RAG(Retrieval-Augmented Generation)
대규모 언어 모델(LLM)이 답을 만들 때, 자체 지식만 사용하는 것이 아니라 외부 데이터에서 관련 정보를 찾아와 활용하는 방식이다.
RAG (Retrieval-Augmented Generation) 개념
- RAG = 검색(Retrieval) + 생성(Generation)
- LLM(대규모 언어모델)이 자기 내부 지식만으로 답을 생성하는 것이 아니라, 외부 데이터베이스(예: 문서, 벡터 DB, 위키, 사내 자료 등)에서 관련 정보를 검색한 후, 그 결과를 바탕으로 답변을 생성한다.
즉, 단순히 “모델이 아는 것"만 쓰는 게 아니라, “필요할 때 외부에서 찾아보고 답하는” 똑똑한 비서 같은 개념이다
왜 필요한가?
- LLM의 지식 한계 극복
- LLM은 학습 시점 이후의 최신 정보를 알지 못한다.
- 예를 들어, GPT 같은 모델은 학습 시점 이후의 최신 정보는 모른다.
- RAG를 사용하면 DB/웹에서 찾아온 자료를 활용 가능하게 된다.
- 환각(Hallucination) 줄이기
- LLM은 모르는 것도 지어낼 때가 있다.
- 외부 근거 자료를 활용하면 답변 신뢰도를 높일 수 있다.
- 근거 없는 답변 대신, 실제 문서/DB를 근거로 답변 가능하다.
- 맞춤형 지식 활용
- 기업 내부 문서, 보고서, 고객 FAQ, 논문, 코드베이스 등의 전용 데이터를 LLM이 사용할 수 있음.
- 사내 비밀 문서를 학습시키지 않고도 활용 가능하다.
RAG의 동작 구조
- 질의(Query) 입력
- 사용자가 질문을 입력한다.
- 검색(Retrieval) 단계
- 질문을 벡터화(임베딩) 후, 벡터 데이터베이스에서 관련 문서를 검색한다.
- 대표 DB: Pinecone, Weaviate, Milvus, FAISS 등.
- 생성(Generation) 단계
- LLM이 검색된 문서를 참고하여 답변을 생성하여 함께 전달한다.
