Apache HBase Architecture
Apache HBase Architecture
Apache HBase is a NoSQL database. NoSQL is a general expression indicating that a database is not an RDBMS whose primary access language is SQL. Apache HBase is a data store rather than a traditional database. HBase can scale linearly and modularly by adding commodity nodes to the cluster. If the number of nodes increases from 20 to 40, storage and capacity also increase at the same time in the HBase cluster.
HBase Cluster Architecture
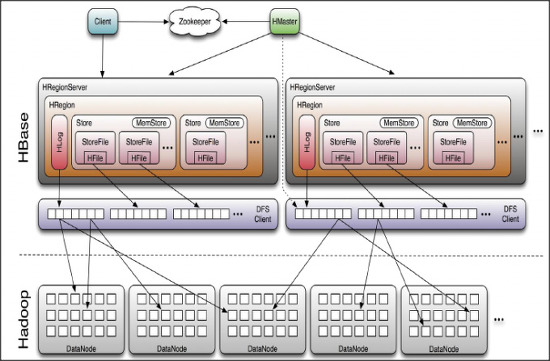
Apache HBase Components
HBase consists of two types of servers: Master servers and Region servers.
Its structure allows simple scale-out by adding Region servers.
HBase data is divided into units called Regions, and server types are separated according to how Regions are handled.
Master Server - HBase HMaster
Apache HBase HMaster is an important component of an HBase cluster that is responsible for monitoring RegionServers, handling failover, and managing region splits.
Data for each table is managed by RegionServers, and the entire cluster is managed by HMaster.
HMaster manages metadata that records which Region server stores each piece of HBase data (Region).
It assigns Regions to Region servers and detects failures in Region servers.
HMaster functions include the following.
- Monitors RegionServers.
- Coordinates Region servers.
- Manages Region startup.
- Handles RegionServer failover.
- Assigns or unassigns Regions.
- Monitors all Region servers in the cluster.
- Management functions.
- Table creation, deletion, and update.
- Handles metadata changes.
- Provides an interface for all metadata changes.
- Performs load balancing during idle time.
- HMaster provides a web user interface that shows information about the HBase cluster.
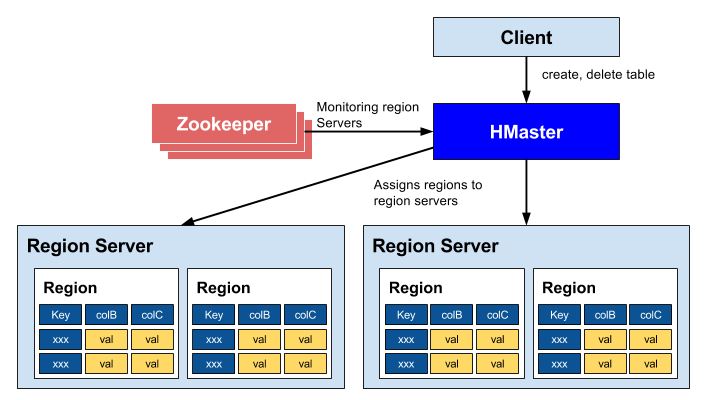
These tasks are handled by ZooKeeper, software that runs inside the Master server.
ZooKeeper is software used in many distributed applications besides HBase.
Region Server - HBase Region Server
RegionServer is responsible for storing the actual data assigned by the Master server. As in a Hadoop cluster, NameNode stores metadata and DataNode stores actual data. HBase is similar: the Master holds metadata, and RegionServers store actual data. RegionServer runs on DataNodes in a distributed cluster environment.
RegionServer performs the following tasks.
- Handles assigned regions (tables).
- Handles read and write requests made by clients.
- Flushes cache to HDFS.
- Is responsible for region split processing.
- Maintains HLog.
The client first queries the Master server, or more precisely ZooKeeper, to learn the location of the Region server that holds the target data (Region).
Then that Region server handles the client request.
A Region is always managed by a single Region server and maintains data consistency for reads and writes.
If a Region server goes down, the assigned Regions fail over to another Region server. This work is performed by the Master server.
However, until failover completes, clients cannot read from or write to the target Region.
