RAG(Retrieval-Augmented Generation)
大規模言語モデル(LLM)が答えを作るとき、自身の知識だけを使うのではなく、外部データから関連情報を探して活用する方式である。
RAG(Retrieval-Augmented Generation)の概念
- RAG = 検索(Retrieval)+ 生成(Generation)
- LLM(大規模言語モデル)が自分の内部知識だけで答えを生成するのではなく、外部データベース(例: 文書、ベクトルDB、Wiki、社内資料など)から関連情報を検索し、その結果を基に回答を生成する。
つまり、単に「モデルが知っていること」だけを使うのではなく、「必要なときに外部で調べて答える」賢いアシスタントのような概念である。
なぜ必要なのか?
- LLMの知識限界を克服
- LLMは学習時点以降の最新情報を知らない。
- たとえば、GPTのようなモデルは学習時点以降の最新情報を知らない。
- RAGを使うと、DBやWebから取得した資料を活用できる。
- 幻覚(Hallucination)を減らす
- LLMは知らないことを作り上げる場合がある。
- 外部の根拠資料を活用すると、回答の信頼性を高められる。
- 根拠のない回答ではなく、実際の文書やDBを根拠に回答できる。
- カスタム知識の活用
- 企業内部文書、報告書、顧客FAQ、論文、コードベースなどの専用データをLLMが使用できる。
- 社内の機密文書を学習させなくても活用できる。
RAGの動作構造
- クエリ(Query)入力
- ユーザーが質問を入力する。
- 検索(Retrieval)段階
- 質問をベクトル化(埋め込み)した後、ベクトルデータベースから関連文書を検索する。
- 代表的なDB: Pinecone、Weaviate、Milvus、FAISSなど。
- 生成(Generation)段階
- LLMが検索された文書を参照して回答を生成し、一緒に伝達する。
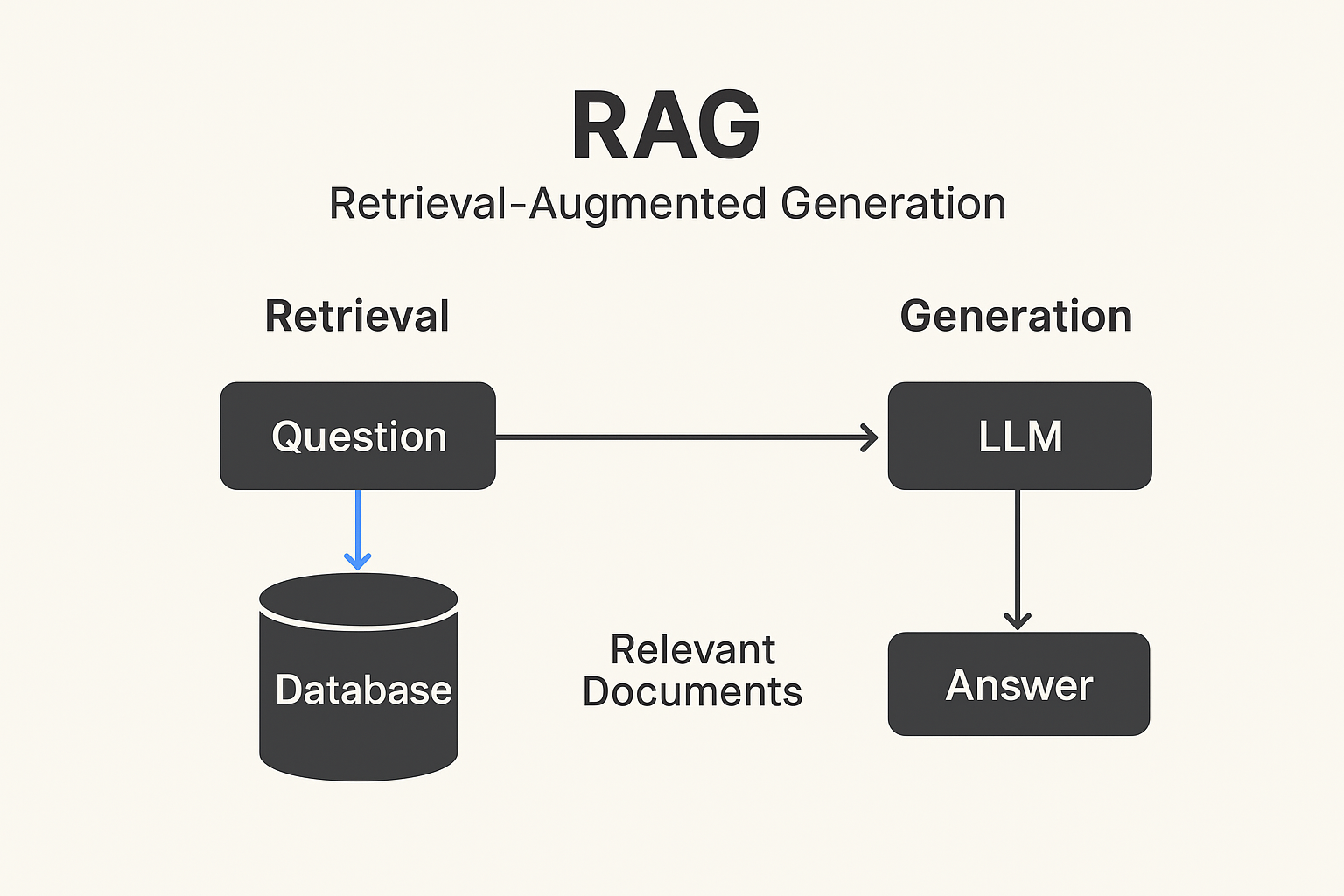
つまり、「探して -> 参照して -> 回答する」構造である。
例
たとえば、「当社の2023年売上はいくら?」という質問が入った場合:
- LLM単独: 「2023年の売上は1億ドルです。」(根拠なし、誤っている可能性あり)
- RAG活用: 会社内部の財務報告書を検索 -> 関連データを取得 -> 「2023年の当社売上は9,200億ウォンで、前年比8%成長しました。」(根拠のある回答)
比喩で理解する
- LLM単独: 記憶力のよい人。ただし最新情報は知らない場合がある。
- RAG使用: 記憶力のよい人が辞書や検索エンジンを参照して回答すること。
RAGとFine-tuningの比較
- Fine-tuning: モデル自体を追加学習し、新しい知識を「内在化」する
- RAG: モデルはそのままにし、外部資料を検索して活用する
| 方法 | 利点 | 欠点 |
|---|---|---|
| Fine-tuning | 応答が速く自然 | データを更新するたびに再学習が必要 |
| RAG | 常に最新/カスタム情報を反映可能、素早く構築可能 | 検索品質によって回答品質が左右される |
実務では、RAGに必要に応じて一部Fine-tuningを組み合わせて使うことが多い。
RAG実装に使われる技術スタック
- 埋め込みモデル: OpenAI Embeddings、Sentence-BERTなど
- ベクトルDB: Pinecone、Weaviate、Milvus、FAISS
- LLM: GPT、Claude、LLaMA、Geminiなど
- フレームワーク: LangChain、LlamaIndex、Haystack
まとめ
- RAGはLLMが検索システムを併用し、信頼できる最新情報を反映した回答を生成する方式である。
- つまり、知識の拡張と信頼性補強のための中核技術である。