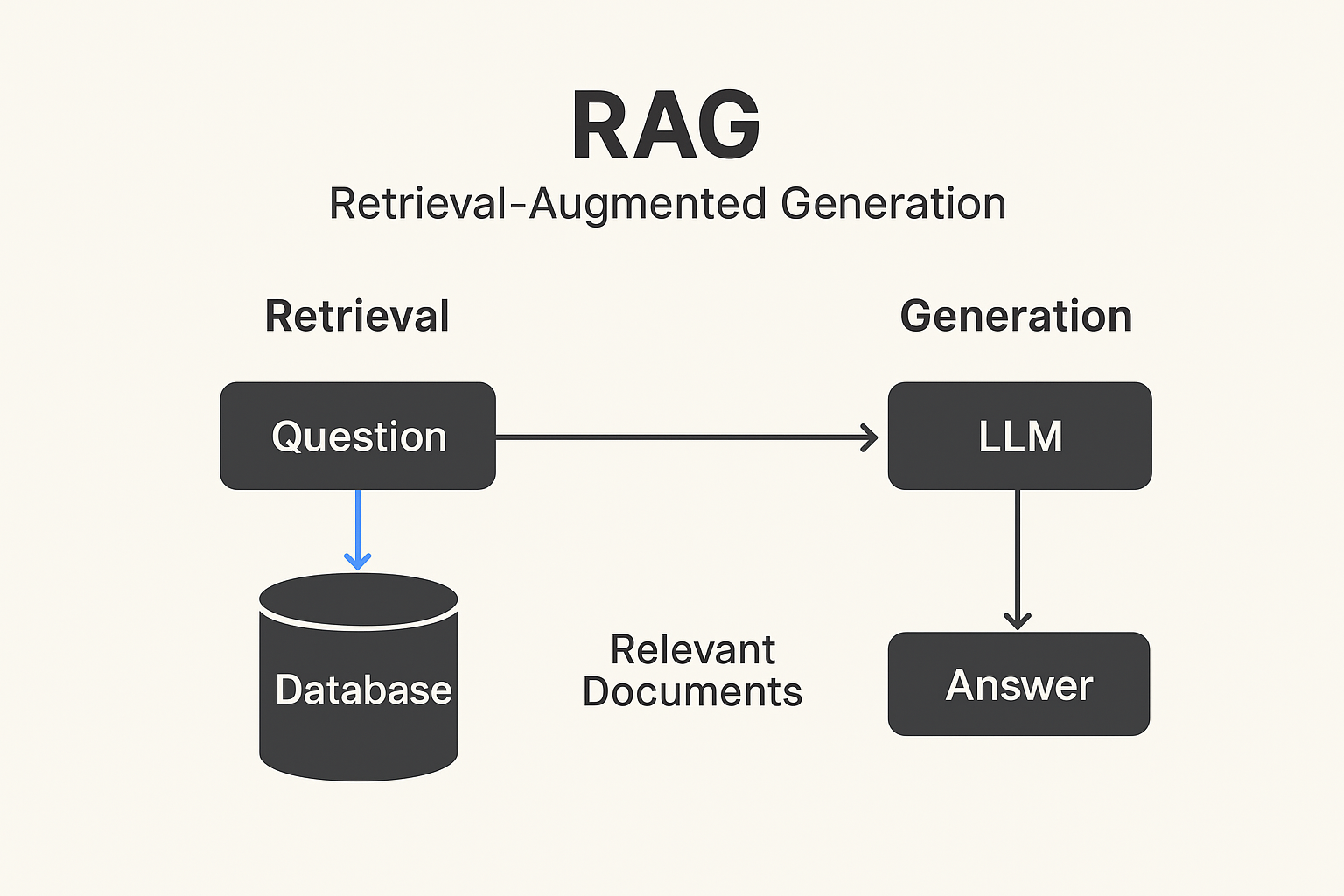
즉, “찾아서 → 참고해서 → 답변하는” 구조이다.
예시
예를 들어, “우리 회사의 2023년 매출은 얼마야?“라는 질문이 들어오면:
- LLM 단독: “2023년 매출은 1억 달러입니다.” (근거 없음, 틀릴 수 있음)
- RAG 활용: 회사 내부 재무 보고서를 검색 → 관련 데이터 가져옴 → “2023년 당사의 매출은 9,200억 원으로, 전년 대비 8% 성장했습니다.” (근거 있는 답변)
비유로 이해하기
- LLM 단독: 기억력 좋은 사람, 하지만 최신 정보는 모를 수 있다.
- RAG 사용: 기억력 좋은 사람이 사전·검색 엔진을 참고해서 답변하는 것이다.
RAG와 Fine-tuning의 비교
- Fine-tuning: 모델 자체를 추가 학습 → 새로운 지식을 “내재화”
- RAG: 모델은 그대로 두고, 외부 자료를 검색해서 활용
| 방법 | 장점 | 단점 |
|---|---|---|
| Fine-tuning | 응답이 빠르고 자연스러움 | 데이터 업데이트할 때마다 재학습 필요 |
| RAG | 항상 최신/맞춤 정보 반영 가능, 빠른 구축 | 검색 품질에 따라 답변 품질 좌우 |
실무에서는 RAG + 필요시 일부 Fine-tuning을 섞어서 많이 사용된다.
RAG 구현에 쓰이는 기술 스택
- 임베딩 모델: OpenAI Embeddings, Sentence-BERT 등
- 벡터 DB: Pinecone, Weaviate, Milvus, FAISS
- LLM: GPT, Claude, LLaMA, Gemini 등
- 프레임워크: LangChain, LlamaIndex, Haystack
정리
- RAG는 LLM이 검색 시스템을 함께 사용해, 신뢰할 수 있고 최신 정보를 반영하는 답변을 생성하는 방식이다.
- 즉, 지식의 확장 & 신뢰성 보강을 위한 핵심 기술이다.