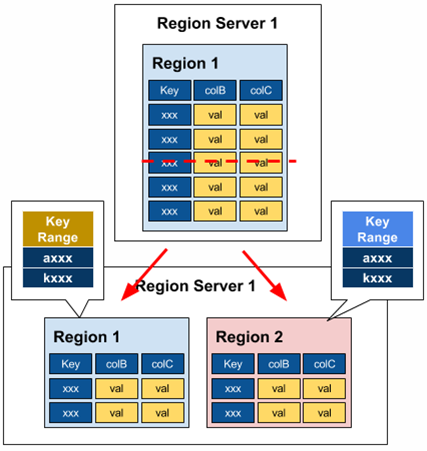
RegionServer Components
The following are the components of a RegionServer.
WAL (Write-Ahead Logging)
What is WAL? It is a standard method used by databases to guarantee data integrity. In systems that use WAL, changes are first recorded in the WAL before data is modified. These records make it possible to determine when a failure occurred, how far processing succeeded, and where subsequent work should resume.
Various database systems, including PostgreSQL, HBase, and MongoDB, use the WAL method.
Apache HBase WAL is an intermediate file also called an edit log file. When reading or modifying data in HBase, data is not written directly to disk but kept in memory for a period of time. If the system goes down, all data in memory may be lost. To overcome this problem, Apache HBase first records data in a Write-Ahead Logging file before recording it in memory.
HFile
HFile is the format for storing data in HBase. It belongs to a Column Family, and a Column Family can have multiple HFiles.
It is the actual file where row data is physically stored, and data is stored in key/value format.
When MemStore fills sufficiently, it creates a new HFile in HDFS and stores the data there.
This process is very fast because the structure minimizes random access.
Store
Store corresponds to a Column family for an HBase table. HFiles are stored here.
MemStore
MemStore resides in main memory and records current data operations. After data is stored in the WAL, key/value data is sorted and stored in the RegionServer memory store. This data is then stored in HFile as-is. There is one MemStore per Column Family.
Region
A Region is a table split that is divided based on keys and hosted by RegionServers.
Client
Clients can be written in Java or other languages and can connect through external APIs to the RegionServer that manages the actual row data. A client queries catalog tables to find a Region. Once the Region is found, the client connects directly to RegionServers, performs data operations, and caches data for fast lookups.
Catalog Tables
Catalog tables are used to maintain metadata for all RegionServers and Regions.
HBase has two types of catalog tables.
- -ROOT- This table contains information about the location of the META table.
- .META This table contains information about all Regions and their locations.
ZooKeeper
Apache ZooKeeper acts like the coordinator for HBase. HBase uses ZooKeeper to manage the state of servers that make up the cluster. It provides services such as maintaining configuration information, naming, distributed synchronization, and server error notification. Clients communicate with region servers through ZooKeeper.
Apache ZooKeeper is a high-performance centralized coordination service system for distributed applications that provides distributed synchronization and group services to HBase. Despite cluster coordination, it lets users focus on application logic. It also provides APIs that allow users to interact with the Master server.
The Apache ZooKeeper API provides consistency, ordering, and durability, and also provides synchronization and concurrency for distributed cluster systems.
HBase Data Write/Read Process
This section explains how HBase reads and writes data.
HBase Data Writes
When storing data in HBase, the data is stored in two places: the WAL (Write Ahead Log) and the Region server’s MemStore.
Using these two locations, the write process is considered complete when changes have occurred in both the WAL and MemStore.
When a data load request arrives in HBase, the appropriate Region server is found first. After the Region server is found, a commit log is added and the data is added to the in-memory MemStore.
Data stored in MemStore is flushed to disk as an HFile when it becomes full according to configured values. Memory is cleared, the server waits for the next request, and a corresponding record is also written to the WAL.
MemStore flush occurs when the value exceeds hbase.hregion.memstore.flush.size; the unit is bytes and the setting is 134217728 (128 MB).
MemStore is a memory area of the Region server and acts like a cache.
When a certain amount of data accumulates in MemStore, the data is exported to disk as an HFile and persisted.
However, data before it is exported to HFile is stored in server memory (MemStore), so it disappears if the server goes down.
Therefore, HBase writes a log called HLog when writing data, and if the server goes down, it can recover data based on HLog.
HBase Data Reads
The process of reading data from HBase is similar to the write process described above.
When a request enters HBase, MemStore is checked first. If the desired data is found in MemStore, that data is returned. Otherwise, HBase searches from the most recently flushed file to older files until it finds suitable data that satisfies the query or there are no more flushed files.