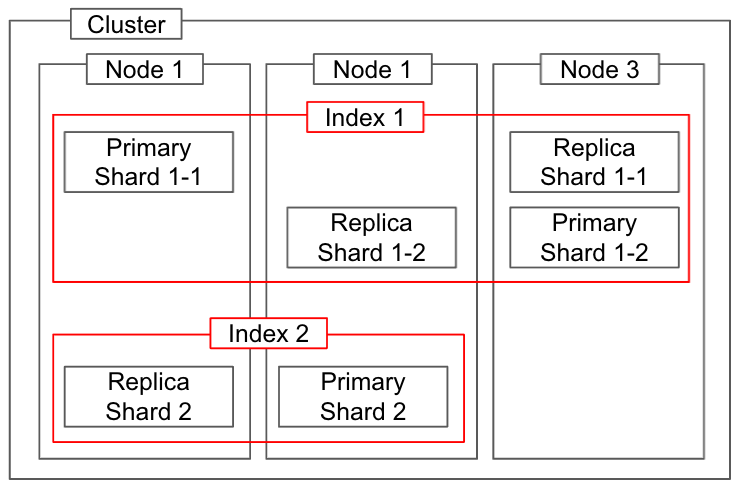
물리적 개념과 논리적 개념의 연관
노드 (Node)
노드는 Elasticsearch를 구성하는 하나의 단위 프로세스를 의미하며, 하나의 Elasticsearch 서버이다.
하나의 OS에 여러 개의 Elasticsearch 노드를 시작할 수 있다.
노드는 그 역할에 따라 다음의 4가지 종류의 속성이 존재하고 있고, 1개의 노드가 복수의 속성을 가지는 것도 가능하다.
- 마스터 노드 (Master Node)
- 클러스터 메타데이터 등을 관리하는 노드이다.
- 마스터 노드는 클러스터당 하나만 존재한다.
- 마스터 노드로 승격 가능한 노드는 Master-eligible 이라고 하는데, Master 노드는 아니다.
- 데이터 노드 (Data Node)
- 실제 데이터를 저장하는 노드이다.
- 요청 처리 (검색 및 집계 등) 수행한다.
- 요청을 다른 노드로 라우팅(예: 다른 노드가 샤드가 있는 경우)
- 인제스트 노드 (Ingest Node)
- 데이터 변환 및 가공을 수행하고 Data 노드에 저장한다.
- Logstash 와 동일한 역할을 한다.
- 코디네이트 노드 (Coordinating Node)
- 요청 라우팅(Data 노드도 가능) 역활을 한다.
- Data 노드에 라우팅 작업 부하를 가하고 싶지 않은 경우 라우팅 처리 전용 노드를 준비하기 위한 노드이다.
클러스터 (Cluseter)
Elasticsearch에서 클러스터는 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합이다. 클러스터에 검색 처리 요청을 던지면 각 노드에 검색 처리가 분산된다.
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수도 있다.
컴퓨터 클러스터(computer cluster)는 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을 말한다.
샤드(Shard)
논리적인 개념으로 소개한 “인덱스"의 데이터를 분할하여 노드에 보존한 데이터이다. 이렇게 하면 검색 프로세스를 각 노드에 분산할 수 있다. 샤드의 실체는 Lucene 인덱스 파일이다.
샤드에는 다음의 2가지 종류가 존재한다.
- 프라이머리 샤드(Primary shard)
- 데이터의 원본이다.
- 최초로 갱신 처리를 실시하는 샤드이다.
- 복제 샤드(Replica shard)
- 기본 샤드의 사본이다.
- 기본 샤드 업데이트가 끝나면 복제된다.
- 검색 부하의 분산이나 데이터의 백업으로서 사용된다.
샤드(Shard)와 레플리카(Replica)
샤드(Shard)와 레플리카(Replica)는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념이다.
- 샤드(Shard)
- 샤딩(sharding)은 데이터를 분산해서 저장하는 방법을 의미한다. 즉, 스케일 아웃을 위해 index를 여러 shard로 나눈다.
- 기본적으로 1개 이상 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 한다.
- 단일 노드에 저장할 수 있는 데이터양에는 제한이 있다.
- 클러스터에서 단일 인덱스로 데이터를 분할해 클러스터의 저장소와 메모리, 처리 용약을 저절히 활용할 수 있다.
- 기본적으로 샤드 갯수는 5개로 설정되며, 인덱스 생성 시점에 인덱스의 데이터를 나눌 샤드 갯수를 지정할 수 있다. 인덱스를 생성하고 나면 샤드 갯수는 변경할 수 없다.
- 레플리카(Replica)
- Replica는 또 다른 형태의 Shard라고 볼 수 있다.
- 장애 발생시에 문제없이 실행되도록 Replica(복사본)을 준비하여 장애를 해결할 수 있다. 즉, 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것이다. 따라서 Replica는 서로 다른 노드에 존재할 것을 권장한다.
- 인덱스의 각 샤드는 0개 이상의 레플리카를 가질 수 있다.
- 정리
- 엘라스틱의 가장 작은 단위는 노드이며, 이 노드는 데이터를 저장하고 쿼리를 수행한다.
- 노드들이 1개 이상 모여 클러스터를 구성한다.
- 노드의 내부는 샤드를 통해 더 효율적으로 데이터를 관리 할 수 있으며, 장애 상황이 발생할 것을 고려하여 레플리카를 추가 구성하여 장애 조치 및 데이터 가용성을 높을 수 있다.
- 고가용성(可用性, Availability)이란? 서버와 네트워크, 프로그램 등의 정보 시스템이 정상적으로 사용 가능한 정도를 말한다. 가동률과 비슷한 의미한다.